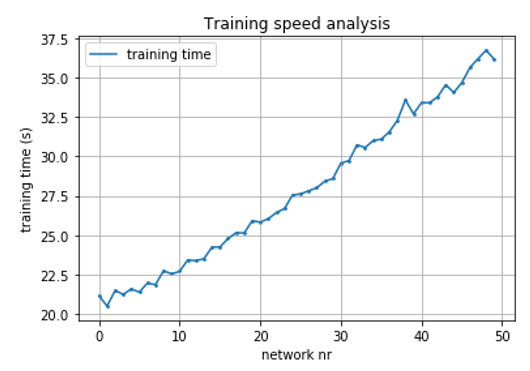
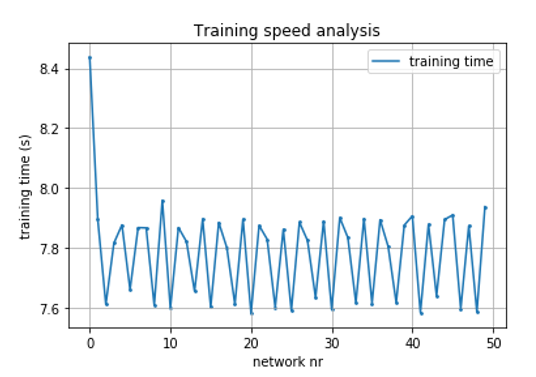
为什么要训练Keras模型 每次more time都在Jupyter笔记本中建立新模型时。退出Jupyter / Python并重新启动将重置训练速度。每次The scatterplot看起来都一样。
我正在使用Keras'Sequential'来训练普通的MLP,其输入层包含大约6000个要素,3个隐藏的relu层(大小分别为2500、800、800),batchnorm和dropout,以及S型输出,没什么特别的。
我正在优化(使用GPyOpt,但是当我在简单的for循环中构建模型时,效果也会出现),每次输入引用时,我都会提供一个构建上述新Keras模型的函数。在该函数构建模型之前,它会调用函数limitmen(),因为否则我会遇到GPU内存问题:
def limit_mem():
"""
Clear GPU-memory and tensorflow session.
"""
K.get_session().close()
cfg = K.tf.ConfigProto()
cfg.gpu_options.allow_growth = True
K.set_session(K.tf.Session(config=cfg))
我在stackoverflow上搜索了here后发现了这个函数
def f_beta(precision, recall, beta):
f_beta_result = (1 + (beta ** 2)) * (precision * recall) / (((beta ** 2) * precision) + recall)
if isinstance(f_beta_result, np.ndarray):
f_beta_result[np.isnan(f_beta_result)] = 0
else:
if math.isnan(f_beta_result):
f_beta_result = 0
return f_beta_result
beta = 1.5 # define beta for f-score
class Metrics(Callback):
def on_train_begin(self, logs={}):
self.val_f1s = []
self.val_f2s = []
self.val_recalls = []
self.val_precisions = []
self.val_briers = []
def on_epoch_end(self, epoch, logs={}):
val_predict = (np.asarray(self.model.predict(X_val))).round()
val_targ = y_val
_val_precision, _val_recall, _val_f1, _support = precision_recall_fscore_support(val_targ, val_predict, labels=[0,1])
_val_f2 = f_beta(_val_precision[1], _val_recall[1], beta)
_val_brier = brier_score_loss(val_targ, val_predict)
# print(_val_precision)
self.val_f1s.append(_val_f1[1])
self.val_f2s.append(_val_f2)
self.val_recalls.append(_val_recall[1])
self.val_precisions.append(_val_precision[1])
self.val_briers.append(_val_brier)
# print (' — val_f1: %.3f — val_precision: %.3f — val_recall %.3f' % ( _val_f1[1], _val_precision[1], _val_recall[1]))
return
def return_metrics(self):
return self.val_f1s, self.val_f2s, self.val_recalls, self.val_precisions, self.val_briers, np.array(self.val_f2s).argmax()
metrics = Metrics()
# create model
def build_model(dropout=0.9, dense1=2500, dense2=800, dense3=800, lr=0.0001):
model = Sequential()
# first layer
model.add(Dense(dense1, input_dim=X_train.shape[1], init='uniform'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(dropout))
# second layer
model.add(Dense(dense2, init='uniform'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(dropout))
# third layer
model.add(Dense(dense3, init='uniform'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(dropout))
# final layer
model.add(Dense(1, activation='sigmoid'))
# Compile model
adam = Adam(lr)
model.compile(loss='binary_crossentropy', optimizer=adam, metrics=['accuracy', 'mae'])
return model
这或多或少是构建keras模型的循环:
for i in range(self.cycle):
# actually build model
t_before = time.time()
self.keras_model = build_model(dropout, dense1, dense2, dense3, lr)
# train model
self.hist = self.keras_model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=self.epochs,
batch_size=1024, verbose=0, callbacks=[metrics],
class_weight={ 0 : 1, 1 : weight1 })
t_after = time.time()
有人经历过吗?你需要更多的信息?还是这是一个众所周知的问题,需要一个简单的解决方案(或根本没有解决方案)?
答案 0 :(得分:0)
{kind=link}
{kind=link}