这是我的tensorflow keras模型,(如果让事情变得艰难,则可以忽略辍学层)
import tensorflow as tf
optimizers = tf.keras.optimizers
Sequential = tf.keras.models.Sequential
Dense = tf.keras.layers.Dense
Dropout = tf.keras.layers.Dropout
to_categorical = tf.keras.utils.to_categorical
model = Sequential()
model.add(Dense(256, input_shape=(20,), activation="relu"))
model.add(Dropout(0.1))
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.1))
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.1))
model.add(Dense(3, activation="softmax"))
adam = optimizers.Adam(lr=1e-3) # I don't mind rmsprop either
model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
并且我将模型的结构和权重另存为
model.save("sim_score.h5", overwrite=True)
model.save_weights('sim_score_weights.h5', overwrite=True)
做model.predict(X_test)时,我得到[0.23, 0.63, 0.14],这是3个输出类别的预测概率。
我如何形象地看待最初的20个体重/重要性 该模型具有3个输出softmax吗?
例如,我的第二列对最终结果的影响可以忽略不计,而第五列对输出预测的影响则比第20列大3倍。不管第5列的绝对影响是什么,只要弄清楚相对重要性就足够了,例如5th column = 0.3, 20th column = 0.1等等,对于20 x 3 matrix如此。
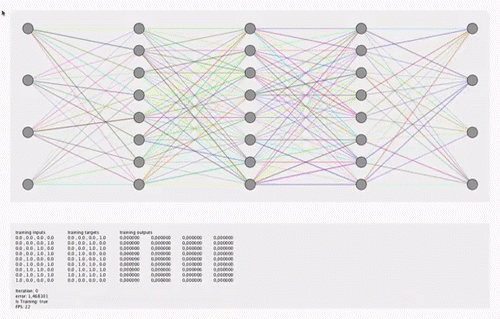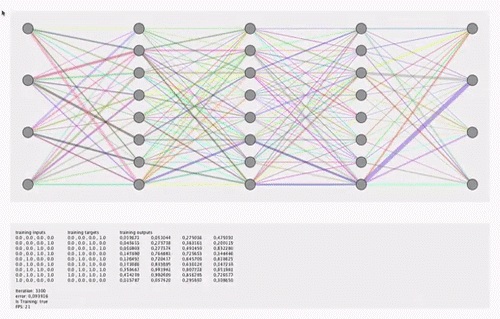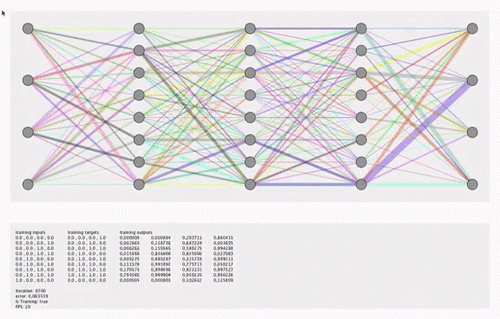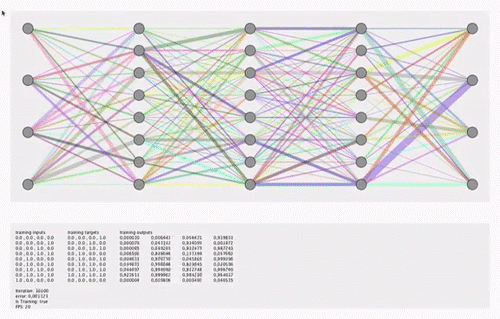
关于直觉,请参见此animation或Tensorflow playground。可视化不必显示训练过程中权重的变化,而可以显示训练结束时权重的快照图像。
实际上,该解决方案甚至不必是可视化的,它可以 甚至是20个元素x 3个输出的数组,每个元素的相对重要性 相对于其他功能,该功能没有输出3的softmax和重要性。
获得中间层的重要性只是一个额外的奖励。
我之所以要可视化这20个功能,是出于透明目的(当前该模型感觉像一个黑匣子)。我对matplotlib,pyplot和seaborn感到满意。 我也知道Tensorboard,但是找不到带有Softmax的简单Dense Relu网络的任何示例。
我觉得获取20 x 3权重的一种耗时方法是通过发送各种输入并尝试从20 features到0 - 1的域0.5中搜索3 to the power of 20以此来推断特征的重要性(如果我添加的特征越多,则可能会有3.4 billion〜= String[] parts = S1.split("@");
final String lastItem = parts[parts.length - 1];
的样本空间,并且指数变差),然后应用条件概率对相对权重进行逆向工程,但不确定通过TensorBoard或某些自定义逻辑是否有更简单/优化的方法。
有人可以帮助模型可视化/计算20个要素的20 x 3 = 60相对权重而没有带有代码段的3个输出,或者提供有关如何实现此目的的参考吗?
答案 0 :(得分:2)
我遇到了类似的问题,但是我更关心模型参数(权重和偏差)的可视化,而不是模型特征[,因为我也想探索和查看黑匣子< / strong>]。
例如,以下是具有2个隐藏层的浅层神经网络的摘要。
model = Sequential()
model.add(Dense(128, input_dim=13, kernel_initializer='uniform', activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(64, kernel_initializer='uniform', activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(64, kernel_initializer='uniform', activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(8, kernel_initializer='uniform', activation='softmax'))
# Compile model
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Using TensorBoard to visualise the Model
ks=TensorBoard(log_dir="/your_full_path/logs/{}".format(time()), histogram_freq=1, write_graph=True, write_grads=True, batch_size=10)
# Fit the model
model.fit(X, Y, epochs = 64, shuffle = True, batch_size=10, verbose = 2, validation_split=0.2, callbacks=[ks])
要使参数可视化,需要牢记一些重要的事情:
始终确保在model.fit()函数中有一个validation_split [无法直观显示其他直方图]。
确保始终 histogram_freq> 0 的值![否则将不会计算直方图]。
必须在model.fit()中将TensorBoard的回调指定为列表。
完成一次; goto cmd并输入以下命令:
tensorboard --logdir = logs /
这为您提供了一个本地地址,您可以使用该地址在Web浏览器上访问TensorBoard。 所有直方图,分布,损失和准确性功能都将以图表形式提供,并且可以从顶部的菜单栏中进行选择。
希望这个答案能给出有关可视化模型参数的过程的提示(由于上述几点无法同时使用,我本人有些挣扎)。
请告诉我是否有帮助。
下面是keras文档链接供您参考:
{kind=link}