如何识别带有彩色背景图像的文本?
我是opencv和python以及tesseract的新手。现在,我正在创建一个脚本,该脚本将识别图像中的文本。我的代码在黑色文本和白色背景上或在黑色背景的白色文本上都能正常工作,但在彩色图像中却不能。例如,带有蓝色背景的白色文本,例如按钮。字体也会影响到吗?在这种情况下,我会找到重新启动文本(按钮)
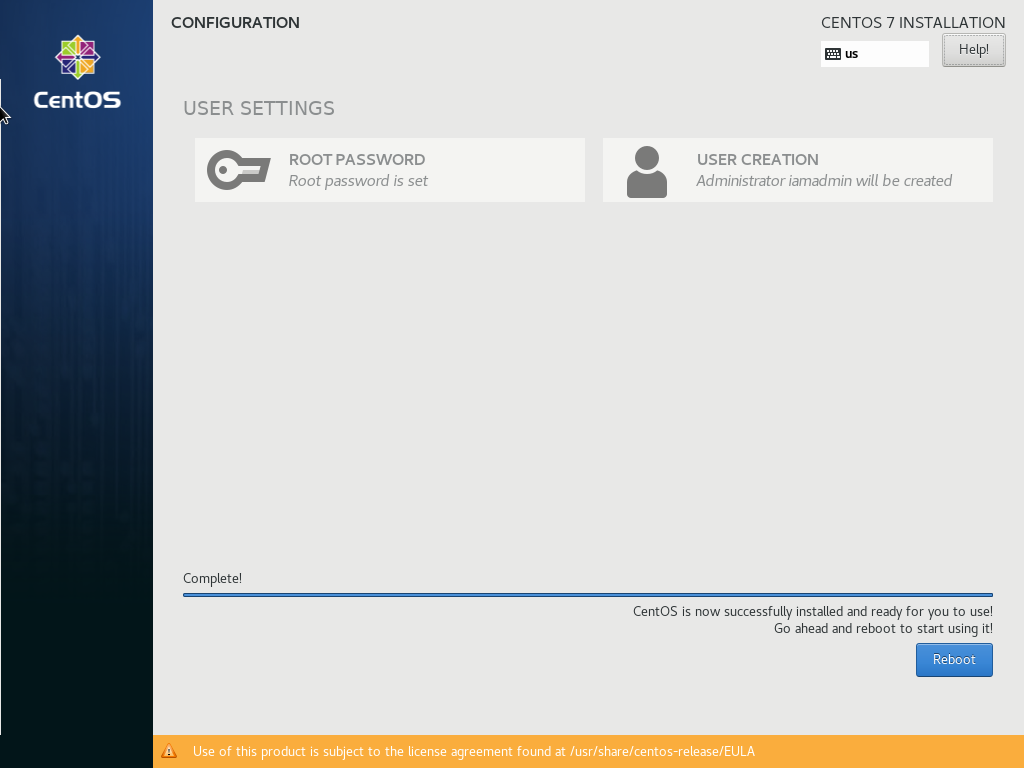
这是示例图像
我在通过opencv进行图像预处理时尝试了一堆代码和方法,但未能获得结果。图像二值化,降噪,灰度但是不好。
这是示例代码:
from PIL import Image
import pytesseract
import cv2
import numpy as np
# image = Image.open('image.png')
# image = image.convert('-1')
# image.save('new.png')
filename = 'image.png'
outputname = 'converted.png'
# grayscale -----------------------------------------------------
image = cv2.imread(filename)
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imwrite(outputname,gray_image)
# binarize -----------------------------------------------------
im_gray = cv2.imread(outputname, cv2.IMREAD_GRAYSCALE)
(thresh, im_bw) = cv2.threshold(im_gray, 128, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
cv2.imwrite(outputname, im_bw)
# remove noise -----------------------------------------------------
im = cv2.imread(outputname)
morph = im.copy()
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 1))
morph = cv2.morphologyEx(morph, cv2.MORPH_CLOSE, kernel)
morph = cv2.morphologyEx(morph, cv2.MORPH_OPEN, kernel)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))
image_channels = np.split(np.asarray(morph), 3, axis=2)
channel_height, channel_width, _ = image_channels[0].shape
# apply Otsu threshold to each channel
for i in range(0, 3):
_, image_channels[i] = cv2.threshold(image_channels[i], 0, 255, cv2.THRESH_OTSU | cv2.THRESH_BINARY)
image_channels[i] = np.reshape(image_channels[i], newshape=(channel_height, channel_width, 1))
# merge the channels
image_channels = np.concatenate((image_channels[0], image_channels[1], image_channels[2]), axis=2)
# save the denoised image
cv2.imwrite(outputname, image_channels)
image = Image.open(outputname)
data_string = pytesseract.image_to_data(image, config='--oem 1')
data_string = data_string.encode('utf-8')
open('image.tsv', 'wb').write(data_string)
通过运行代码,我得到以下图像:

和带有TSV参数的tesseract的结果:
level page_num block_num par_num line_num word_num left top width height conf text
1 1 0 0 0 0 0 0 1024 768 -1
2 1 1 0 0 0 2 13 1002 624 -1
3 1 1 1 0 0 2 13 1002 624 -1
4 1 1 1 1 0 172 13 832 22 -1
5 1 1 1 1 1 172 13 127 22 84 CONFIGURATION
5 1 1 1 1 2 822 17 59 11 92 CENTOS
5 1 1 1 1 3 887 17 7 11 95 7
5 1 1 1 1 4 900 17 104 11 95 INSTALLATION
4 1 1 1 2 0 86 29 900 51 -1
5 1 1 1 2 1 86 35 15 45 12 4
5 1 1 1 2 2 825 30 27 40 50 Bes
5 1 1 1 2 3 952 29 34 40 51 Hel
4 1 1 1 3 0 34 91 87 17 -1
5 1 1 1 3 1 34 91 87 17 90 CentOS
4 1 1 1 4 0 2 116 9 8 -1
5 1 1 1 4 1 2 116 9 8 0 ‘
4 1 1 1 5 0 184 573 57 14 -1
5 1 1 1 5 1 184 573 57 14 90 Complete!
4 1 1 1 6 0 634 606 358 14 -1
5 1 1 1 6 1 634 606 43 10 89 CentOS
5 1 1 1 6 2 683 609 7 7 96 is
5 1 1 1 6 3 696 609 24 7 96 now
5 1 1 1 6 4 725 606 67 14 96 successfully
5 1 1 1 6 5 797 606 45 10 96 installed
5 1 1 1 6 6 848 606 18 10 96 and
5 1 1 1 6 7 872 599 29 25 96 ready
5 1 1 1 6 8 906 599 15 25 95 for
5 1 1 1 6 9 928 609 20 11 96 you
5 1 1 1 6 10 953 608 12 8 96 to
5 1 1 1 6 11 971 606 21 10 95 use!
4 1 1 1 7 0 775 623 217 14 -1
5 1 1 1 7 1 775 623 15 10 95 Go
5 1 1 1 7 2 796 623 31 10 96 ahead
5 1 1 1 7 3 833 623 18 10 96 and
5 1 1 1 7 4 857 623 38 10 96 reboot
5 1 1 1 7 5 900 625 12 8 96 to
5 1 1 1 7 6 918 625 25 8 95 start
5 1 1 1 7 7 949 626 28 11 96 using
5 1 1 1 7 8 983 623 9 10 93 it!
如您所见,“重新启动”文本未显示。也许是因为字体?还是颜色?
1 个答案:
答案 0 :(得分:1)
这是两种不同的方法:
1。传统图像处理和轮廓过滤
主要思想是提取ROI,然后应用Tesseract OCR。
- 将图像转换为灰度和高斯模糊
- 自适应阈值
- 找到轮廓
- 遍历轮廓并使用轮廓逼近和面积过滤
- 提取投资回报率
一旦我们从自适应阈值获得二值图像,我们就会使用cv2.arcLength()和cv2.approxPolyDP()通过轮廓逼近找到轮廓并进行滤波。如果轮廓有四个点,则假定它是矩形或正方形。另外,我们使用轮廓区域应用第二个过滤器,以确保隔离正确的ROI。这是提取的投资回报率

import cv2
image = cv2.imread('1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (3,3), 0)
thresh = cv2.adaptiveThreshold(blur,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV,9,3)
cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
ROI_number = 0
for c in cnts:
area = cv2.contourArea(c)
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.05 * peri, True)
if len(approx) == 4 and area > 2200:
x,y,w,h = cv2.boundingRect(approx)
ROI = image[y:y+h, x:x+w]
cv2.imwrite('ROI_{}.png'.format(ROI_number), ROI)
ROI_number += 1
现在,我们可以将其放入Pytesseract。注意Pytesseract要求图像文本为黑色,而背景为白色,因此我们首先要进行一些预处理。这是Pytesseract的预处理图像和结果

重启
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
image = cv2.imread('ROI.png',0)
thresh = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
result = 255 - thresh
data = pytesseract.image_to_string(result, lang='eng',config='--psm 10 ')
print(data)
cv2.imshow('thresh', thresh)
cv2.imshow('result', result)
cv2.waitKey()
通常,您还需要使用形态转换来平滑图像,但在这种情况下,文本足够好
2。颜色阈值
第二种方法是使用具有较高和较低HSV阈值的颜色阈值来创建可提取ROI的蒙版。请看here以获取完整示例。一旦提取了ROI,我们将按照相同的步骤对图像进行预处理,然后再将其投入Pytesseract
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?