Google CloudML:“完成拆解培训计划”后作业失败,即使培训尚未完成
我正在尝试使用Google Cloud Platform(GCP)训练模型。
我选择了standard-1规模层(使用基本层提供了内存异常,我认为这是由于数据大小(2.6GB)所致),但是在日志“ 完成后,我的工作失败了”拆除培训计划”,即使该计划仍在将数据从云存储下载到VM中。
它没有提供有关错误原因的任何回溯。
我将数据存储在Cloud Storage中并使其可用,我使用os.system('gsutil -m cp -r location_of_data_in_cloud_storage os.getcwd()')将数据存储在分配的VM中,以便程序可以直接访问。然后,将这些数据通过生成器加载到model.fit_generator()方法中。
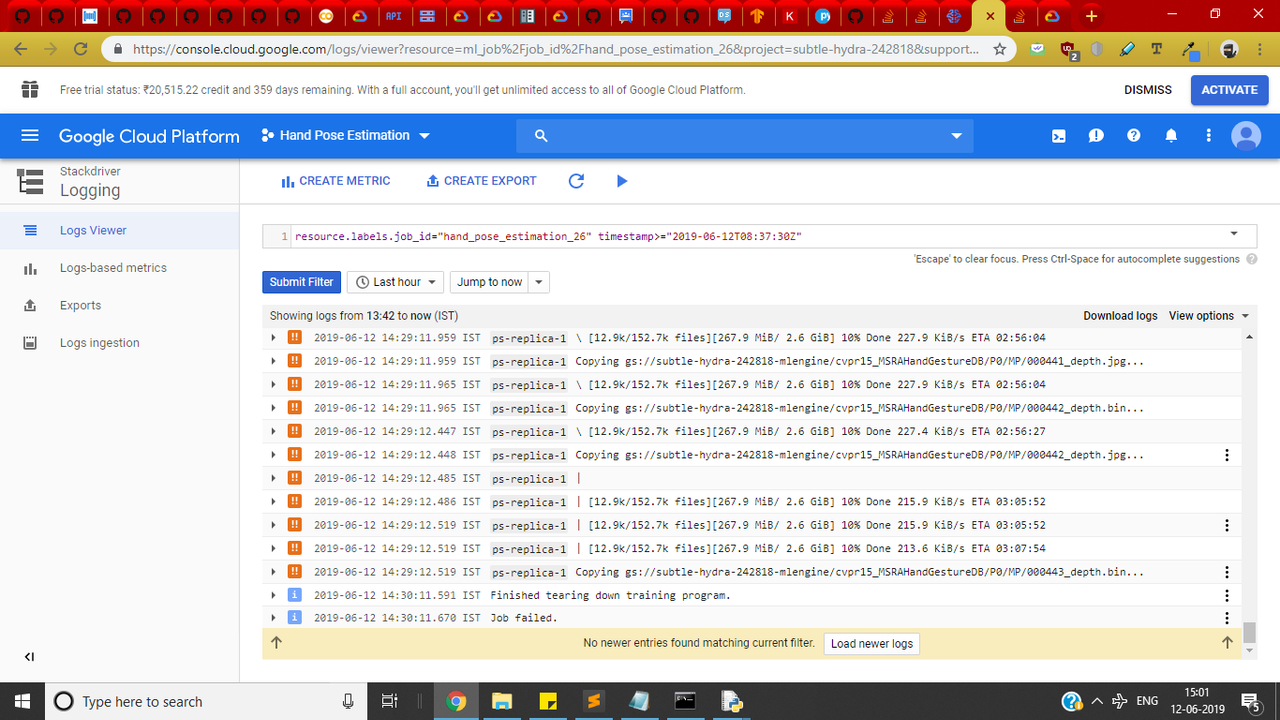
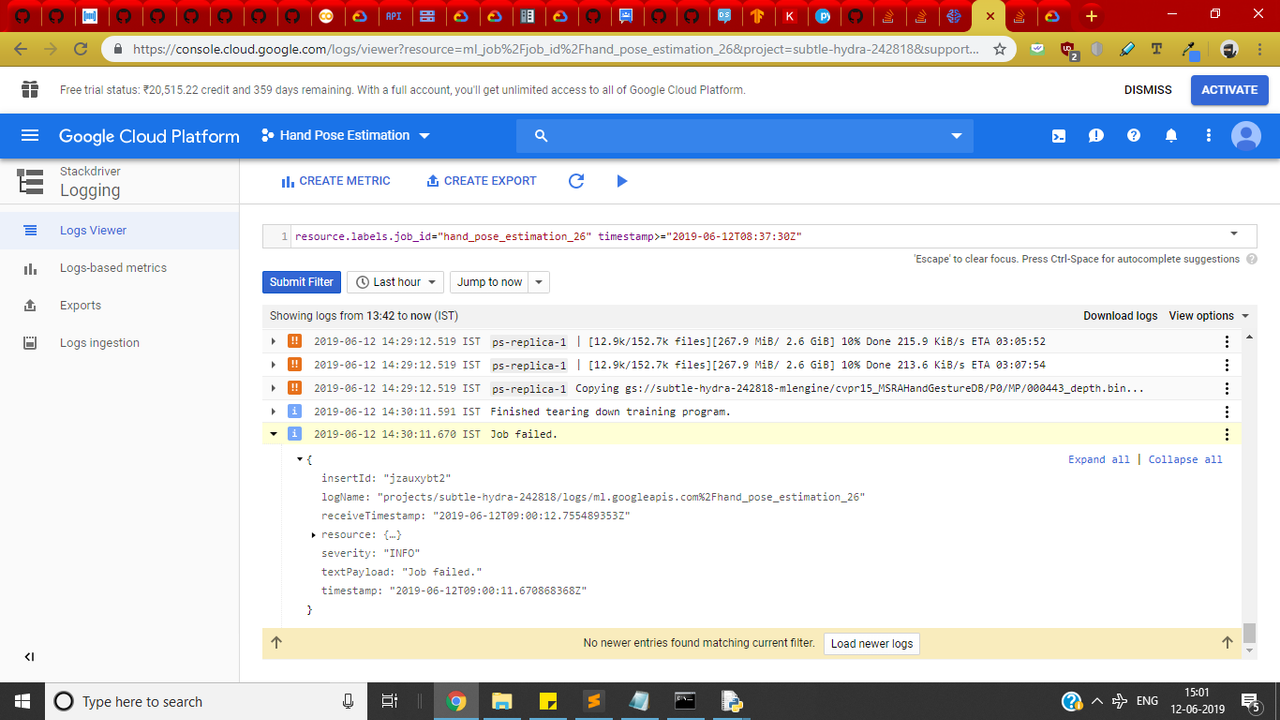
可以看出2.6GB的数据尚未完全下载,但是在此之前作业失败了!
1 个答案:
答案 0 :(得分:0)
以后会偶然发现此问题的其他任何人(可能是我;)),都是由于计算机无法处理计算而发生上述问题,因此我不得不使用standard_p100扩展计算机GCP中的basic比例等级解决了该问题!
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?