我有一个.jpg,.pdf和.png图像URL的数据库,它们代表房屋的平面图。我正在尝试使用pytesseract从图像中提取文本-目的是获得每个房屋的总面积(平方英尺或平方米)。
我是pytesseract的新手,在尝试使用image_to_string函数之前,尝试了多种不同的方法来更改下面的示例图像,但是每次结果都确实不准确。对于我尝试过的其他一些房屋,它运行得很好。这是基本功能,没有任何图像更改:
def simple_url_to_text(url):
urllib.urlretrieve(url, "url_test.jpg")
im = Image.open("url_test.jpg")
text = pytesseract.image_to_string(im)
return text
此功能非常适合此URL ...
https://lc.zoocdn.com/8487827a2ea1536001fcf007c6aa1fb04c2ed0b5.jpg
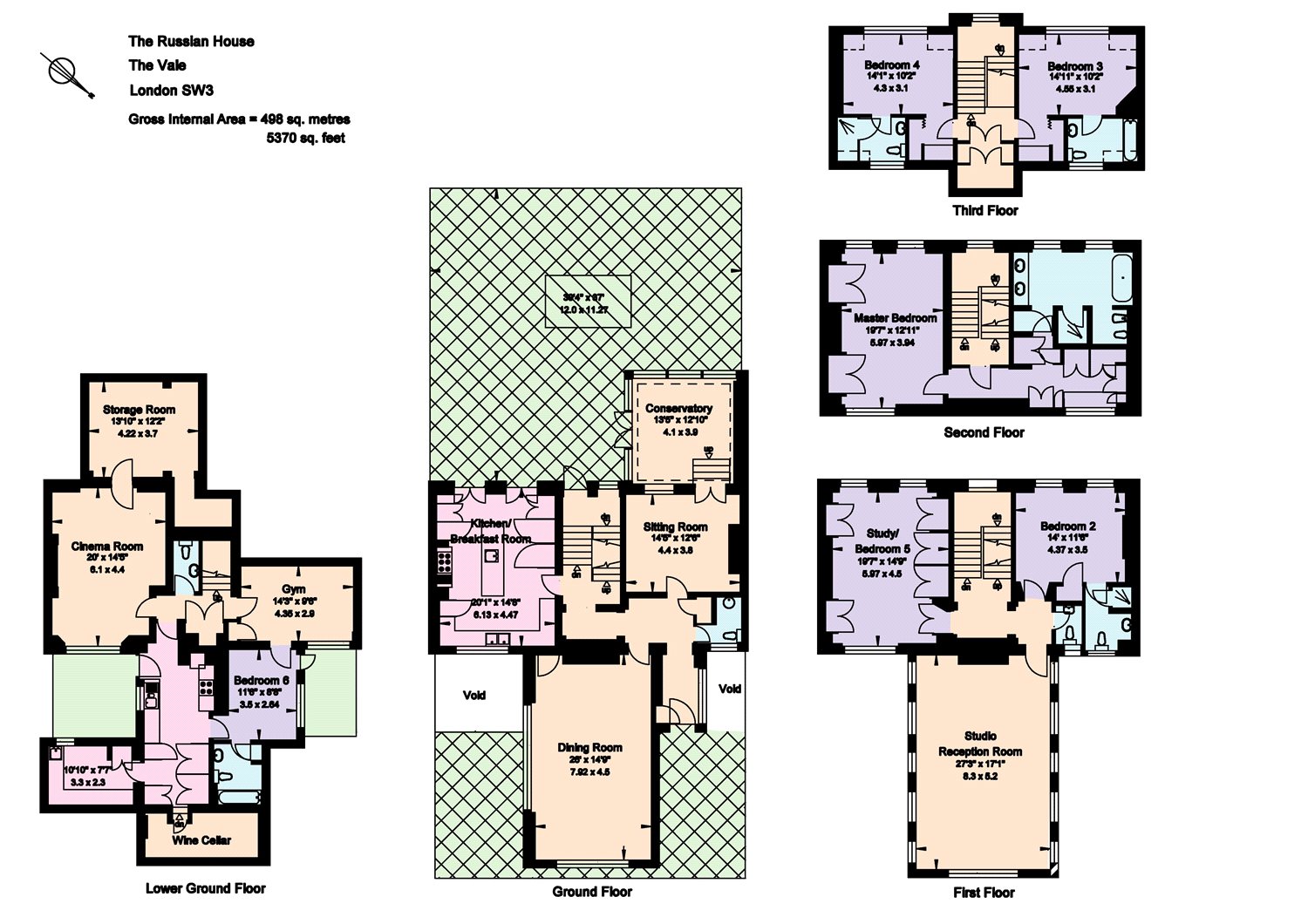
但是真的很糟糕... https://lc.zoocdn.com/e57c5a06c2c64904c077a0736e797ea7a6a71597.jpg
任何有关如何更改功能以使其在第二个URL上起作用的提示都将受到赞赏。
{kind=link}
{kind=link}