дҪҝз”ЁRabbitMq
жҲ‘жӯЈеңЁе°қиҜ•дёәжҲ‘е…¬еҸёеӨ„зҗҶи®ўеҚ•з®ЎзҗҶзҡ„дёҖдәӣз®ҖеҚ•еҶ…йғЁзі»з»ҹе»әз«ӢдёҖдёӘе®һз”Ёзҡ„еҫ®жңҚеҠЎжј”зӨәпјҢдҪҶжҳҜжҲ‘еҫҲйҡҫзҗҶи§ЈеӨ§и§„жЁЎж—¶еҫ®жңҚеҠЎд№Ӣй—ҙзҡ„ж•°жҚ®дёҖиҮҙжҖ§гҖӮ
жҲ‘е·Із»ҸзЎ®е®ҡдәҶеҫ®жңҚеҠЎзҡ„дёҖз§Қз®ҖеҚ•жғ…еҶө-жҲ‘们жӯЈеңЁдҪҝз”Ёзҡ„еҪ“еүҚеә”з”ЁзЁӢеәҸжӯЈеңЁеӨ„зҗҶзҪ‘з«ҷдёҠзҡ„и®ўеҚ•е№¶жӣҙж–°е®ўжҲ·зҡ„вҖңеёҗжҲ·дҝЎз”ЁйўқвҖқ-еҹәжң¬дёҠпјҢ他们еҸҜд»ҘеңЁдҪҝз”ЁеёҗжҲ·еүҚиҠұеңЁжҲ‘们иә«дёҠзҡ„жңӘд»ҳж¬ҫйЎ№йңҖиҰҒиҝӣиЎҢе®Ўж ёгҖӮ
жҲ‘иҜ•еӣҫе°ҶиҝҷдёӘйқһеёёз®ҖеҚ•зҡ„йңҖжұӮеҲҶи§ЈдёәеҮ дёӘеҫ®жңҚеҠЎгҖӮиҝҷдәӣе®ҡд№үеҰӮдёӢпјҡ
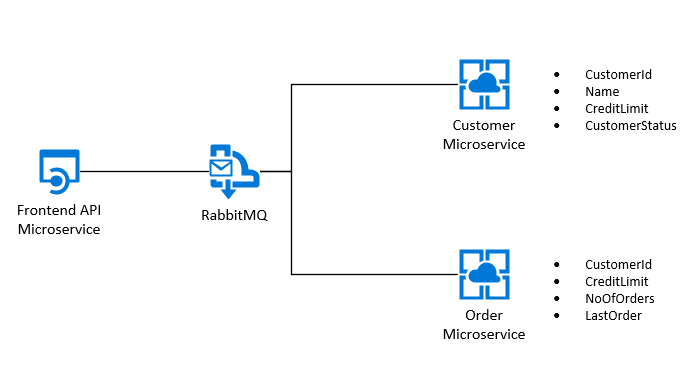
APIжҸҗдҫӣдәҶеҗ„з§ҚдёҚеҗҢзә§еҲ«зҡ„еҠҹиғҪ-е®ғдҪҝжҲ‘们иғҪеӨҹеҲӣе»әж–°е®ўжҲ·пјҢ并и§ҰеҸ‘д»ҘдёӢеҶ…е®№пјҡ
дҪҝз”ЁSQLпјҢжҲ‘们еҸҜд»ҘеңЁж•°жҚ®еә“дёӯиҝӣиЎҢж“ҚдҪңж—¶иҝӣиЎҢдёҖдәӣд№җи§ӮжҹҘиҜўпјҢд»Ҙе°қиҜ•йҖҡиҝҮзј©ж”ҫеҫ®жңҚеҠЎжқҘзЎ®дҝқеҗҢж—¶еӨ„зҗҶдёӨдёӘи®ўеҚ•пјҲдҫӢеҰӮпјҡи®ўеҚ•еҫ®жңҚеҠЎзҡ„дёӨдёӘе®һдҫӢпјҢжҜҸдёӘеҫ®жңҚеҠЎдҪҶдёҚжҜҸдёӘеҫ®жңҚеҠЎе®һдҫӢйғҪжңүиҮӘе·ұзҡ„ж•°жҚ®еә“гҖӮ
дҫӢеҰӮпјҢжҲ‘们еҸҜд»Ҙжү§иЎҢд»ҘдёӢж“ҚдҪңпјҢ并еҒҮе®ҡSQLе°Ҷз®ЎзҗҶй”Ғе®ҡпјҢиҝҷж„Ҹе‘ізқҖеҪ“еҗҢж—¶еӨ„зҗҶдёӨдёӘи®ўеҚ•ж—¶пјҢиҜҘж•°еӯ—еә”д»ҘжӯЈзЎ®зҡ„ж•°еӯ—з»“е°ҫпјҡ
UPDATE [orderms].[customers] SET CreditLimit = CreditLimit - 100, NoOfOrders = NoOfOrders + 1 WHERE CustomerId = 1
дҪҝз”ЁдёҠиҝ°ж–№жі•пјҢеҰӮжһңиҙ·йЎ№дёә1000пјҢ并且еӨ„зҗҶдәҶ2дёӘи®ўеҚ•пјҲжҜҸдёӘи®ўеҚ•100дёӘпјүпјҢ并且жҜҸдёӘи®ўеҚ•йғҪеҲҶй…Қз»ҷвҖң OrderвҖқеҫ®жңҚеҠЎзҡ„дёҚеҗҢе®һдҫӢпјҢйӮЈд№ҲжҲ‘们еә”иҜҘиғҪеӨҹеҒҮе®ҡжӯЈзЎ®зҡ„ж•°еӯ—дјҡеҮәзҺ°еңЁи®ўеҚ•еҫ®жңҚеҠЎдёӯзҡ„customersиЎЁпјҲеҹәдәҺMSSQLжҹҘиҜўзҡ„й”Ғе®ҡеә”иҮӘеҠЁеӨ„зҗҶпјүгҖӮ
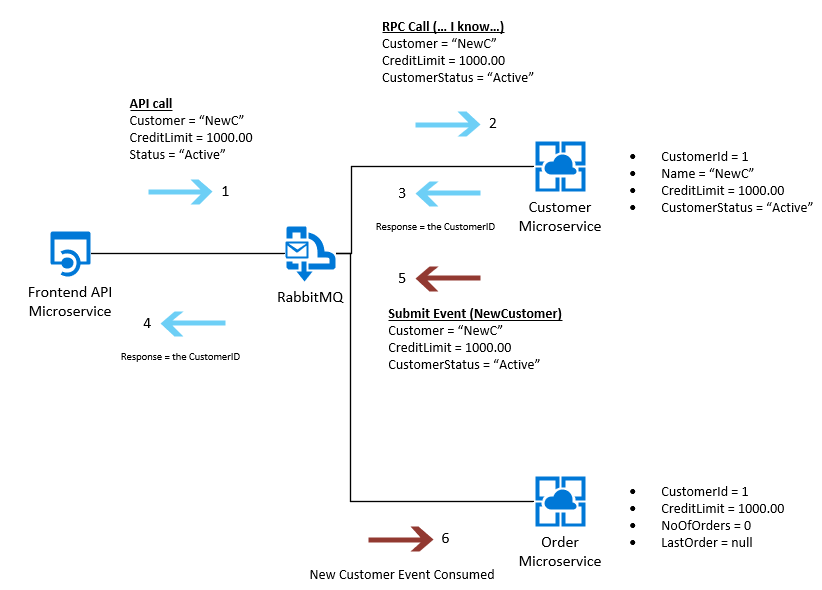
然еҗҺпјҢеҪ“жҲ‘们е°қиҜ•е°Ҷе®ғ们йҮҚж–°йӣҶжҲҗеҲ°е®ўжҲ·еҫ®жңҚеҠЎж—¶пјҢй—®йўҳе°ұжқҘдәҶгҖӮжҲ‘们е°Ҷ收еҲ°дёӨжқЎж¶ҲжҒҜпјҢжқҘиҮӘдҪңдёәдәӢд»¶дј йҖ’зҡ„и®ўеҚ•еҫ®жңҚеҠЎзҡ„жҜҸдёӘе®һдҫӢпјҢеҰӮдёӢжүҖзӨәпјҡ
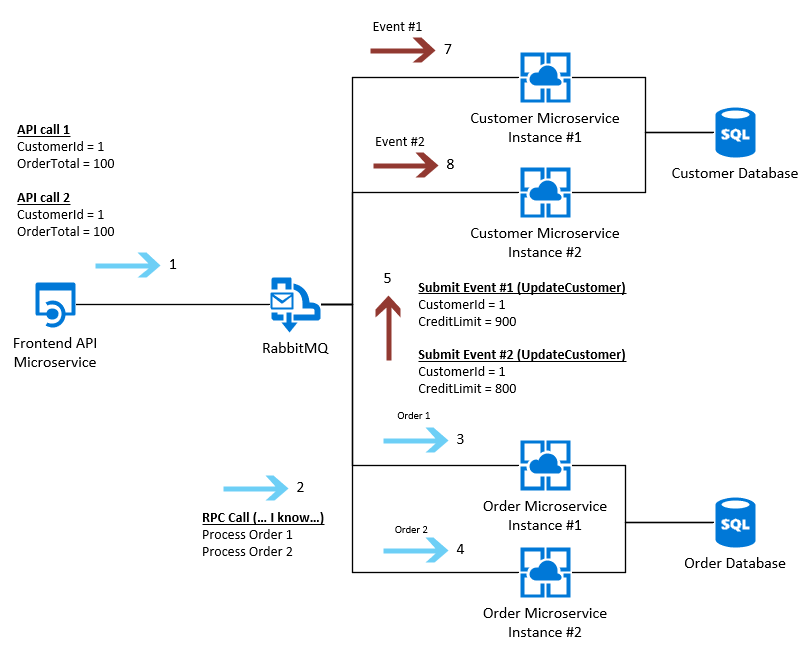
йүҙдәҺдёҠиҝ°жғ…еҶө-жҲ‘们еҫҲеҸҜиғҪдјҡжҢүз…§д»ҘдёӢж–№ејҸпјҲд»ҘдёӢжҳҜдёӨдёӘжҹҘиҜўпјүйҒөеҫӘжӣҙж–°вҖңе®ўжҲ·вҖқ SQLиЎЁзҡ„жЁЎејҸпјҡ
UPDATE [customerms].[customers] SET CreditLimit = 900.00 WHERE CustomerId = 1
UPDATE [customerms].[customers] SET CreditLimit = 800.00 WHERE CustomerId = 1
дҪҶжҳҜ-ж №жҚ®иҝҷдәӣвҖңе®ўжҲ·вҖқеҫ®жңҚеҠЎзҡ„иҝҗиЎҢйҖҹеәҰпјҢе®һдҫӢ1зӣ®еүҚеҸҜиғҪжӯЈеңЁеҲӣе»әеӨҡдёӘж–°е®ўжҲ·пјҢеӣ жӯӨеӨ„зҗҶиҜҘиҜ·жұӮзҡ„йҖҹеәҰеҸҜиғҪжҜ”е®һдҫӢ2ж…ўпјҢиҝҷж„Ҹе‘ізқҖSQLжҹҘиҜўе°Ҷдјҡж— еәҸжү§иЎҢпјҢеӣ жӯӨжҲ‘们е°Ҷеү©дёӢвҖңдҝЎз”ЁвҖқйҷҗеҲ¶дёә800пјҲжӯЈзЎ®пјүзҡ„вҖңи®ўеҚ•вҖқж•°жҚ®еә“е’ҢвҖңдҝЎз”ЁйҷҗеҲ¶вҖқдёә900пјҲй”ҷиҜҜпјүзҡ„е®ўжҲ·еҫ®жңҚеҠЎгҖӮ
еңЁж•ҙдҪ“еә”з”ЁзЁӢеәҸдёӯпјҢеҰӮжһңзЎ®е®һйңҖиҰҒпјҢжҲ‘们йҖҡеёёдјҡж·»еҠ дёҖдёӘй”Ғе…ғзҙ пјҲжҲ–еҸҜиғҪжҳҜMutexпјүпјҢеҗҰеҲҷж №жҚ®Order Microserviceдёӯзҡ„еҠҹиғҪдҫқиө–дәҺSQLй”ҒпјҢдҪҶжҳҜз”ұдәҺиҝҷжҳҜдёҖдёӘеҲҶеёғејҸиҝҮзЁӢпјҢиҝҷдәӣиҫғж—§зҡ„ж–№жі•йғҪдёҚйҖӮз”ЁгҖӮ
жңүд»Җд№Ҳе»әи®®еҗ—пјҹжҲ‘дјјд№Һж— жі•д»Ҙжҹҗз§Қж–№ејҸзңӢеҲ°иҝҮеҺ»пјҹ
1 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ1)
жҲ‘и®Өдёәи§ЈеҶіж–№жЎҲ
еңЁдёӨдёӘеҫ®жңҚеҠЎдёӯйғҪз»ҙжҢҒеҲқе§ӢдҝЎз”ЁйўқеәҰгҖӮеҒҮи®ҫеҲқе§ӢдҝЎз”ЁйўқеәҰдёә1000пјҢ然еҗҺеңЁдёӨдёӘMicroservicesж•°жҚ®еә“дёӯиҝӣиЎҢи®ҫзҪ®гҖӮеңЁеӨ„зҗҶи®ўеҚ•ж—¶пјҢйҰ–е…ҲеңЁи®ўеҚ•еҫ®жңҚеҠЎеӨ„е°Ҷе…¶еҮҸе°‘пјҢиҖҢдёҚжҳҜеҸ‘йҖҒдҝЎз”ЁйўқеәҰпјҲ800пјҢ900жҲ–д»»дҪ•йҮ‘йўқпјүпјҢиҖҢжҳҜеҸ‘йҖҒеҝ…йЎ»д»Һе®ўжҲ·еҫ®жңҚеҠЎдҝЎз”ЁйўқеәҰдёӯеҮҸе°‘зҡ„йҮ‘йўқгҖӮ
иҜҙжӮЁе·Із»ҸеӨ„зҗҶдәҶдёӨдёӘи®ўеҚ•пјҢжҜҸдёӘи®ўеҚ•д»·еҖј100гҖӮйҰ–е…ҲйҷҚдҪҺеҫ®жңҚеҠЎи®ўеҚ•зҡ„дҝЎз”ЁйўқеәҰпјҢ然еҗҺз”ҹжҲҗдёӨдёӘжҜҸ笔100зҫҺе…ғзҡ„дәӢ件пјҢиҝҷдәӣдәӢ件е°Ҷз”ұе®ўжҲ·жңҚеҠЎйғЁй—Ёж¶Ҳиҙ№пјҢ并еңЁиҜҘдәӢ件еҮҸе°‘гҖӮиҝҷж ·пјҢж— и®әе®ғ们еҲ°иҫҫзҡ„йЎәеәҸеҰӮдҪ•пјҢжӮЁйғҪеҸӘйңҖиҰҒеҮҸе°‘иҜҘж•°йҮҸеҚіеҸҜгҖӮ
дәӢ件жқҘжәҗпјҲжӣҙеҘҪзҡ„ж–№жі•пјү
йҮҮз”Ёд№җи§Ӯй”Ғе®ҡзҡ„дәӢ件жқҘжәҗжҳҜжӮЁеҸҜд»ҘйҮҮеҸ–зҡ„ж–№жі•гҖӮиҝҷз§ҚжЁЎејҸжҳҜе°ҶжүҖжңүдәӢ件дҝқеӯҳеңЁж•°жҚ®еә“дёӯпјҢиҖҢдёҚжҳҜдҝқеӯҳе®һдҪ“зҡ„зү№е®ҡзҠ¶жҖҒгҖӮе®ғеҸӘжҳҜдёҖдёӘиҝҪеҠ еӯҳеӮЁпјҢдәӢ件жҢүе®ғ们еҲ°иҫҫзҡ„йЎәеәҸеӯҳеӮЁгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢжӮЁйңҖиҰҒйҮҚж’ӯдәӢ件д»ҘиҫҫеҲ°зү№е®ҡзҠ¶жҖҒзҡ„дҝЎз”ЁйўқеәҰгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢжӮЁе°ҶжӢҘжңүжүҖжңүеҺҶеҸІи®°еҪ•гҖӮиҜ·и®°дҪҸпјҢеҰӮжһңжңүд»»дҪ•дёҚдёҖиҮҙзҡ„ең°ж–№пјҢжӮЁжІЎжңүд»»дҪ•ж—Ҙеҝ—еҸҜд»ҘеӣһйҖҖпјҢдҪҶжҳҜжңүдәҶдәӢ件жәҗпјҢжӮЁе°ұжңүдәҶгҖӮ
- MongoDBе’ҢRabbitMQд№Ӣй—ҙзҡ„дёҖиҮҙжҖ§
- ж•°жҚ®еә“дёҺеҫ®жңҚеҠЎзҡ„дёҖиҮҙжҖ§
- еңЁеҫ®жңҚеҠЎд№Ӣй—ҙе…ұдә«еӨ§йҮҸж•°жҚ®
- и·Ёеҫ®жңҚеҠЎзҡ„ж•°жҚ®дёҖиҮҙжҖ§
- дҝқжҢҒеҫ®жңҚеҠЎзҡ„дёҖиҮҙжҖ§
- еҫ®жңҚеҠЎпјҢCQRSпјҡжңҖз»ҲдёҖиҮҙжҖ§дёҺејәдёҖиҮҙжҖ§пјҲеҶҷеҗҺдёҖиҮҙжҖ§иҜ»еҸ–пјү
- еҫ®жңҚеҠЎд№Ӣй—ҙзҡ„йҖҡдҝЎ - иҜ·жұӮж•°жҚ®
- зҪ‘е…іиҒҡеҗҲдёӯзҡ„дёҖиҮҙжҖ§еӨ„зҗҶпјҹ
- и·ЁеӨҡдёӘеҫ®жңҚеҠЎзҡ„ж•°жҚ®дёҖиҮҙжҖ§пјҢиҝҷдәӣеҫ®жңҚеҠЎйҮҚеӨҚж•°жҚ®
- дҪҝз”ЁRabbitMq
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ