йҖҡиҝҮеӨҡдёӘеӯ—ж®өиҝӣиЎҢжұҮжҖ»е№¶жҳ е°„еҲ°дёҖдёӘз»“жһң
еҜ№дәҺд»ҺзҘЁеҠЎзі»з»ҹжөҒејҸдј иҫ“зҡ„ж•°жҚ®пјҢжҲ‘们е°қиҜ•е®һзҺ°д»ҘдёӢзӣ®ж Ү
иҺ·еҸ–жҢүзҠ¶жҖҒе’Ңе®ўжҲ·еҲҶз»„зҡ„жңӘеӨ„зҗҶж•…йҡңеҚ•ж•°йҮҸгҖӮ з®ҖеҢ–зҡ„жЁЎејҸеҰӮдёӢ
Field | Type
-------------------------------------------------
ROWTIME | BIGINT (system)
ROWKEY | VARCHAR(STRING) (system)
ID | BIGINT
TICKET_ID | BIGINT
STATUS | VARCHAR(STRING)
TICKETCATEGORY_ID | BIGINT
SUBJECT | VARCHAR(STRING)
PRIORITY | VARCHAR(STRING)
STARTTIME | BIGINT
ENDTIME | BIGINT
CHANGETIME | BIGINT
REMINDTIME | BIGINT
DEADLINE | INTEGER
CONTACT_ID | BIGINT
жҲ‘们жғідҪҝз”ЁиҜҘж•°жҚ®жқҘиҺ·еҸ–жҜҸдёӘе®ўжҲ·е…·жңүзү№е®ҡзҠ¶жҖҒпјҲжү“ејҖпјҢзӯүеҫ…пјҢиҝӣиЎҢдёӯзӯүпјүзҡ„зҘЁиҜҒж•°йҮҸгҖӮиҜҘж•°жҚ®еҝ…йЎ»еңЁеҸҰдёҖдёӘдё»йўҳдёӯдј йҖ’дёҖжқЎж¶ҲжҒҜ-иҜҘж–№жЎҲеҸҜиғҪзңӢиө·жқҘеғҸиҝҷж ·
Field | Type
-------------------------------------------------
ROWTIME | BIGINT (system)
ROWKEY | VARCHAR(STRING) (system)
CONTACT_ID | BIGINT
COUNT_OPEN | BIGINT
COUNT_WAITING | BIGINT
COUNT_CLOSED | BIGINT
жҲ‘们计еҲ’дҪҝз”ЁжӯӨж•°жҚ®е’Ңе…¶д»–ж•°жҚ®жқҘе……е®һе®ўжҲ·дҝЎжҒҜпјҢ并е°Ҷе……е®һзҡ„ж•°жҚ®йӣҶеҸ‘еёғеҲ°еӨ–йғЁзі»з»ҹпјҲдҫӢеҰӮelasticsearchпјү
иҺ·еҫ—第дёҖйғЁеҲҶйқһеёёе®№жҳ“-ж №жҚ®е®ўжҲ·е’ҢзҠ¶жҖҒеҜ№зҘЁиҝӣиЎҢеҲҶз»„гҖӮ
select contact_id,status count(*) cnt from tickets group by contact_id,status;
дҪҶжҳҜзҺ°еңЁжҲ‘们被еӣ°дҪҸдәҶ-жҜҸдёӘе®ўжҲ·иҺ·еҫ—еӨҡиЎҢ/ж¶ҲжҒҜпјҢиҖҢжҲ‘们еҸӘжҳҜдёҚзҹҘйҒ“еҰӮдҪ•е°Ҷе®ғ们иҪ¬жҚўдёәдёҖжқЎд»Ҙcontact_idдёәй”®зҡ„ж¶ҲжҒҜгҖӮ
жҲ‘们е°қиҜ•дәҶеҠ е…ҘпјҢдҪҶжүҖжңүе°қиҜ•еқҮжңӘжҲҗеҠҹгҖӮ
зӨәдҫӢ
дёәжүҖжңүжҢүе®ўжҲ·еҲҶз»„зҡ„вҖңзӯүеҫ…вҖқзҠ¶жҖҒзҡ„зҘЁеҲӣе»әиЎЁ
create table waiting_tickets_by_cust with (partitions=12,value_format='AVRO')
as select contact_id, count(*) cnt from tickets where status='waiting' group by contact_id;
з”ЁдәҺиҒ”жҺҘзҡ„еҜҶй’ҘиЎЁ
CREATE TABLE T_WAITING_REKEYED with WITH (KAFKA_TOPIC='WAITING_TICKETS_BY_CUST',
VALUE_FORMAT='AVRO',
KEY='contact_id');
е°ҶиҜҘиЎЁдёҺе®ўжҲ·иЎЁзҡ„е·Ұдҫ§пјҲеӨ–йғЁпјүиҝһжҺҘиө·жқҘпјҢе°ҶдёәжҲ‘们жҸҗдҫӣжүҖжңүжӯЈеңЁзӯүеҫ…зҘЁиҜҒзҡ„е®ўжҲ·гҖӮ
select c.id,w.cnt wcnt from T_WAITING_REKEYED w left join CRM_CONTACTS c on w.contact_id=c.id;
дҪҶжҳҜпјҢжҲ‘们е°ҶйңҖиҰҒжүҖжңүе®ўжҲ·пјҢдё”зӯүеҫ…и®Ўж•°дёәNULLжүҚиғҪдҪҝз”ЁиҜҘз»“жһңпјҢд»ҺиҖҢеҜјиҮҙеҸҰдёҖдёӘзҘЁиҜҒзҠ¶жҖҒдёәPROCESSINGзҡ„иҒ”жҺҘгҖӮ еӣ дёәжҲ‘们еҸӘжңүзӯүеҫ…дёӯзҡ„е®ўжҲ·пјҢжүҖд»ҘеҸӘжңүйӮЈдәӣеҗҢж—¶е…·жңүиҝҷдёӨз§ҚзҠ¶жҖҒзҡ„е®ўжҲ·жүҚиғҪеҫ—еҲ°жҲ‘们гҖӮ
ksql> select c.*,t.cnt from T_PROCESSING_REKEYED t left join cust_ticket_tmp1 c on t.contact_id=c.id;
null | null | null | null | 1
1555261086669 | 1472 | 1472 | 0 | 1
1555261086669 | 1472 | 1472 | 0 | 1
null | null | null | null | 1
1555064371937 | 1474 | 1474 | 1 | 1
null | null | null | null | 1
1555064371937 | 1474 | 1474 | 1 | 1
null | null | null | null | 1
null | null | null | null | 1
null | null | null | null | 1
1555064372018 | 3 | 3 | 5 | 6
1555064372018 | 3 | 3 | 5 | 6
йӮЈд№Ҳжү§иЎҢжӯӨж“ҚдҪңзҡ„жӯЈзЎ®ж–№жі•жҳҜд»Җд№Ҳпјҹ
иҝҷжҳҜKSQL 5.2.1
и°ўи°ў
зј–иҫ‘пјҡ
д»ҘдёӢжҳҜдёҖдәӣзӨәдҫӢж•°жҚ®
еҲӣе»әдәҶдёҖдёӘе°Ҷж•°жҚ®йҷҗеҲ¶дёәжөӢиҜ•еёҗжҲ·зҡ„дё»йўҳ
CREATE STREAM tickets_filtered
WITH (
PARTITIONS=12,
VALUE_FORMAT='JSON') AS
SELECT id,
contact_id,
subject,
status,
TIMESTAMPTOSTRING(changetime, 'yyyy-MM-dd HH:mm:ss.SSS') AS timestring
FROM tickets where contact_id=1472
PARTITION BY contact_id;
00:06:44 1 $ kafkacat-dev -C -o beginning -t TICKETS_FILTERED
{"ID":2216,"CONTACT_ID":1472,"SUBJECT":"Test Bodenbach","STATUS":"closed","TIMESTRING":"2012-11-08 10:34:30.000"}
{"ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"waiting","TIMESTRING":"2019-04-16 23:07:01.000"}
{"ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"processing","TIMESTRING":"2019-04-16 23:52:08.000"}
Changing and adding something in the ticketing-system...
{"ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"waiting","TIMESTRING":"2019-04-17 00:10:38.000"}
{"ID":8952,"CONTACT_ID":1472,"SUBJECT":"another sync ticket","STATUS":"new","TIMESTRING":"2019-04-17 00:11:23.000"}
{"ID":8952,"CONTACT_ID":1472,"SUBJECT":"another sync ticket","STATUS":"close-request","TIMESTRING":"2019-04-17 00:12:04.000"}
жҲ‘们иҰҒж №жҚ®иҝҷдәӣж•°жҚ®еҲӣе»әдёҖдёӘдё»йўҳпјҢж¶ҲжҒҜзңӢиө·жқҘеғҸиҝҷж ·
{"CONTACT_ID":1472,"TICKETS_CLOSED":1,"TICKET_WAITING":1,"TICKET_CLOSEREQUEST":1,"TICKET_PROCESSING":0}
1 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ0)
пјҲwritten up here tooпјү
еҸҜд»ҘйҖҡиҝҮе»әз«ӢдёҖдёӘиЎЁпјҲз”ЁдәҺзҠ¶жҖҒпјүпјҢ然еҗҺеңЁиҜҘиЎЁдёҠиҝӣиЎҢжұҮжҖ»жқҘеҒҡеҲ°иҝҷдёҖзӮ№гҖӮ
-
и®ҫзҪ®жөӢиҜ•ж•°жҚ®
kafkacat -b localhost -t tickets -P <<EOF {"ID":2216,"CONTACT_ID":1472,"SUBJECT":"Test Bodenbach","STATUS":"closed","TIMESTRING":"2012-11-08 10:34:30.000"} {"ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"waiting","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"processing","TIMESTRING":"2019-04-16 23:52:08.000"} {"ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"waiting","TIMESTRING":"2019-04-17 00:10:38.000"} {"ID":8952,"CONTACT_ID":1472,"SUBJECT":"another sync ticket","STATUS":"new","TIMESTRING":"2019-04-17 00:11:23.000"} {"ID":8952,"CONTACT_ID":1472,"SUBJECT":"another sync ticket","STATUS":"close-request","TIMESTRING":"2019-04-17 00:12:04.000"} EOF -
йў„и§Ҳдё»йўҳж•°жҚ®
ksql> PRINT 'tickets' FROM BEGINNING; Format:JSON {"ROWTIME":1555511270573,"ROWKEY":"null","ID":2216,"CONTACT_ID":1472,"SUBJECT":"Test Bodenbach","STATUS":"closed","TIMESTRING":"2012-11-08 10:34:30.000"} {"ROWTIME":1555511270573,"ROWKEY":"null","ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"waiting","TIMESTRING":"2019-04-16 23:07:01.000"} {"ROWTIME":1555511270573,"ROWKEY":"null","ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"processing","TIMESTRING":"2019-04-16 23:52:08.000"} {"ROWTIME":1555511270573,"ROWKEY":"null","ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"waiting","TIMESTRING":"2019-04-17 00:10:38.000"} {"ROWTIME":1555511270573,"ROWKEY":"null","ID":8952,"CONTACT_ID":1472,"SUBJECT":"another sync ticket","STATUS":"new","TIMESTRING":"2019-04-17 00:11:23.000"} {"ROWTIME":1555511270573,"ROWKEY":"null","ID":8952,"CONTACT_ID":1472,"SUBJECT":"another sync ticket","STATUS":"close-request","TIMESTRING":"2019-04-17 00:12:04.000"} -
жіЁеҶҢжөҒ
CREATE STREAM TICKETS (ID INT, CONTACT_ID VARCHAR, SUBJECT VARCHAR, STATUS VARCHAR, TIMESTRING VARCHAR) WITH (KAFKA_TOPIC='tickets', VALUE_FORMAT='JSON'); -
жҹҘиҜўж•°жҚ®
ksql> SET 'auto.offset.reset' = 'earliest'; ksql> SELECT * FROM TICKETS; 1555502643806 | null | 2216 | 1472 | Test Bodenbach | closed | 2012-11-08 10:34:30.000 1555502643806 | null | 8945 | 1472 | sync-test | waiting | 2019-04-16 23:07:01.000 1555502643806 | null | 8945 | 1472 | sync-test | processing | 2019-04-16 23:52:08.000 1555502643806 | null | 8945 | 1472 | sync-test | waiting | 2019-04-17 00:10:38.000 1555502643806 | null | 8952 | 1472 | another sync ticket | new | 2019-04-17 00:11:23.000 1555502643806 | null | 8952 | 1472 | another sync ticket | close-request | 2019-04-17 00:12:04.000 -
еңЁиҝҷдёҖзӮ№дёҠпјҢжҲ‘们еҸҜд»ҘдҪҝз”Ё
CASEжқҘжһўзәҪиҒҡеҗҲпјҡSELECT CONTACT_ID, SUM(CASE WHEN STATUS='new' THEN 1 ELSE 0 END) AS TICKETS_NEW, SUM(CASE WHEN STATUS='processing' THEN 1 ELSE 0 END) AS TICKETS_PROCESSING, SUM(CASE WHEN STATUS='waiting' THEN 1 ELSE 0 END) AS TICKETS_WAITING, SUM(CASE WHEN STATUS='close-request' THEN 1 ELSE 0 END) AS TICKETS_CLOSEREQUEST , SUM(CASE WHEN STATUS='closed' THEN 1 ELSE 0 END) AS TICKETS_CLOSED FROM TICKETS GROUP BY CONTACT_ID; 1472 | 1 | 1 | 2 | 1 | 1дҪҶжҳҜпјҢжӮЁдјҡжіЁж„ҸеҲ°зӯ”жЎҲдёҺйў„жңҹдёҚз¬ҰгҖӮиҝҷжҳҜеӣ дёәжҲ‘们жӯЈеңЁи®Ўз®—жүҖжңүе…ӯдёӘиҫ“е…ҘдәӢ件гҖӮ
и®©жҲ‘们зңӢдёҖдёӢIDдёә
8945зҡ„еҚ•дёӘж•…йҡңеҚ•-е®ғз»ҸеҺҶдәҶдёүдёӘзҠ¶жҖҒжӣҙж”№пјҲwaiting->processing->waitingпјүпјҢжҜҸдёӘзҠ¶жҖҒжӣҙж”№йғҪеҢ…еҗ«еңЁйӘЁж–ҷгҖӮжҲ‘们еҸҜд»ҘдҪҝз”ЁдёҖдёӘз®ҖеҚ•зҡ„и°“иҜҚжқҘйӘҢиҜҒиҝҷдёҖзӮ№пјҡSELECT CONTACT_ID, SUM(CASE WHEN STATUS='new' THEN 1 ELSE 0 END) AS TICKETS_NEW, SUM(CASE WHEN STATUS='processing' THEN 1 ELSE 0 END) AS TICKETS_PROCESSING, SUM(CASE WHEN STATUS='waiting' THEN 1 ELSE 0 END) AS TICKETS_WAITING, SUM(CASE WHEN STATUS='close-request' THEN 1 ELSE 0 END) AS TICKETS_CLOSEREQUEST , SUM(CASE WHEN STATUS='closed' THEN 1 ELSE 0 END) AS TICKETS_CLOSED FROM TICKETS WHERE ID=8945 GROUP BY CONTACT_ID; 1472 | 0 | 1 | 2 | 0 | 0 -
жҲ‘们зңҹжӯЈжғіиҰҒзҡ„жҳҜжҜҸеј зҘЁиҜҒзҡ„еҪ“еүҚзҠ¶жҖҒгҖӮеӣ жӯӨпјҢйҮҚж–°еҲҶй…ҚзҘЁиҜҒIDдёҠзҡ„ж•°жҚ®пјҡ
CREATE STREAM TICKETS_BY_ID AS SELECT * FROM TICKETS PARTITION BY ID; CREATE TABLE TICKETS_TABLE (ID INT, CONTACT_ID INT, SUBJECT VARCHAR, STATUS VARCHAR, TIMESTRING VARCHAR) WITH (KAFKA_TOPIC='TICKETS_BY_ID', VALUE_FORMAT='JSON', KEY='ID'); -
жҜ”иҫғдәӢ件жөҒдёҺеҪ“еүҚзҠ¶жҖҒ
-
дәӢ件жөҒпјҲKSQLжөҒпјү
ksql> SELECT ID, TIMESTRING, STATUS FROM TICKETS; 2216 | 2012-11-08 10:34:30.000 | closed 8945 | 2019-04-16 23:07:01.000 | waiting 8945 | 2019-04-16 23:52:08.000 | processing 8945 | 2019-04-17 00:10:38.000 | waiting 8952 | 2019-04-17 00:11:23.000 | new 8952 | 2019-04-17 00:12:04.000 | close-request -
еҪ“еүҚзҠ¶жҖҒпјҲKSQLиЎЁпјү
ksql> SELECT ID, TIMESTRING, STATUS FROM TICKETS_TABLE; 2216 | 2012-11-08 10:34:30.000 | closed 8945 | 2019-04-17 00:10:38.000 | waiting 8952 | 2019-04-17 00:12:04.000 | close-request
-
-
жҲ‘们жғіиҰҒдёҖдёӘиЎЁзҡ„жұҮжҖ»пјҢжҲ‘们жғіиҰҒиҝҗиЎҢдёҺдёҠйқўзӣёеҗҢзҡ„
SUM(CASEвҖҰ)вҖҰGROUP BYжҠҖе·§пјҢдҪҶиҰҒеҹәдәҺжҜҸеј зҘЁиҜҒзҡ„еҪ“еүҚзҠ¶жҖҒпјҢиҖҢдёҚжҳҜжҜҸдёӘдәӢ件пјҡSELECT CONTACT_ID, SUM(CASE WHEN STATUS='new' THEN 1 ELSE 0 END) AS TICKETS_NEW, SUM(CASE WHEN STATUS='processing' THEN 1 ELSE 0 END) AS TICKETS_PROCESSING, SUM(CASE WHEN STATUS='waiting' THEN 1 ELSE 0 END) AS TICKETS_WAITING, SUM(CASE WHEN STATUS='close-request' THEN 1 ELSE 0 END) AS TICKETS_CLOSEREQUEST , SUM(CASE WHEN STATUS='closed' THEN 1 ELSE 0 END) AS TICKETS_CLOSED FROM TICKETS_TABLE GROUP BY CONTACT_ID;иҝҷз»ҷдәҶжҲ‘们жҲ‘们жғіиҰҒзҡ„пјҡ
1472 | 0 | 0 | 1 | 1 | 1 -
и®©жҲ‘们е°ҶеҸҰдёҖдёӘж•…йҡңеҚ•зҡ„дәӢ件жҸҗдҫӣз»ҷдё»йўҳпјҢ并и§ӮеҜҹиЎЁзҠ¶жҖҒеҰӮдҪ•еҸҳеҢ–гҖӮ зҠ¶жҖҒжӣҙж”№ж—¶пјҢиЎЁдёӯзҡ„иЎҢдјҡйҮҚж–°еҸ‘еҮәпјӣжӮЁиҝҳеҸҜд»ҘеҸ–ж¶Ҳ
SELECT并йҮҚж–°иҝҗиЎҢд»Ҙд»…жҹҘзңӢеҪ“еүҚзҠ¶жҖҒгҖӮ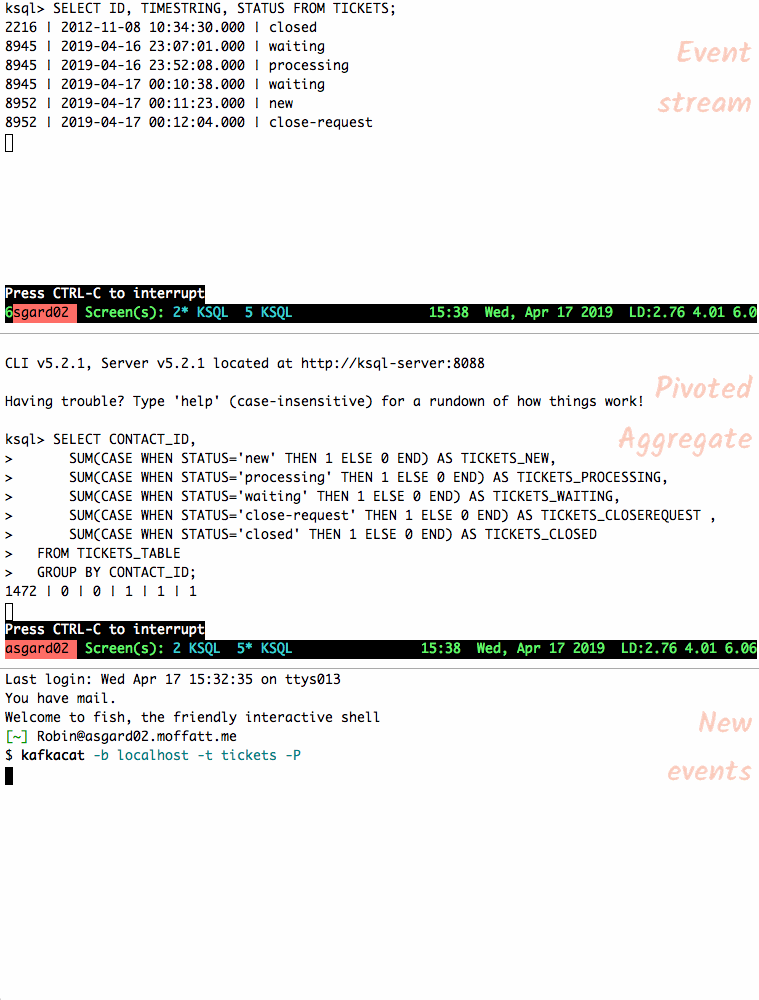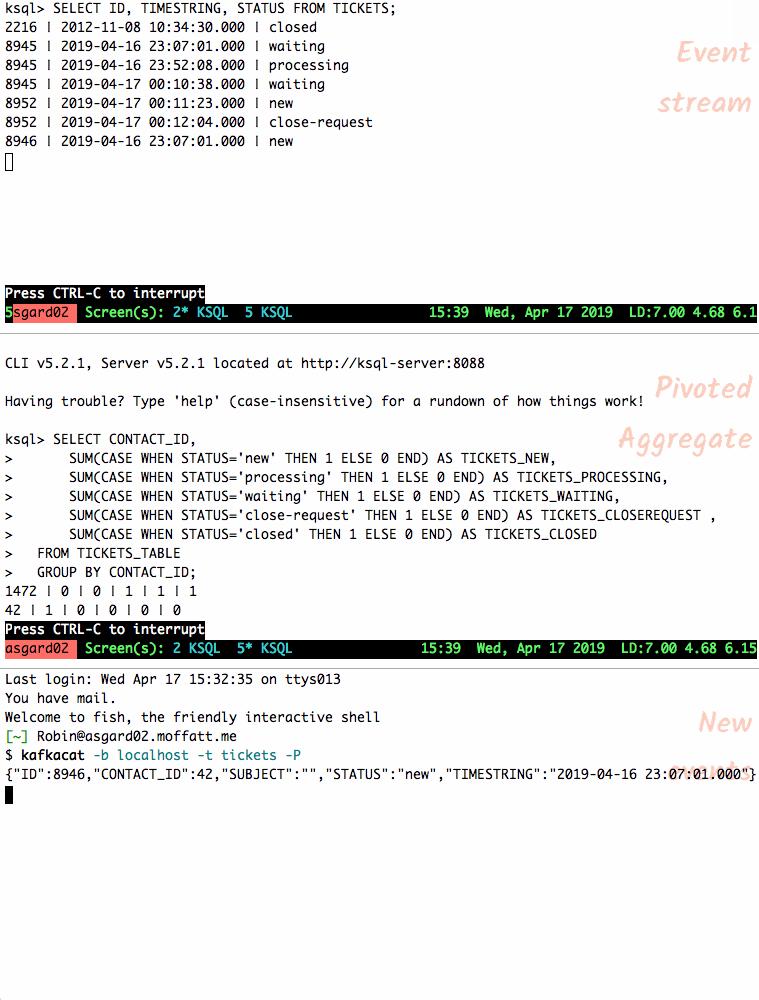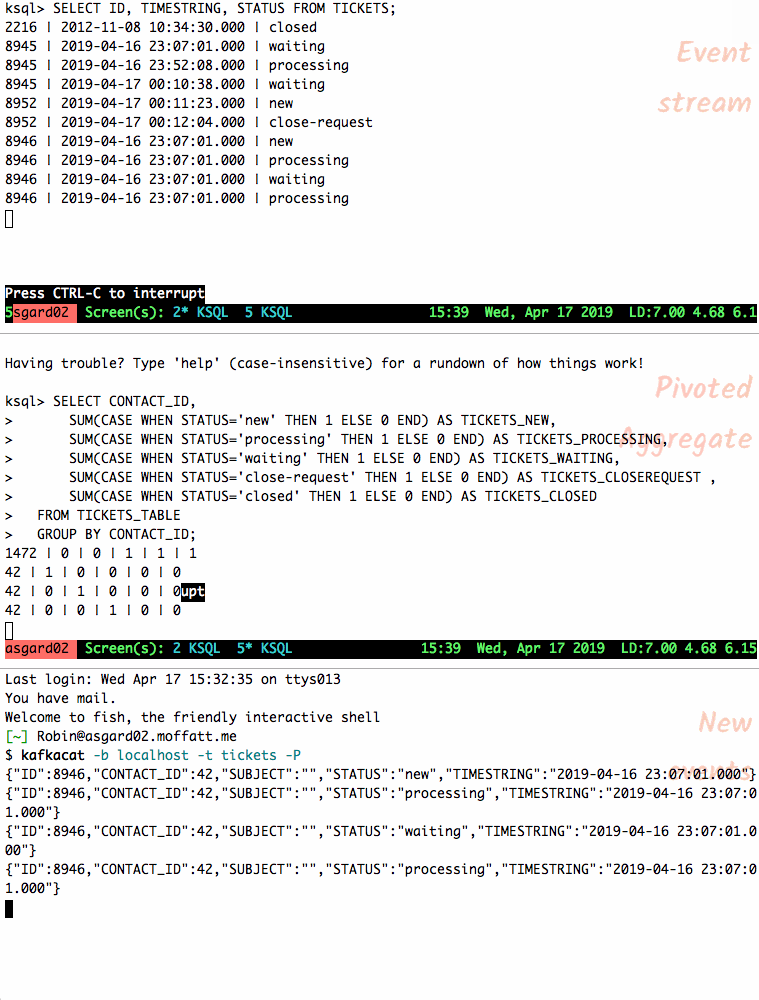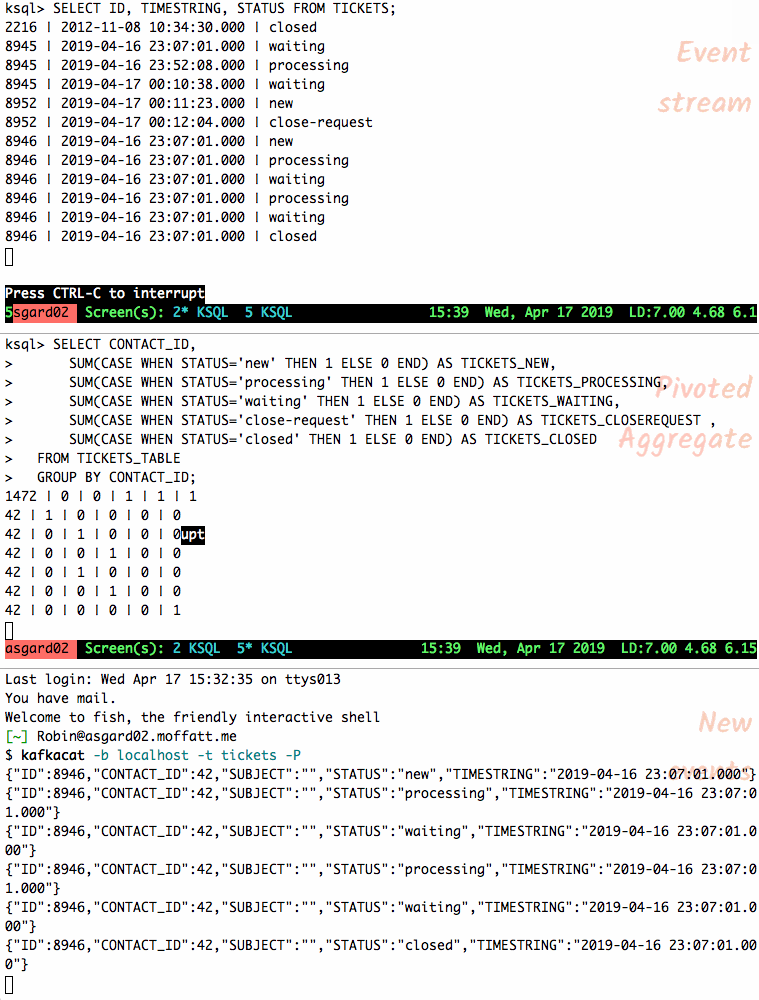
еҜ№ж•°жҚ®иҝӣиЎҢжҠҪж ·д»ҘдәІиҮӘе°қиҜ•пјҡ
{"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"new","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"processing","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"waiting","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"processing","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"waiting","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"closed","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"close-request","TIMESTRING":"2019-04-16 23:07:01.000"}
еҰӮжһңжӮЁжғіиҝӣдёҖжӯҘе°қиҜ•пјҢеҸҜд»ҘдҪҝз”ЁMockarooз”ҹжҲҗзҡ„е…¶д»–дјӘж•°жҚ®жөҒпјҢйҖҡиҝҮawkиҝӣиЎҢз®ЎйҒ“дј иҫ“д»ҘеҮҸж…ўе®ғзҡ„йҖҹеәҰпјҢд»ҘдҫҝжӮЁзңӢеҲ°еҜ№з”ҹжҲҗзҡ„иҒҡеҗҲзҡ„еҪұе“ҚеҪ“жҜҸжқЎж¶ҲжҒҜеҲ°иҫҫж—¶пјҡ
while [ 1 -eq 1 ]
do curl -s "https://api.mockaroo.com/api/f2d6c8a0?count=1000&key=ff7856d0" | \
awk '{print $0;system("sleep 2");}' | \
kafkacat -b localhost -t tickets -P
done
- иҒҡеҗҲеӨҡдёӘеӯ—ж®ө
- е°ҶеӨҡдёӘжҹҘиҜўиҒҡеҗҲдёәдёҖдёӘ
- иҒҡеҗҲж—¶еҰӮдҪ•еңЁйЎ№зӣ®дёӯйҖҗдёӘеҲ—еҮәжүҖжңүеӯ—ж®өпјҹ
- жҢүж—ҘжңҹжұҮжҖ»еӨҡдёӘи®°еҪ•
- жҢүеӨҡдёӘеӯ—ж®өеҲҶз»„е№¶ж јејҸеҢ–з»“жһң
- KibanaиҒҡеҗҲеӨҡдёӘеӯ—ж®ө
- дҪҝз”ЁMapStructе°ҶеӨҡдёӘеӯ—ж®өжҳ е°„еҲ°дёҖдёӘеӯ—ж®ө
- еҲҶз»„д»ҺеӨҡдёӘжҹҘиҜўз»“жһңе’ҢиҒҡеҗҲз»“жһңи’ҷжҲҲ
- жҢүеӨҡдёӘеӯ—ж®өеҲҶ组并еңЁmongodbдёӯж јејҸеҢ–з»“жһңпјҹ
- йҖҡиҝҮеӨҡдёӘеӯ—ж®өиҝӣиЎҢжұҮжҖ»е№¶жҳ е°„еҲ°дёҖдёӘз»“жһң
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ