我有一个非常大的pandas DataFrame,有几千个代码,每个代码都有相关的成本(样本):
data = {'code': ['a', 'b', 'a', 'c', 'c', 'c', 'c'],
'cost': [10, 20, 100, 10, 10, 500, 10]}
df = pd.DataFrame(data)
我正在groupby级别创建一个code对象,即:
grouped = df.groupby('code')['cost'].agg(['sum', 'mean']).apply(pd.Series)
现在我真的需要向此grouped DataFrame添加一个新列,确定具有异常值成本的代码百分比。我最初的方法是这个外部函数(使用iqr中的scipy):
def is_outlier(s):
# Only calculate outliers when we have more than 100 observations
if s.count() >= 100:
return np.where(s >= s.quantile(0.75) + 1.5 * iqr(s), 1, 0).mean()
else:
return np.nan
编写此功能后,我在is_outlier上面的agg个参数中添加了groupby。这不起作用,因为我正在尝试评估is_outlier系列中每个元素的cost费率:
grouped = df.groupby('code')['cost'].agg(['sum', 'mean', is_outlier]).apply(pd.Series)
我尝试使用pd.Series.where,但它与np.where的功能不同。有没有办法修改我的is_outlier函数必须以cost系列为参数才能正确评估每个代码的异常值?还是我完全偏离了道路?
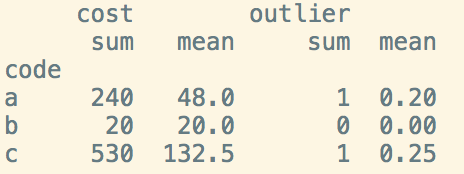
更新所需结果(减去此示例的最低观察要求):
>>> grouped
code sum mean is_outlier
0 'a' 110 55 0.5
1 'b' 20 20 0
2 'c' 530 132.5 0.25
注意:为了让我计算异常值,我的样本很糟糕,因为每个code分别有2个,1个和4个观察值。在生产数据框架中,每个代码都有数百或数千个观察结果,每个观察结果都与成本相关。在上面的示例结果中,is_outlier的值意味着,对于'a',两个观察中的一个在异常值范围内有成本,对于'c',四个观察中有一个观察到在异常值范围内的成本等 - 我试图通过在np.where()中分配1&0和#0并且取.mean()的{{1}}来在我的函数中重新创建它
.apply(pd.Series)才能<pandas.core.groupby.SeriesGroupBy object> resulting from into a DataFrame. is a pandas Series with all values of代for each代码, as generated from the代码operation (群组phase of拆分 if (navigator.geolocation.watchPosition(watchSuccess, watchError, watchOptions)) {
navigator.geolocation.getCurrentPosition(function(position) {
var pos = {
lat: position.coords.latitude,
lng: position.coords.longitude
};
map.setCenter(pos);
that.MyLocation = new google.maps.LatLng(pos);
}, function() {
});
} else {
// Browser doesn't support Geolocation
}
directionsService.route({
origin: this.MyLocation,
destination: this.Destination,
travelMode: 'DRIVING'
}, function(response, status) {
if (status === 'OK') {
directionsDisplay.setDirections(response);
} else {
window.alert('Directions request failed due to ' + status);
}
});
}
// watch user's position
// change marker location everytime position is updated
watchSuccess(position) {
var latLng = new google.maps.LatLng(position.coords.latitude, position.coords.longitude);
// set marker position
marker.setPosition(latLng);
} split-apply-combine`)
答案 0 :(得分:0)
# Loading Libraries
import pandas as pd;
import numpy as np;
# Creating Data set
data = {'code': ['a', 'b', 'a', 'c', 'c', 'c', 'c', 'a', 'a', 'a'],
'cost': [10, 20, 200, 10, 10, 500, 10, 10, 10, 10]}
df = pd.DataFrame(data)
def outlier_prop(df,name,group_by):
"""
@Packages required
import pandas as pd;
import numpy as np;
@input
df = original dataframe
name = This is the name column for which you want the dummy list
group_by = column to group by
@output
data frame with an added column 'outlier' containing the proportion of outliers
"""
# Step 1: Create a dict of values for each group
value_dict = dict()
for index,i in enumerate(df[group_by]):
if i not in value_dict.keys():
value_dict[i] = [df[name][index]]
else:
value_dict[i].append(df[name][index])
# Step 2: Calculate the outlier value for each group and store as a dict
outlier_thres_dict = dict()
unique_groups = set(df[group_by])
for i in unique_groups:
outlier_threshold = np.mean(value_dict[i]) + 1.5*np.std(value_dict[i])
outlier_thres_dict[i] = outlier_threshold
# Step 3: Create a list indicating values greater than the group specific threshold
dummy_list = []
for index,i in enumerate(df[group_by]):
if df[name][index] > outlier_thres_dict[i]:
dummy_list.append(1)
else:
dummy_list.append(0)
# Step 4: Add the list to the original dataframe
df['outlier'] = dummy_list
# Step 5: Grouping and getting the proportion of outliers
grouped = df.groupby(group_by).agg(['sum', 'mean']).apply(pd.Series)
# Step 6: Return data frame
return grouped
outlier_prop(df, 'cost', 'code')
https://raw.githubusercontent.com/magoavi/stackoverflow/master/50533570.png
{kind=link}