如何使用ANTLR4突出显示QScintilla?
我正在尝试学习ANTLR4,而我的第一个实验已经遇到了一些问题。
这里的目标是学习如何使用ANTLR来突出显示QScintilla组件的语法。为了进行一些练习,我决定要学习如何正确突出显示*.ini文件。
首先,要运行mcve,您需要:
- 下载antlr4并确保其正常工作,请阅读主站点上的说明
- 安装python antlr运行时,只需执行:
pip install antlr4-python3-runtime -
生成
ini.g4的词法分析器/解析器:grammar ini; start : section (option)*; section : '[' STRING ']'; option : STRING '=' STRING; COMMENT : ';' ~[\r\n]*; STRING : [a-zA-Z0-9]+; WS : [ \t\n\r]+;
通过运行antlr ini.g4 -Dlanguage=Python3 -o ini
-
最后,保存
main.py:import textwrap from PyQt5.Qt import * from PyQt5.Qsci import QsciScintilla, QsciLexerCustom from antlr4 import * from ini.iniLexer import iniLexer from ini.iniParser import iniParser class QsciIniLexer(QsciLexerCustom): def __init__(self, parent=None): super().__init__(parent=parent) lst = [ {'bold': False, 'foreground': '#f92472', 'italic': False}, # 0 - deeppink {'bold': False, 'foreground': '#e7db74', 'italic': False}, # 1 - khaki (yellowish) {'bold': False, 'foreground': '#74705d', 'italic': False}, # 2 - dimgray {'bold': False, 'foreground': '#f8f8f2', 'italic': False}, # 3 - whitesmoke ] style = { "T__0": lst[3], "T__1": lst[3], "T__2": lst[3], "COMMENT": lst[2], "STRING": lst[0], "WS": lst[3], } for token in iniLexer.ruleNames: token_style = style[token] foreground = token_style.get("foreground", None) background = token_style.get("background", None) bold = token_style.get("bold", None) italic = token_style.get("italic", None) underline = token_style.get("underline", None) index = getattr(iniLexer, token) if foreground: self.setColor(QColor(foreground), index) if background: self.setPaper(QColor(background), index) def defaultPaper(self, style): return QColor("#272822") def language(self): return self.lexer.grammarFileName def styleText(self, start, end): view = self.editor() code = view.text() lexer = iniLexer(InputStream(code)) stream = CommonTokenStream(lexer) parser = iniParser(stream) tree = parser.start() print('parsing'.center(80, '-')) print(tree.toStringTree(recog=parser)) lexer.reset() self.startStyling(0) print('lexing'.center(80, '-')) while True: t = lexer.nextToken() print(lexer.ruleNames[t.type-1], repr(t.text)) if t.type != -1: len_value = len(t.text) self.setStyling(len_value, t.type) else: break def description(self, style_nr): return str(style_nr) if __name__ == '__main__': app = QApplication([]) v = QsciScintilla() lexer = QsciIniLexer(v) v.setLexer(lexer) v.setText(textwrap.dedent("""\ ; Comment outside [section s1] ; Comment inside a = 1 b = 2 [section s2] c = 3 ; Comment right side d = e """)) v.show() app.exec_()
并运行它,如果一切顺利,您应该得到以下结果:
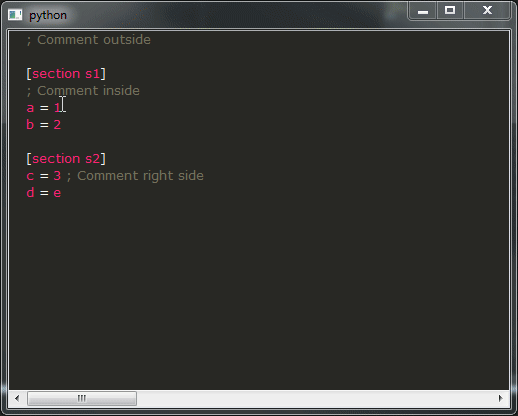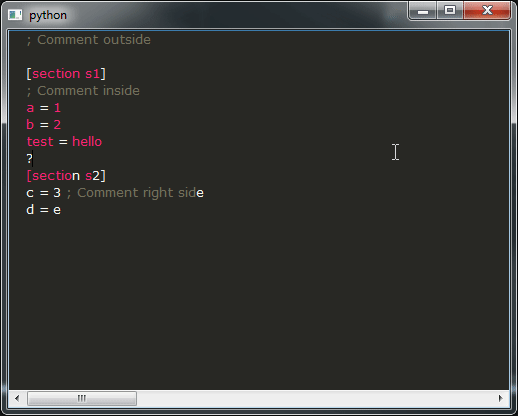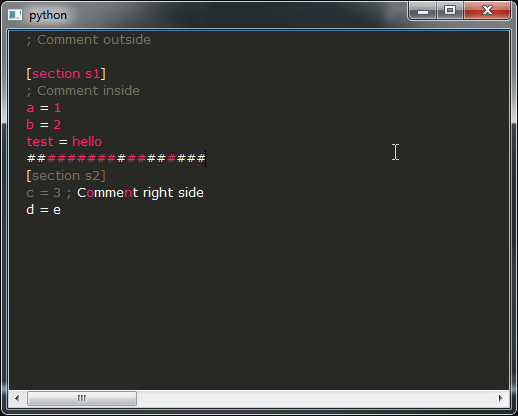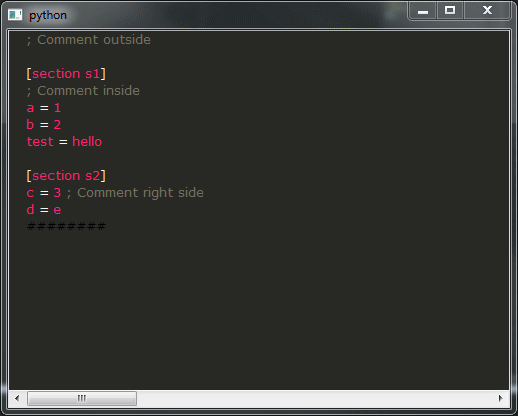
这是我的问题:
- 如您所见,该演示的结果远非可用,您绝对不希望这样做,这确实令人不安。相反,您想要的行为与那里的所有IDE相似。不幸的是,我不知道该如何实现,您将如何修改提供此类行为的代码段?
- 现在,我试图模仿与下面的快照类似的突出显示:

您可以在该屏幕截图上看到,变量赋值(variable = deeppink和values = yellowish)的突出显示是不同的,但是我不知道该如何实现,我尝试使用这种稍微修改的语法:
grammar ini;
start : section (option)*;
section : '[' STRING ']';
option : VARIABLE '=' VALUE;
COMMENT : ';' ~[\r\n]*;
VARIABLE : [a-zA-Z0-9]+;
VALUE : [a-zA-Z0-9]+;
WS : [ \t\n\r]+;
,然后将样式更改为:
style = {
"T__0": lst[3],
"T__1": lst[3],
"T__2": lst[3],
"COMMENT": lst[2],
"VARIABLE": lst[0],
"VALUE": lst[1],
"WS": lst[3],
}
但是,如果您查看词法输出,您会发现VARIABLE和VALUES之间没有区别,因为ANTLR语法中的顺序优先。所以我的问题是,如何修改语法/代码片段以实现这种视觉效果?
3 个答案:
答案 0 :(得分:1)
问题在于,词法分析器必须是上下文相关的:=左侧的所有内容都必须是变量,而其右侧必须是值。您可以使用ANTLR的lexical modes来做到这一点。首先,将连续的非空间归类为变量,然后遇到=时,便进入了价值模式。在值模式下,每当遇到换行符时,您就会退出此模式。
请注意,词法模式仅适用于词法分析器语法,不适用于您现在拥有的组合语法。另外,对于语法高亮显示,您可能只需要词法分析器。
这是一个如何工作的快速演示(将其粘贴在名为IniLexer.g4的文件中):
lexer grammar IniLexer;
SECTION
: '[' ~[\]]+ ']'
;
COMMENT
: ';' ~[\r\n]*
;
ASSIGN
: '=' -> pushMode(VALUE_MODE)
;
KEY
: ~[ \t\r\n]+
;
SPACES
: [ \t\r\n]+ -> skip
;
UNRECOGNIZED
: .
;
mode VALUE_MODE;
VALUE_MODE_SPACES
: [ \t]+ -> skip
;
VALUE
: ~[ \t\r\n]+
;
VALUE_MODE_COMMENT
: ';' ~[\r\n]* -> type(COMMENT)
;
VALUE_MODE_NL
: [\r\n]+ -> skip, popMode
;
如果您现在运行以下脚本:
source = """
; Comment outside
[section s1]
; Comment inside
a = 1
b = 2
[section s2]
c = 3 ; Comment right side
d = e
"""
lexer = IniLexer(InputStream(source))
stream = CommonTokenStream(lexer)
stream.fill()
for token in stream.tokens[:-1]:
print("{0:<25} '{1}'".format(IniLexer.symbolicNames[token.type], token.text))
您将看到以下输出:
COMMENT '; Comment outside'
SECTION '[section s1]'
COMMENT '; Comment inside'
KEY 'a'
ASSIGN '='
VALUE '1'
KEY 'b'
ASSIGN '='
VALUE '2'
SECTION '[section s2]'
KEY 'c'
ASSIGN '='
VALUE '3'
COMMENT '; Comment right side'
KEY 'd'
ASSIGN '='
VALUE 'e'
伴随的解析器语法如下所示:
parser grammar IniParser;
options {
tokenVocab=IniLexer;
}
sections
: section* EOF
;
section
: COMMENT
| SECTION section_atom*
;
section_atom
: COMMENT
| KEY ASSIGN VALUE
;
这将在以下解析树中解析您的示例输入:

答案 1 :(得分:1)
我已经在C ++中实现了类似的东西。
https://github.com/tora-tool/tora/blob/master/src/editor/tosqltext.cpp
子类化QScintilla类,并基于ANTLR生成的源实现自定义Lexer。
您甚至可以使用ANTLR解析器(我没有使用过),QScitilla允许您拥有多个分析器(权重不同),因此您可以定期对文本执行一些语义检查。在QScintilla中很难做到的是将令牌与一些其他数据相关联。
答案 2 :(得分:0)
Sctintilla中的语法突出显示由专用的荧光笔类(即词法分析器)完成。解析器不太适合此类工作,因为即使输入中包含错误,语法突出显示功能也必须起作用。解析器是一种验证输入正确性的工具-2个完全不同的任务。
因此,我建议您不要再考虑使用ANTLR4了,而只是采用现有的Lex类之一,并为您要突出显示的语言创建一个新的类。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?