使用Keras预测下一个单词
我有一个序列预测问题,我将其作为语言模型进行处理。 我的数据包含4个选择(1-4)和一个奖励(1-100)。 我开始使用Keras,但不确定它是否具有所需的灵活性。
- 这是模型架构的外观:
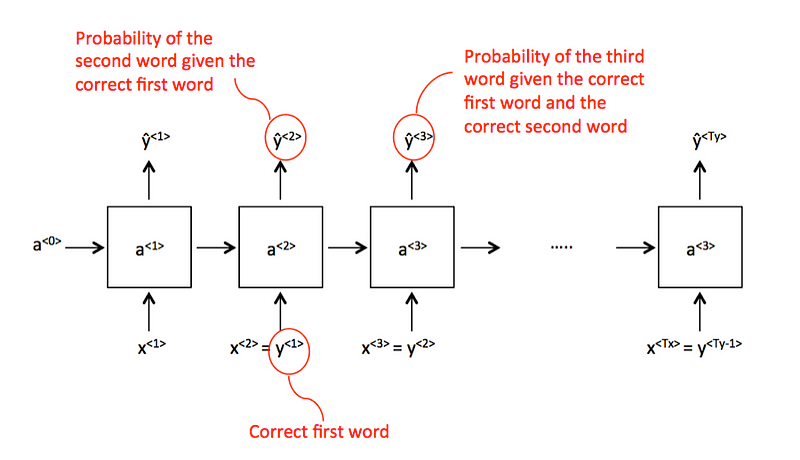
我不确定测试阶段。一种选择是采样:
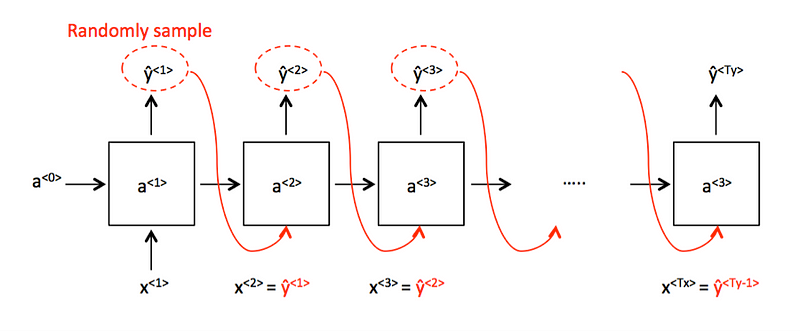
我不确定如何评估此选项与测试集的输出。
另一种选择是给训练后的模型一个序列,让它绘制最后的时间步长值(例如给出句子和预测最后一个单词)-但仍然具有x = t_hat。
在Keras中可能吗?我找不到这样的例子。
- 除了传递先前的选择(或先前的单词)作为输入外,我还需要传递第二个功能,即奖励值。选择是一键编码,如何将一个数字和编码后的向量相加?
编辑: 这是训练阶段(尚未进行采样):
model = Sequential()
model.add(LSTM(64, input_shape=(seq_length, X_train.shape[2]) , return_sequences=True))
model.add(Dense(y_cat_train.shape[2], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_cat_train, epochs=100, batch_size=10, verbose=2)
1 个答案:
答案 0 :(得分:0)
Google设计了Keras来满足各种需求,它应该满足您的需求-是的。
在您的情况下,您正在使用任意数量的单位(通常为64或128)的LSTM单元,其中包括:a <1> ,a <2> ,a <3> ... a
我建议您检查https://keras.io/utils/#to_categorical函数以将您的数据转换为“一次性”编码格式。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?