如果我输入以下内容
git show abckfirn49dj5ks94nsjy03hsev85esk9c32jt04
其中abckfirn49dj5ks94nsjy03hsev85esk9c32jt04是合法的提交哈希,git会向我显示类似下面的内容
commit abckfirn49dj5ks94nsjy03hsev85esk9c32jt04
Author: Bob Jenkins <bjenkins@example.com>
Date: Mon Apr 23 14:38:51 2018 -0700
Commit message
diff --git a/somefile.txt b/agent/somefile.txt
index 54fc0544b..b7ce493a5 100644
--- a/somefile.txt
+++ b/somefile.txt
@@ -137,7 +137,6 @@ end:
context
context
+ an added line
context
context
- a deleted line
那就是 - 它向我展示了提交哈希,提交作者,提交日期,提交消息,和unix补丁。
我理解unix补丁格式是对两个文件之间差异的描述,以允许unix patch命令重新应用这些差异的方式呈现
当我运行git show [commit hash]时 - git使用哪两个文件来生成补丁。我有理由相信一个是特定哈希的文件,但是另一个是
答案 0 :(得分:4)
当我运行
git show [commit hash]时 - git使用哪两个文件来生成补丁?
文件是index行标识的文件:
index 54fc0544b..b7ce493a5 100644
两个点左侧的哈希ID是(在本例中为缩写)父项中存储为 blob对象 1 的文件的哈希ID commit,右边的哈希ID是存储在子提交中的文件的哈希ID。 (请参阅下面的更多图片图。)子提交是您传递给git show的ID;父是其(单独)父提交。如果有多个父提交,git show默认会生成组合差异,index行将列出多个左侧哈希ID。
使用--full-index获取每个blob的完整哈希ID。注意,散列ID是(当前)40个十六进制字符,即来自集合[0-9a-f]。这些是应用于头文件前缀后跟文件内容的160位加密哈希的结果。因此,两个相同位的相同文件总是产生相同的散列ID,这使得Git很容易跳过两个相同的文件。一个重用其父提交中的大多数文件的提交,只需重新使用所有这些blob。
1 由于 blob 最初是在数据库术语中,是Binary Large OBject的缩写,所以这个单词对由冗余部门提供给你。
图片可能更具说明性。想象一下提交是一个包含哈希ID列表的框。哈希ID标识文件在仓库中的位置。盒子本身也有自己的数据:你的名字(和电子邮件地址等),它的父提交等等;并且该框获取一个哈希ID,以便可以在仓库中找到该框:
fe0a9eaf31dd0c349ae4308498c33a5c3794b293 (a commit)
+--------------------------------------------------+
| parent: 8b026edac3104ecc40a68fd58b764fb3c717babb |
| author: ... |
| more stuff: ... |
| contents: (long list of hash IDs) |
+--------------------------------------------------+
8b026edac3104ecc40a68fd58b764fb3c717babb (a commit)
+--------------------------------------------------+
| parent: ... |
| ... |
+--------------------------------------------------+
...
f17af66a97c8097ab91f074478c4a5cb90425725 (a blob)
+--------------------------------------------------+
| Git - fast, scalable, distributed revision contr |
| ol system\n===================================== |
| ...
:
commit 框最终(实际上通过中间框)包含文件名和哈希ID。 blob 框包含实际的文件数据,如上面引用的Git&#39; README.md。具有不同box-ID标签的两个不同提交可以包含相同的文件,只需在相同的文件名下列出相同的哈希ID即可。如果两个不同的提交列出不同的文件内容,但名称相同,git diff将(通常) 2 比较这两个文件并生成修改的修补说明一个文件到另一个。
2 Git通常假设提交README.md中的文件A是&#34;相同的文件&#34;在提交README.md中为B。如果您重命名文件,Git必须找到一个内容足够相似的文件,以将其标识为重命名操作。您还可以告诉git diff 打破文件的关联,如果它们看起来太过变化&#34;。这些都不是你需要知道的事情使用 Git,至少在开始时。
答案 1 :(得分:3)
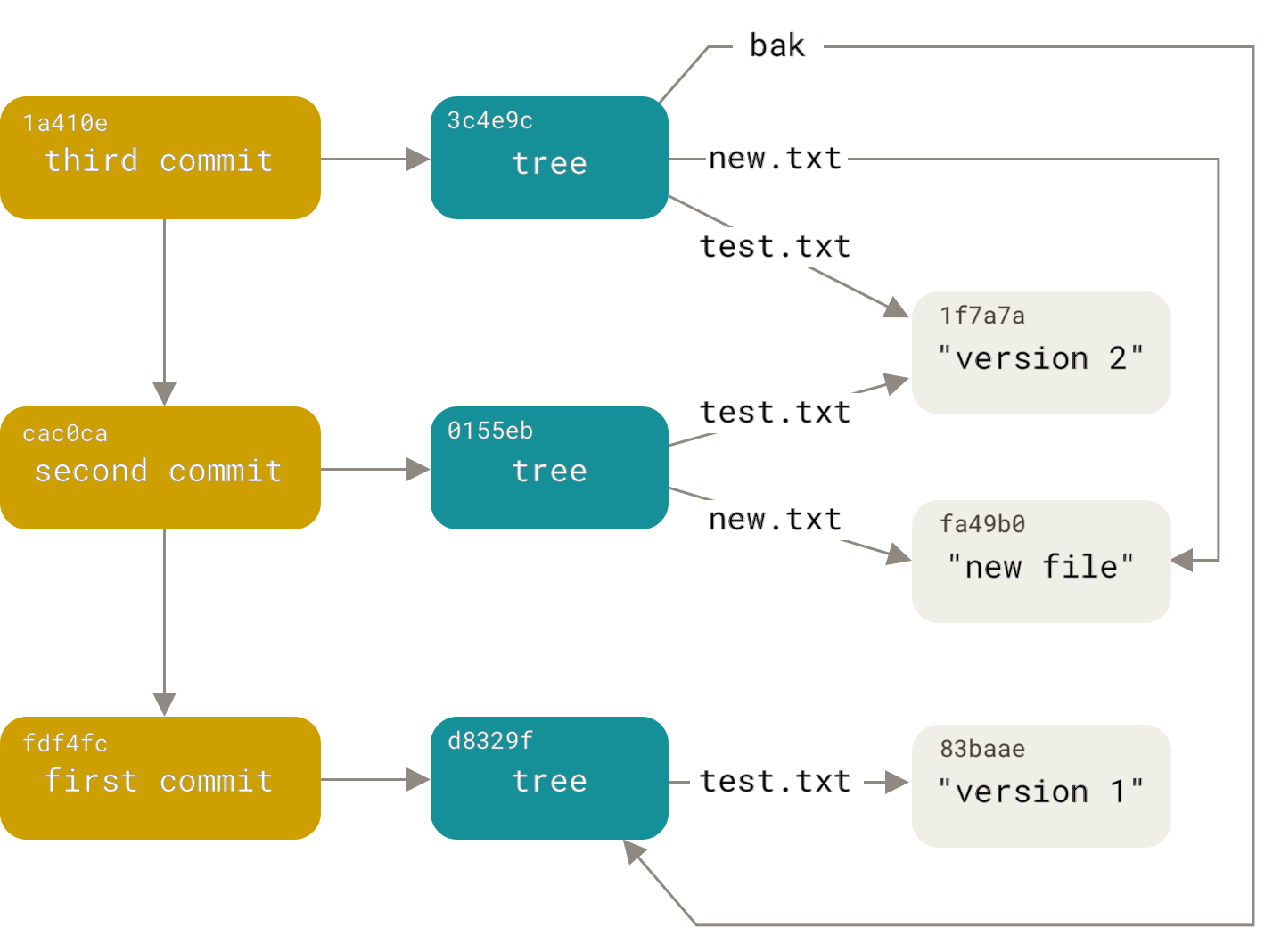
每个提交对象引用一个树(最终告诉它该文件的哪个版本对应于该提交)和指向前一个提交对象的指针。
散列abckfirn49dj5ks94nsjy03hsev85esk9c32jt04对应于其中一个提交对象,并且此对象的标题中将有一个parent字段指向其前一个。
如果您对这一切的工作原理感兴趣,我推荐此页:
https://git-scm.com/book/en/v2/Git-Internals-Git-Objects
特别是这个图:
https://git-scm.com/book/en/v2/images/data-model-3.png
(故意不热链接)
编辑:还有git社区书:http://shafiulazam.com/gitbook/1_the_git_object_model.html
答案 2 :(得分:1)
第一个文件是PFile(表示项目文件夹中当前文件的变量术语)。应用该提交后,第二个文件是PFile。
当前HEAD的文件?
git log <hash>...HEAD --stat <file>
三个点很重要,例如:
git log 1c9fd7cb16df91a03dc43cea98ff05730ba51b5c...HEAD --stat gc/base/MemorySubSpace.cpp
如果没有显示任何内容,则表示该文件是PFile(当前头),否则将打印一个替换Pfile的提交列表。
看到git是如何工作的(相同文件的哈希值相同),除非实际修改了PFile,否则第二个文件将不会在以后的所有提交中被取代。
要验证将<hash>替换为<hash>~1,您将在列表中看到您当前的提交。
{kind=link}