为了复制,我喜欢为每个数据帧保留一个带有元数据的码本。数据码本是:
书面或计算机化列表,提供将包含在数据库中的变量的清晰而全面的描述。 Marczyk等人(2010)
我想记录变量的以下属性:
- 名称
- 描述(标签,格式,比例等)
- 来源(例如世界银行)
- 源媒体(访问的网址和日期,CD和ISBN,或其他)
- 磁盘上源数据的文件名(合并代码簿时有帮助)
- 注释
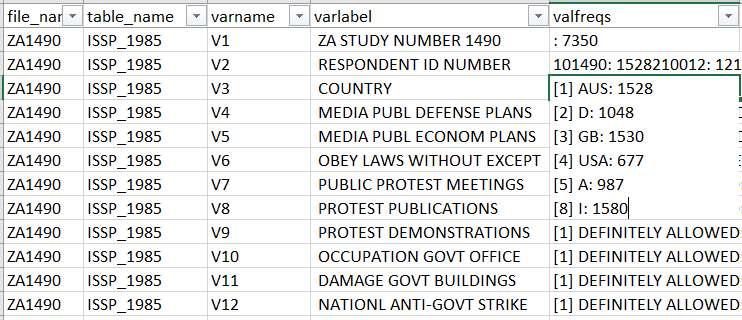
例如,我正在实现这一目标,用8个变量记录数据框 mydata1 中的变量:
code.book.mydata1 <- data.frame(variable.name=c(names(mydata1)),
label=c("Label 1",
"State name",
"Personal identifier",
"Income per capita, thousand of US$, constant year 2000 prices",
"Unique id",
"Calendar year",
"blah",
"bah"),
source=rep("unknown",length(mydata1)),
source_media=rep("unknown",length(mydata1)),
filename = rep("unknown",length(mydata1)),
notes = rep("unknown",length(mydata1))
)
我为每个读过的数据集写了不同的代码簿。当我合并数据帧时,我还将合并其相关代码簿的相关方面,以记录最终数据库。我这样做主要是复制粘贴上面的代码并更改参数。
答案 0 :(得分:7)
您可以使用attr函数向任何R对象添加任何特殊属性。 E.g:
x <- cars
attr(x,"source") <- "Ezekiel, M. (1930) _Methods of Correlation Analysis_. Wiley."
并查看对象结构中的给定属性:
> str(x)
'data.frame': 50 obs. of 2 variables:
$ speed: num 4 4 7 7 8 9 10 10 10 11 ...
$ dist : num 2 10 4 22 16 10 18 26 34 17 ...
- attr(*, "source")= chr "Ezekiel, M. (1930) _Methods of Correlation Analysis_. Wiley."
并且还可以使用相同的attr函数加载指定的属性:
> attr(x, "source")
[1] "Ezekiel, M. (1930) _Methods of Correlation Analysis_. Wiley."
如果只向数据框添加新案例,则给定属性不会受到影响(请参阅:str(rbind(x,x)),而更改结构将会增加给定属性(请参阅:str(cbind(x,x)))。
根据评论更新
如果要列出所有非标准属性,请检查以下内容:
setdiff(names(attributes(x)),c("names","row.names","class"))
这将列出所有非标准属性(标准是:名称,行名,数据框中的类)。
基于此,您可以编写一个简短的函数来列出所有非标准属性以及值。以下确实有效,但不是很整齐......你可以改进它并组成一个函数:)
首先,定义uniqe(=非标准)属性:
uniqueattrs <- setdiff(names(attributes(x)),c("names","row.names","class"))
制作一个包含名称和值的矩阵:
attribs <- matrix(0,0,2)
循环遍历非标准属性并在矩阵中保存名称和值:
for (i in 1:length(uniqueattrs)) {
attribs <- rbind(attribs, c(uniqueattrs[i], attr(x,uniqueattrs[i])))
}
将矩阵转换为数据框并命名列:
attribs <- as.data.frame(attribs)
names(attribs) <- c('name', 'value')
以任何格式保存,例如:
write.csv(attribs, 'foo.csv')
关于变量标签的问题,请检查包 foreign 中的read.spss函数,因为它完全符合您的需要:将值标签保存在attrs部分。主要思想是attr可以是数据框或其他对象,因此您不需要为每个变量创建唯一的“attr”,而只需要创建一个(例如命名为“varable标签”)并将所有信息保存在那里。您可以调用:attr(x, "variable.labels")['foo']其中'foo'代表所需的变量名称。但请查看上面引用的函数以及导入的数据框的属性以获取更多详细信息。
我希望这些可以帮助你以比我上面尝试的更简洁的方式编写所需的功能! :)
答案 1 :(得分:5)
更高级的版本是使用S4类。例如,在生物传导器中,ExpressionSet用于存储具有其相关实验元数据的微阵列数据。
Section 4.4中描述的MIAME对象看起来非常类似于你所追求的:
experimentData <- new("MIAME", name = "Pierre Fermat",
lab = "Francis Galton Lab", contact = "pfermat@lab.not.exist",
title = "Smoking-Cancer Experiment", abstract = "An example ExpressionSet",
url = "www.lab.not.exist", other = list(notes = "Created from text files"))
答案 2 :(得分:4)
此处comment()功能可能很有用。它可以设置和查询对象的注释属性,但具有其他不打印的常规属性的优点。
dat <- data.frame(A = 1:5, B = 1:5, C = 1:5)
comment(dat$A) <- "Label 1"
comment(dat$B) <- "Label 2"
comment(dat$C) <- "Label 3"
comment(dat) <- "data source is, sampled on 1-Jan-2011"
给出:
> dat
A B C
1 1 1 1
2 2 2 2
3 3 3 3
4 4 4 4
5 5 5 5
> dat$A
[1] 1 2 3 4 5
> comment(dat$A)
[1] "Label 1"
> comment(dat)
[1] "data source is, sampled on 1-Jan-2011"
合并示例:
> dat2 <- data.frame(D = 1:5)
> comment(dat2$D) <- "Label 4"
> dat3 <- cbind(dat, dat2)
> comment(dat3$D)
[1] "Label 4"
但是对dat()
> comment(dat3)
NULL
所以这些操作需要明确处理。要真正做到你想要的,你可能需要编写你使用的特殊版本的函数来维护提取/合并操作期间的注释/元数据。或者,您可能希望研究生成自己的对象类 - 例如,包含数据框的列表和包含元数据的其他组件。然后编写所需函数的方法来保存元数据。
这些行的一个例子是zoo包,它为一个时间序列生成一个列表对象,其中包含保存排序和时间/日期信息等的额外组件,但是从子集等的角度来看仍然像普通对象一样工作,因为作者为[等函数提供了方法。
答案 3 :(得分:4)
从2020年开始,有一些R包直接专用于可能满足您需求的代码本。
密码本软件包是一个综合的软件包,可以生成不同格式的密码本(具有公共属性和描述性统计信息)。它有一个website和一篇论文(Arslan,2019年,How to Automatically Document Data With the codebook Package to Facilitate Data Reuse。该论文在图1中还比较了不同方法。
这是example。
dataspice 软件包(由rOpenSci提供功能)专门用于生成元数据,这些元数据可以由网络上的搜索引擎找到。它有一个website。
这是example。
dataMaid 程序包可以生成包含元数据和描述性统计信息的报告,并且可以执行某些检查。它位于CRAN和GitHub上,并且具有JSS论文(Petersen&Ekstrøm,2019年,dataMaid: Your Assistant for Documenting Supervised Data Quality Screening in R)。
这是example。
memisc 软件包具有许多用于处理调查数据的功能,并且还具有一个代码簿功能。它有一个website。
这是example。
还有一个blog post by Marta Kołczyńska,它具有轻量级功能,可以生成带有元数据的数据框(可以将其导出,例如导出到Excel文件)。
这是example。
答案 4 :(得分:3)
我如何做到这一点有点不同,而且技术性显着降低。我通常遵循以下指导原则:如果文本不是设计为对计算机有意义并且仅对人类有意义,则它属于源代码中的注释。
这可能感觉相当“低技术”,但有一些很好的理由这样做:
显然,携带元数据和对象有一些真正的好处。如果您的工作流程使上述要点不那么密切,那么为数据结构创建元数据附件可能会很有意义。我的意图只是分享为什么可以考虑采用“低技术”评论的方法。
{kind=link}
{kind=link}