我正尝试在下一页上抓取表格数据 HKJC LINK
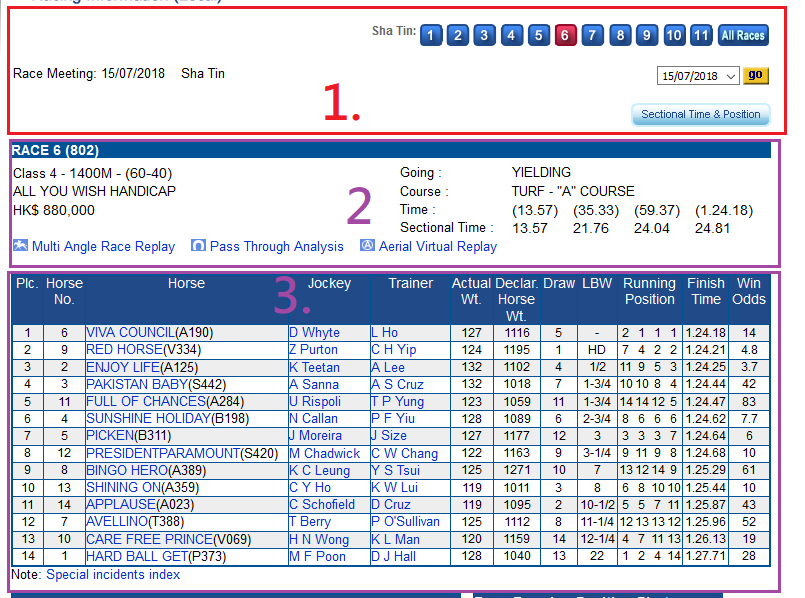
我可以读取表2和3,但是表1返回“ NULL”,我检查了包含数据(see the picture)的源代码
library(XML)
url = "http://racing.hkjc.com/racing/info/meeting/Results/english/Local/20180715/ST/6"
sample=readHTMLTable(url,which=2,encoding = "UTF-8")
head(sample,1)
有什么想法吗?
答案 0 :(得分:0)
library(XML)
scrapescrape <- function(x) {
link <- paste0("http://www.racingpost.com/horses/horse_home.sd?horse_id=",x)
tryCatch(readHTMLTable(link, which=2), error=function(e){NA})
}
}
ids <- c(896119, 766254, 790946, 556341, 62736, 660506, 486791, 580134, 0011, 580134)
lst <- lapply(ids, scrapescrape)
str(lst)
{kind=link}