Nginx在上游响应日志中显示2种不同的状态
我正在kubernetes集群中运行一个nginx-ingress控制器,并且我的请求的日志语句之一如下:
upstream_response_length: 0, 840
upstream_response_time: 60.000, 0.760
upstream_status: 504, 200
我不太明白这是什么意思? Nginx的响应超时等于60秒,并尝试在此之后再请求一个时间(成功)并记录两个请求?
P.S。配置日志格式:
log-format-upstream: >-
{
...
"upstream_status": "$upstream_status",
"upstream_response_length": "$upstream_response_length",
"upstream_response_time": "$upstream_response_time",
...
}
1 个答案:
答案 0 :(得分:2)
根据split_upstream_var的ingress-nginx方法,它是splits nginx health checks的结果。
由于nginx可以包含several upstreams,因此您的日志可以这样解释:
- 第一个上游已死(504)
upstream_response_length: 0 // responce from dead upstream has zero length
upstream_response_time: 60.000 // nginx dropped connection after 60sec
upstream_status: 504 // responce code, upstream doesn't answer
- 第二部上游作品(200)
upstream_response_length: 840 // healthy upstream returned 840b
upstream_response_time: 0.760 // healthy upstream responced in 0.760
upstream_status: 200 // responce code, upstream is ok
P.S。 JFYI,这是一个很酷的HTTP标头状态图
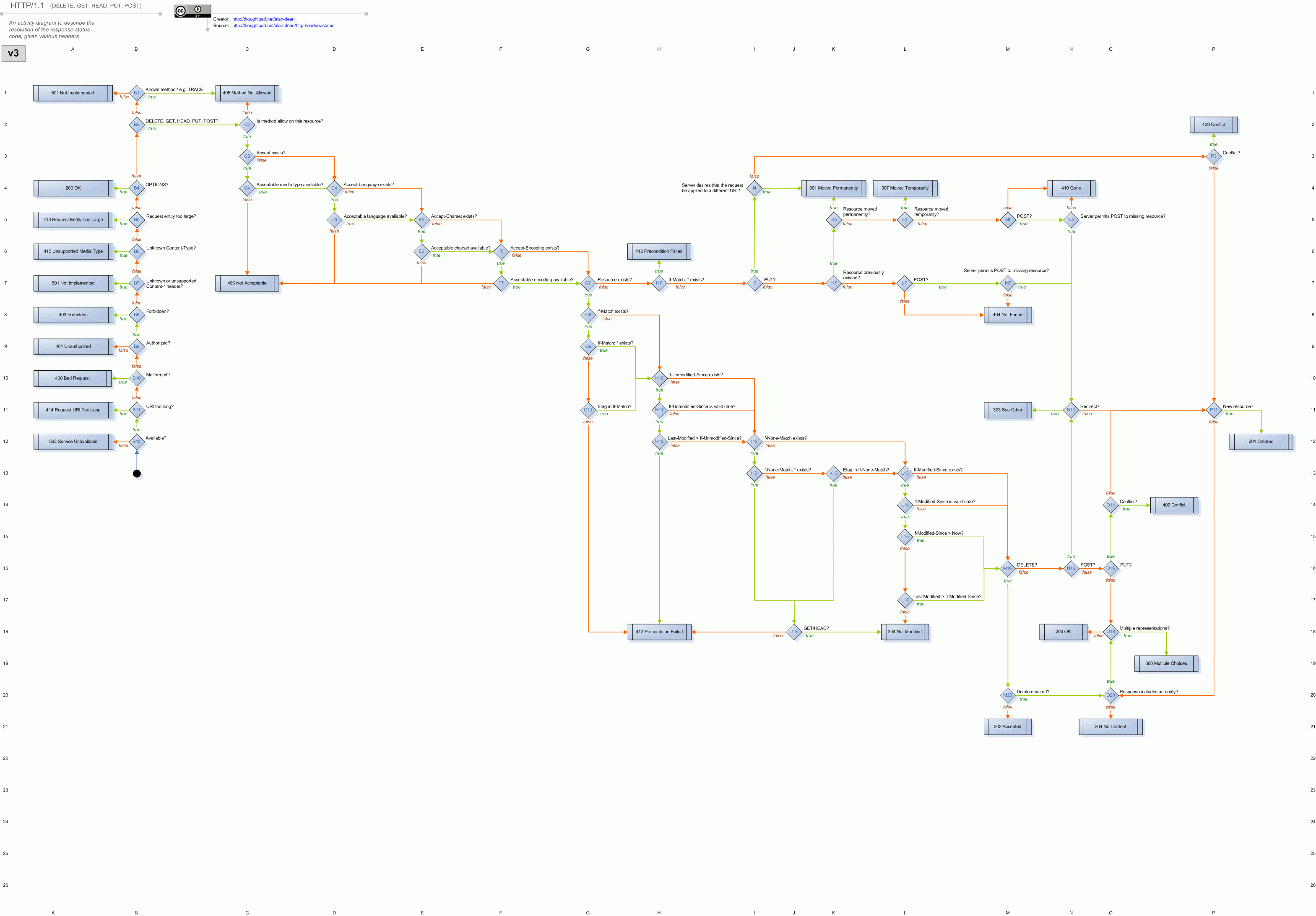
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?