Tensorflow Dataset迭代器消耗大量内存
我最近正在学习机器学习,并尝试使用Tensorflow实现一个简单的神经网络。
我使用MNIST作为数据集,我想使用Tensorflow的Dataset API加载和批处理我的数据。
这是我的代码:
train_data = tf.data.Dataset.from_tensor_slices((X_train, y_train))
train_data = train_data.shuffle(500)
train_data = train_data.batch(50)
train_data = train_data.repeat()
td_iter = train_data.make_one_shot_iterator()
features, labels = td_iter.get_next()
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
for iteration in range(n_batches):
X_batch, y_batch = sess.run([features, labels])
sess.run(training_op, feed_dict={X:X_batch, y:y_batch})
acc_train = accuracy.eval(feed_dict={X:X_batch, y:y_batch})
acc_test = accuracy.eval(feed_dict={X:X_test, y:y_test})
print(epoch, "Train accuracy:", acc_train, "Test accuracy:", acc_test)
我能够高精度地训练模型,但是训练时它会消耗我的所有内存(8GB)。
更具体地说,它在完成第一个时期之前会消耗大量内存(并且打印第一条输出行需要花费相当长的时间),但是如果开始打印某些内容,则内存消耗会减少。
我尝试简化代码以找出问题所在:
with tf.Session() as sess:
sess.run(init)
sess.run([features, labels])
上面的代码仍然会耗尽我的全部内存。
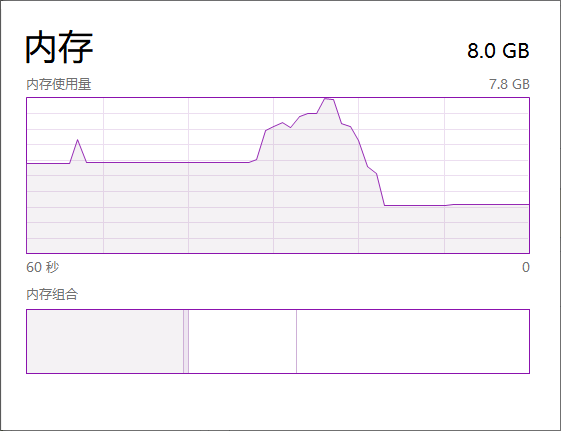
我认为我的代码一定有误,您能帮我吗?
谢谢!
0 个答案:
没有答案
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?