将jpeg中的表提取到R中的数据框中
我有以下两个链接:
https://pbs.twimg.com/media/Dv3pIsIUwAEdu--.jpg:large
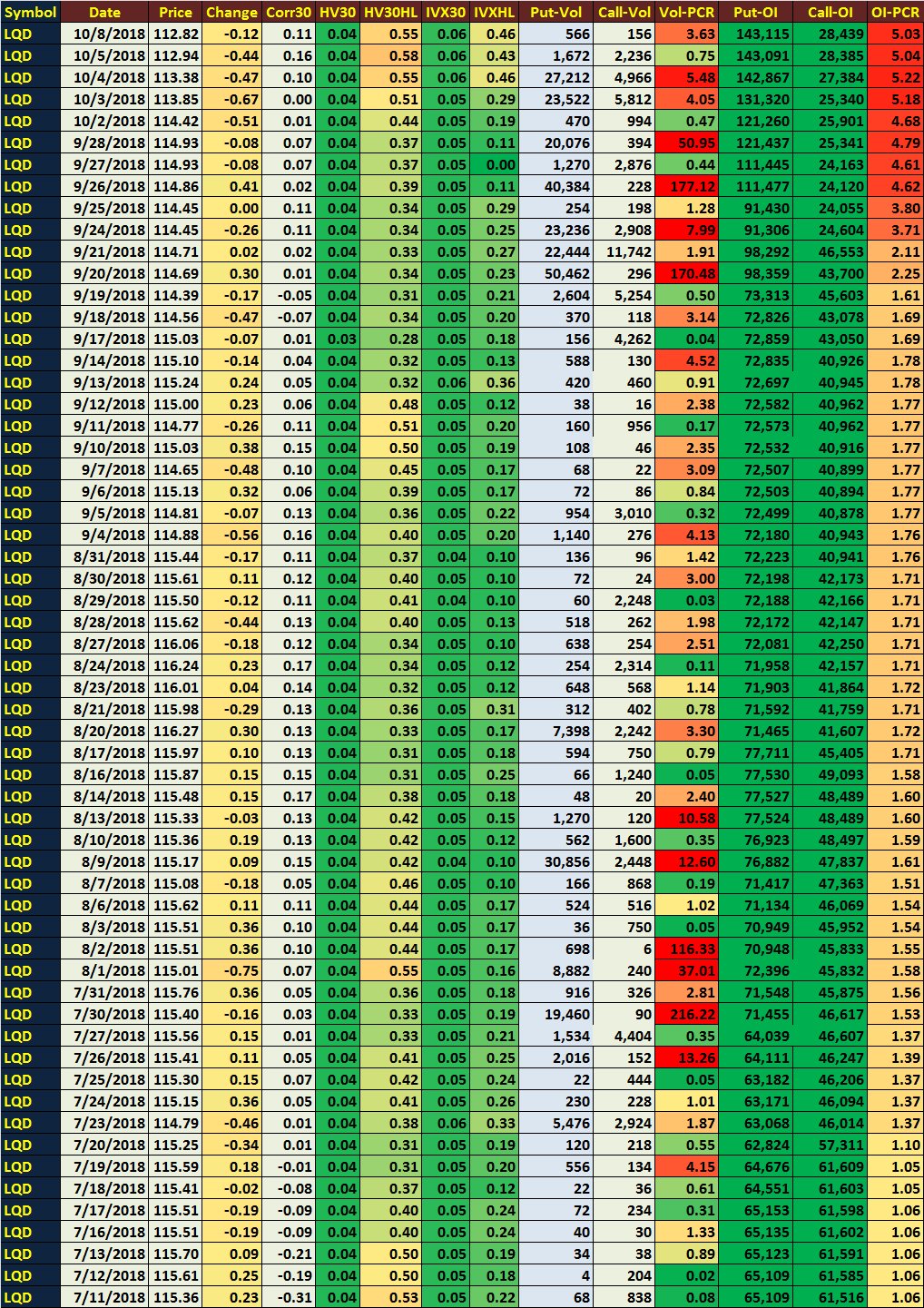{kind=link}
https://pbs.twimg.com/media/Dv3lKfjV4AAkIpY.jpg:large
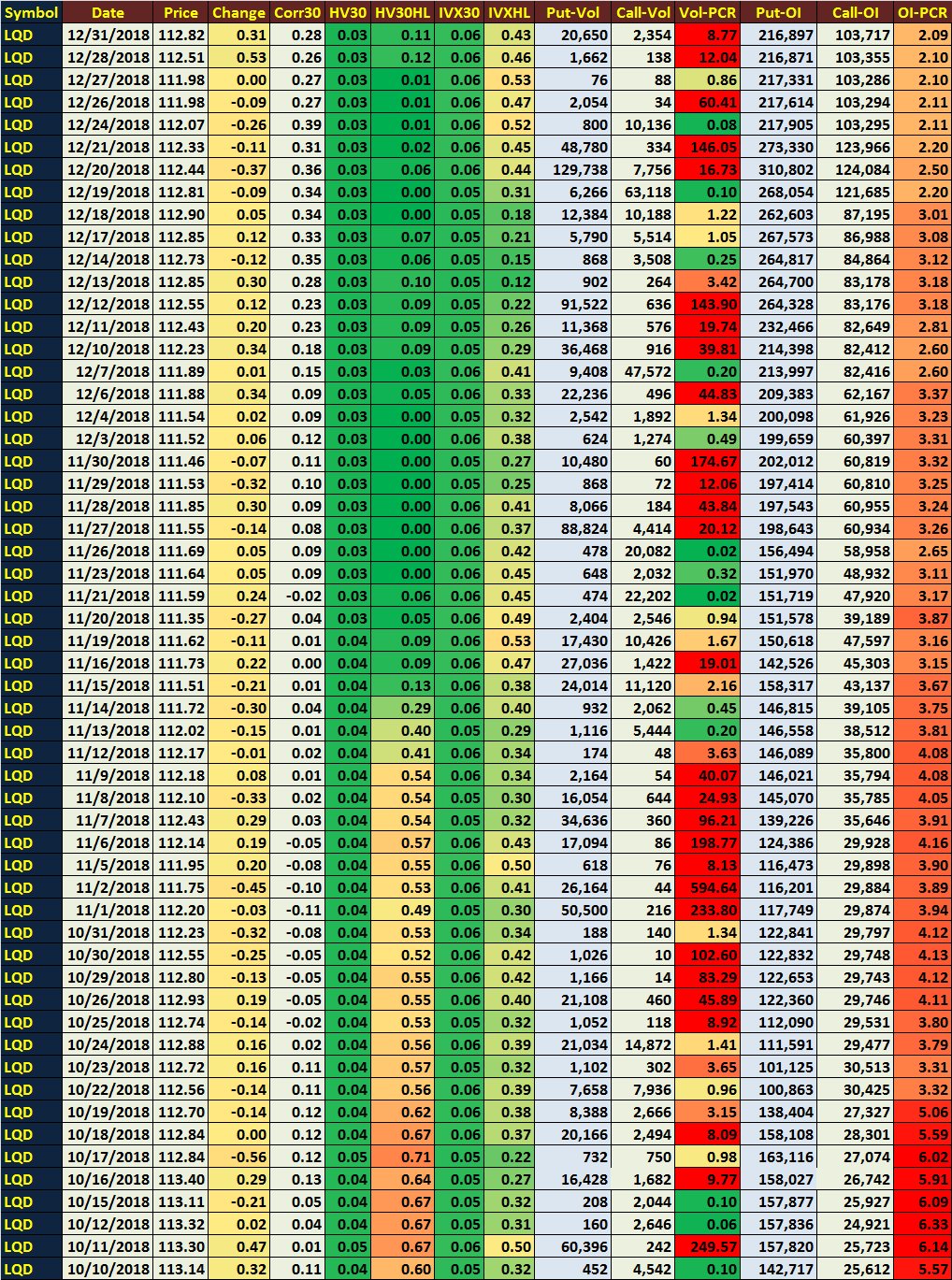{kind=link}
数据以表格格式显示,但是作为jpeg,我想捕获此信息并将其转换为df或小标题。
我尝试使用tesseract,但效果不佳,我的代码如下:
library(tesseract)
text <- ocr_data(input_1, engine = eng)
text <- tesseract::ocr_data("https://pbs.twimg.com/media/Dv3lKfjV4AAkIpY.jpg:large", engine = eng)
有什么想法吗?
1 个答案:
答案 0 :(得分:1)
尝试一些先决条件,例如转换为黑/白并删除网格。这应该可以帮助您开始:
library(magrittr)
library(magick)
#> Linking to ImageMagick 6.9.9.38
#> Enabled features: cairo, fontconfig, freetype, fftw, ghostscript, lcms, pango, rsvg, webp, x11
#> Disabled features:
# download file
url <- "https://pbs.twimg.com/media/Dv3pIsIUwAEdu--.jpg:large"
download.file(url, destfile = "table.jpg")
# convert to black and white
convert_bw <- 'convert table.jpg -fill white -fuzz 20% +opaque "#000000" table_bw.jpg'
system(convert_bw)
# remove grid
remove_grid <- "convert table_bw.jpg -negate -define morphology:compose=darken -morphology Thinning 'Rectangle:1x80+0+0<' -negate table_wo_grid.jpg"
system(remove_grid)
# read img and ocr
data <- image_read("table_wo_grid.jpg") %>%
image_crop(geometry_area(0, 0, 80, 25)) %>%
image_ocr() %>%
stringi::stri_split(fixed = "\n")
head(data[[1]])
#> [1] "10/3/2013 112.32 -0.12 0.11 0.04 0.55 0.05 0.45 555 155 5.55 143,115 23,439 505"
#> [2] "10/5/2013 112.94 -0.44 0.15 0.04 0.53 0.05 0.45 1,572 2,255 0.75 143,091 23,335 504"
#> [3] "10/4/2013 115.53 -0.47 0.10 0.04 0.55 0.05 0.45 27,212 4,955 775,473 142,357 27,334 5 22"
#> [4] "10/5/2013 115.35 -0.57 0.00 0.04 0.51 0.05 0.29 25,522 5,312 4.05 131,320 25,340 513"
#> [5] "10/2/2013 114.42 -0.51 0.01 0.04 0.44 0.05 0.19 470 994 0.47 121,250 25,901 74.53"
#> [6] "9/23/2013 11495 -0.03 0.07 0.04 0.57 0.05 0.11 20,075 594 50 55 121,437 25,341 774773"
由reprex package(v0.2.1)于2019-01-02创建
编辑 无需系统调用即可进行转换
library(magrittr)
library(magick)
#> Linking to ImageMagick 6.9.9.38
#> Enabled features: cairo, fontconfig, freetype, fftw, ghostscript, lcms, pango, rsvg, webp, x11
#> Disabled features:
# download file
url <- "https://pbs.twimg.com/media/Dv3pIsIUwAEdu--.jpg:large"
download.file(url, destfile = "table.jpg")
# preprocessing
img <- image_read("table.jpg") %>%
image_transparent("white", fuzz=82) %>%
image_background("white") %>%
image_negate() %>%
image_morphology(method = "Thinning", kernel = "Rectangle:20x1+0+0^<") %>%
image_negate() %>%
image_crop(geometry_area(0, 0, 80, 25))
img

# read img and ocr
data <- img %>%
image_ocr()
# some wrangling
data %>%
stringi::stri_split(fixed = "\n") %>%
purrr::map(~ stringi::stri_split(str = ., fixed = "‘")) %>%
.[[1]] %>%
purrr::map_df(~ tibble::tibble(Date = .[1], Price = .[2], Change = .[3])) %>%
dplyr::glimpse()
#> Observations: 61
#> Variables: 3
#> $ Date <chr> "10/3/2013", "10/5/2013", "10/4/2013", "10/5/2013", "10...
#> $ Price <chr> "11232", "11294", "11553", "11535", "114.42", "11495", ...
#> $ Change <chr> " -0.12", " -0.44", " -0.47", " -0.57", " -0.51", " -0....
由reprex package(v0.2.1)于2019-01-03创建
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?