像属性一样访问dict键?
我觉得以obj.foo代替obj['foo']访问dict密钥更加方便,所以我写了这个代码段:
class AttributeDict(dict):
def __getattr__(self, attr):
return self[attr]
def __setattr__(self, attr, value):
self[attr] = value
但是,我认为必须有一些原因,Python不提供开箱即用的功能。以这种方式访问dict密钥会有什么警告和陷阱?
27 个答案:
答案 0 :(得分:257)
最好的方法是:
class AttrDict(dict):
def __init__(self, *args, **kwargs):
super(AttrDict, self).__init__(*args, **kwargs)
self.__dict__ = self
一些专业人士:
- 它确实有用!
- 没有字典类方法被遮蔽(例如
.keys()工作正常) - 属性和项目始终同步
- 尝试正确访问不存在的键作为属性会引发
AttributeError而不是KeyError
缺点:
- 像
.keys()这样的方法不如果被传入数据覆盖就会正常工作 - 在Python中导致memory leak< 2.7.4 / Python3< 3.2.3
- Pylint选择了
E1123(unexpected-keyword-arg)和E1103(maybe-no-member)的香蕉
- 对于不熟悉的人来说,这似乎是纯粹的魔法。
关于其工作原理的简短说明
- 所有python对象在内部将其属性存储在名为
__dict__的字典中。 - 不要求内部字典
__dict__需要“只是一个简单的字典”,因此我们可以将dict()的任何子类分配给内部字典。 - 在我们的例子中,我们只是分配我们实例化的
AttrDict()实例(就像我们在__init__中一样)。 - 通过调用
super()的{{1}}方法,我们确保它(已经)的行为与字典完全相同,因为该函数调用所有字典实例化代码。 / LI>
Python不提供开箱即用的此功能的一个原因
如“cons”列表中所述,这将存储键的命名空间(可能来自任意和/或不受信任的数据!)与内置dict方法属性的命名空间相结合。例如:
__init__()答案 1 :(得分:121)
如果使用数组表示法,则可以将所有合法字符串字符作为键的一部分。
例如,obj['!#$%^&*()_']
答案 2 :(得分:71)
从This other SO question开始,有一个很好的实现示例可以简化现有代码。怎么样:
class AttributeDict(dict):
__getattr__ = dict.__getitem__
__setattr__ = dict.__setitem__
更加简洁,并且不会留下任何额外的空间进入您的__getattr__和__setattr__功能。
答案 3 :(得分:62)
我在哪里回答被问到的问题
为什么Python没有开箱即用?
我怀疑它与Zen of Python有关:"应该有一个 - 最好只有一个 - 显而易见的方法。"这将创建两种显而易见的方法来访问词典中的值:obj['key']和obj.key。
警告和陷阱
这些包括代码中可能缺乏清晰度和混淆。也就是说,以下内容可能会让某人其他混淆,如果您暂时不再使用该代码,那么他们将在以后维护您的代码,甚至是您。同样,来自Zen:"可读性计数!"
>>> KEY = 'spam'
>>> d[KEY] = 1
>>> # Several lines of miscellaneous code here...
... assert d.spam == 1
如果d被实例化或 KEY被定义或 d[KEY]被分配到远离d.spam的地方正在使用它,它很容易导致对正在做什么的混淆,因为这不是常用的习语。我知道它有可能使我迷惑。
另外,如果您按如下方式更改KEY的值(但错过更改d.spam),您现在可以获得:
>>> KEY = 'foo'
>>> d[KEY] = 1
>>> # Several lines of miscellaneous code here...
... assert d.spam == 1
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
AttributeError: 'C' object has no attribute 'spam'
IMO,不值得努力。
其他项目
正如其他人所说,你可以使用任何可散列对象(不仅仅是字符串)作为dict键。例如,
>>> d = {(2, 3): True,}
>>> assert d[(2, 3)] is True
>>>
是合法的,但
>>> C = type('C', (object,), {(2, 3): True})
>>> d = C()
>>> assert d.(2, 3) is True
File "<stdin>", line 1
d.(2, 3)
^
SyntaxError: invalid syntax
>>> getattr(d, (2, 3))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: getattr(): attribute name must be string
>>>
不是。这使您可以访问字典键的所有可打印字符或其他可清除对象,这是访问对象属性时没有的。这使得像缓存对象元类一样神奇,就像Python Cookbook (Ch. 9)中的配方一样。
我在哪里编辑
我更喜欢spam.eggs超过spam['eggs']的美学(我觉得它看起来更干净),当我遇到namedtuple时,我真的开始渴望这个功能了。但是能够做到以下几点的便利性胜过它。
>>> KEYS = 'spam eggs ham'
>>> VALS = [1, 2, 3]
>>> d = {k: v for k, v in zip(KEYS.split(' '), VALS)}
>>> assert d == {'spam': 1, 'eggs': 2, 'ham': 3}
>>>
这是一个简单的例子,但我经常发现自己在不同的情况下使用dicts,而不是使用obj.key表示法(即,当我需要从XML文件中读取prefs时)。在其他情况下,我试图实例化一个动态类并出于美观原因对其进行一些属性,我继续使用dict来保持一致性,以提高可读性。
我确信OP早已解决这个问题令他满意,但如果他仍然想要这个功能,那么我建议他从pypi下载其中一个提供它的软件包:
-
Bunch 是我比较熟悉的人。dict的子类,因此您拥有所有这些功能。 - AttrDict 看起来也很不错,但我并不熟悉它,并且没有透过来源查看我有Bunch。
- 正如Rotareti的评论所述,已经弃用了Bunch,但有一个名为 Munch 的活跃分叉。
然而,为了提高他的代码的可读性,我强烈建议他不混合他的符号样式。如果他更喜欢这种表示法,那么他应该简单地实例化一个动态对象,为其添加所需的属性,并在一天内调用它:
>>> C = type('C', (object,), {})
>>> d = C()
>>> d.spam = 1
>>> d.eggs = 2
>>> d.ham = 3
>>> assert d.__dict__ == {'spam': 1, 'eggs': 2, 'ham': 3}
<小时/>
我在哪里更新,以回答评论中的后续问题
在评论(下方)中, Elmo 会问:
如果你想更深入一下怎么办? (指类型(...))
虽然我从未使用过这个用例(同样,我倾向于使用嵌套的dict,
一致性),以下代码有效:
>>> C = type('C', (object,), {})
>>> d = C()
>>> for x in 'spam eggs ham'.split():
... setattr(d, x, C())
... i = 1
... for y in 'one two three'.split():
... setattr(getattr(d, x), y, i)
... i += 1
...
>>> assert d.spam.__dict__ == {'one': 1, 'two': 2, 'three': 3}
答案 4 :(得分:20)
警告:由于某些原因,这样的类似乎打破了多处理程序包。在找到这个SO之前,我只是在这个bug上挣扎了一段时间: Finding exception in python multiprocessing
答案 5 :(得分:18)
如果您想要一个方法的密钥,例如__eq__或__getattr__,该怎么办?
你将无法拥有一个不以字母开头的条目,因此使用0343853作为关键字已经完成。
如果你不想使用字符串怎么办?
答案 6 :(得分:16)
您可以从标准库中提取一个方便的容器类:
from argparse import Namespace
避免必须复制代码位。没有标准的字典访问,但如果你真的想要它,很容易得到一个。 argparse中的代码很简单,
class Namespace(_AttributeHolder):
"""Simple object for storing attributes.
Implements equality by attribute names and values, and provides a simple
string representation.
"""
def __init__(self, **kwargs):
for name in kwargs:
setattr(self, name, kwargs[name])
__hash__ = None
def __eq__(self, other):
return vars(self) == vars(other)
def __ne__(self, other):
return not (self == other)
def __contains__(self, key):
return key in self.__dict__
答案 7 :(得分:11)
元组可以使用dict键。你将如何访问你的构造中的元组?
此外,namedtuple是一种方便的结构,可以通过属性访问提供值。
答案 8 :(得分:8)
一般情况下不起作用。并非所有有效的dict键都具有可寻址的属性(“键”)。所以,你需要小心。
Python对象基本上都是字典。所以我怀疑有很多表现或其他惩罚。
答案 9 :(得分:4)
这并没有解决原始问题,但对于像我这样的人在寻找提供此功能的lib时最终会对此有用。
上瘾它是一个很好的lib:https://github.com/mewwts/addict它解决了之前答案中提到的许多问题。
来自文档的示例:
body = {
'query': {
'filtered': {
'query': {
'match': {'description': 'addictive'}
},
'filter': {
'term': {'created_by': 'Mats'}
}
}
}
}
使用addict:
from addict import Dict
body = Dict()
body.query.filtered.query.match.description = 'addictive'
body.query.filtered.filter.term.created_by = 'Mats'
答案 10 :(得分:4)
以下是使用内置collections.namedtuple的不可变记录的简短示例:
def record(name, d):
return namedtuple(name, d.keys())(**d)
和一个用法示例:
rec = record('Model', {
'train_op': train_op,
'loss': loss,
})
print rec.loss(..)
答案 11 :(得分:3)
无需自己编写 setattr()和getattr()已经存在。
类对象的优点可能在类定义和继承中发挥作用。
答案 12 :(得分:3)
我是根据这个帖子的输入创建的。我需要使用odict,所以我不得不重写get和set attr。我认为这应该适用于大多数特殊用途。
用法如下:
# Create an ordered dict normally...
>>> od = OrderedAttrDict()
>>> od["a"] = 1
>>> od["b"] = 2
>>> od
OrderedAttrDict([('a', 1), ('b', 2)])
# Get and set data using attribute access...
>>> od.a
1
>>> od.b = 20
>>> od
OrderedAttrDict([('a', 1), ('b', 20)])
# Setting a NEW attribute only creates it on the instance, not the dict...
>>> od.c = 8
>>> od
OrderedAttrDict([('a', 1), ('b', 20)])
>>> od.c
8
班级:
class OrderedAttrDict(odict.OrderedDict):
"""
Constructs an odict.OrderedDict with attribute access to data.
Setting a NEW attribute only creates it on the instance, not the dict.
Setting an attribute that is a key in the data will set the dict data but
will not create a new instance attribute
"""
def __getattr__(self, attr):
"""
Try to get the data. If attr is not a key, fall-back and get the attr
"""
if self.has_key(attr):
return super(OrderedAttrDict, self).__getitem__(attr)
else:
return super(OrderedAttrDict, self).__getattr__(attr)
def __setattr__(self, attr, value):
"""
Try to set the data. If attr is not a key, fall-back and set the attr
"""
if self.has_key(attr):
super(OrderedAttrDict, self).__setitem__(attr, value)
else:
super(OrderedAttrDict, self).__setattr__(attr, value)
这是一个在线程中已经提到的非常酷的模式,但是如果你只是想要一个dict并将它转换为一个在IDE中使用auto-complete的对象,等等:
class ObjectFromDict(object):
def __init__(self, d):
self.__dict__ = d
答案 13 :(得分:3)
显然现在有一个库 - https://pypi.python.org/pypi/attrdict - 它实现了这个确切的功能加上递归合并和json加载。可能值得一看。
答案 14 :(得分:3)
Prodict,I wrote统治它们的小Python类怎么样?)
另外,您可以自动代码完成,递归对象实例化和自动类型转换!
你可以完全按照你的要求行事:
p = Prodict()
p.foo = 1
p.bar = "baz"
示例1:类型提示
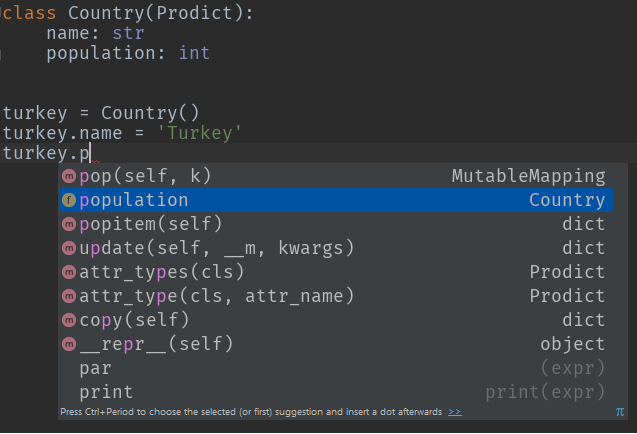
class Country(Prodict):
name: str
population: int
turkey = Country()
turkey.name = 'Turkey'
turkey.population = 79814871
示例2:自动类型转换
germany = Country(name='Germany', population='82175700', flag_colors=['black', 'red', 'yellow'])
print(germany.population) # 82175700
print(type(germany.population)) # <class 'int'>
print(germany.flag_colors) # ['black', 'red', 'yellow']
print(type(germany.flag_colors)) # <class 'list'>
答案 15 :(得分:3)
只是为答案添加了一些内容,sci-kit learn将其实现为Bunch:
class Bunch(dict):
""" Scikit Learn's container object
Dictionary-like object that exposes its keys as attributes.
>>> b = Bunch(a=1, b=2)
>>> b['b']
2
>>> b.b
2
>>> b.c = 6
>>> b['c']
6
"""
def __init__(self, **kwargs):
super(Bunch, self).__init__(kwargs)
def __setattr__(self, key, value):
self[key] = value
def __dir__(self):
return self.keys()
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(key)
def __setstate__(self, state):
pass
您只需要获取setattr和getattr方法 - getattr检查dict键以及检查实际属性。 setstaet是修复/修补&#34; Bunches&#34; - 如果不感兴趣,请检查https://github.com/scikit-learn/scikit-learn/issues/6196
答案 16 :(得分:2)
让我发布另一个实现,它建立在Kinvais的答案之上,但是整合了http://databio.org/posts/python_AttributeDict.html中提出的AttributeDict的想法。
此版本的优点是它也适用于嵌套字典:
class AttrDict(dict):
"""
A class to convert a nested Dictionary into an object with key-values
that are accessible using attribute notation (AttrDict.attribute) instead of
key notation (Dict["key"]). This class recursively sets Dicts to objects,
allowing you to recurse down nested dicts (like: AttrDict.attr.attr)
"""
# Inspired by:
# http://stackoverflow.com/a/14620633/1551810
# http://databio.org/posts/python_AttributeDict.html
def __init__(self, iterable, **kwargs):
super(AttrDict, self).__init__(iterable, **kwargs)
for key, value in iterable.items():
if isinstance(value, dict):
self.__dict__[key] = AttrDict(value)
else:
self.__dict__[key] = value
答案 17 :(得分:1)
class AttrDict(dict):
def __init__(self):
self.__dict__ = self
if __name__ == '____main__':
d = AttrDict()
d['ray'] = 'hope'
d.sun = 'shine' >>> Now we can use this . notation
print d['ray']
print d.sun
答案 18 :(得分:1)
我发现自己想知道python生态系统中“ dict keys as attr”的当前状态是什么。正如一些评论者指出的那样,这可能不是您不想从头开始的东西,因为存在一些陷阱和脚枪,其中一些非常隐蔽。另外,我不建议将Namespace用作基类,因为我一直走这条路,这并不漂亮。
幸运的是,有几个提供此功能的开源软件包已准备好进行pip安装!不幸的是,有几个软件包。概要,截至2019年12月。
竞争者(最近提交给master |#commits ## contribs | coverage%):
- addict(2019-04-28 | 217 | 22 | 100%)
- munch(2019-12-16 | 160 | 17 |?%)
- easydict(2018-10-18 | 51 | 6 |?%)
- attrdict(2019-02-01 | 108 | 5 | 100%)
- prodict(2019-10-01 | 65 | 1 |?%)
不再维护或维护不足:
我目前推荐猛击或上瘾者。他们拥有最多的提交,贡献者和发布,建议为每个构建一个健康的开源代码库。它们具有最干净的readme.md,100%的覆盖率和良好的测试集。
在这场比赛中,我没有狗,除了滚动了自己的dict / attr代码并浪费了很多时间,因为我不知道所有这些选择:)。将来我可能会为瘾君子/饥饿做贡献,因为我宁愿看到一个坚固的包装,也不愿看到一堆零散的包装。如果您喜欢它们,请贡献力量!特别是,看起来像munch可以使用codecov徽章,而上瘾者可以使用python版本的徽章。
瘾君子:
- 递归初始化(foo.a.b.c ='bar'),类似dict的参数会上瘾。Dict
瘾君子:
-
如果您
- 阴影
from addict import Dict
typing.Dict,专家:
- 唯一命名
- 用于JSON和YAML的内置ser / de函数
munch缺点:
- 没有递归初始化/一次只能初始化一个attr
随时编辑/更新此帖子以保持最新!
答案 19 :(得分:1)
这就是我用的
args = {
'batch_size': 32,
'workers': 4,
'train_dir': 'train',
'val_dir': 'val',
'lr': 1e-3,
'momentum': 0.9,
'weight_decay': 1e-4
}
args = namedtuple('Args', ' '.join(list(args.keys())))(**args)
print (args.lr)
答案 20 :(得分:1)
如Doug所述,你可以使用Bunch包来实现obj.key功能。实际上有一个叫做
<强> NeoBunch
它有一个很棒的功能,它通过 neobunchify 功能将你的dict转换为NeoBunch对象。我经常使用Mako模板并传递数据作为NeoBunch对象使它们更具可读性,所以如果你最终在Python程序中使用普通的dict但是想要在Mako模板中使用点符号,你可以这样使用它: / p>
from mako.template import Template
from neobunch import neobunchify
mako_template = Template(filename='mako.tmpl', strict_undefined=True)
data = {'tmpl_data': [{'key1': 'value1', 'key2': 'value2'}]}
with open('out.txt', 'w') as out_file:
out_file.write(mako_template.render(**neobunchify(data)))
Mako模板看起来像:
% for d in tmpl_data:
Column1 Column2
${d.key1} ${d.key2}
% endfor
答案 21 :(得分:1)
解决方案是:
DICT_RESERVED_KEYS = vars(dict).keys()
class SmartDict(dict):
"""
A Dict which is accessible via attribute dot notation
"""
def __init__(self, *args, **kwargs):
"""
:param args: multiple dicts ({}, {}, ..)
:param kwargs: arbitrary keys='value'
If ``keyerror=False`` is passed then not found attributes will
always return None.
"""
super(SmartDict, self).__init__()
self['__keyerror'] = kwargs.pop('keyerror', True)
[self.update(arg) for arg in args if isinstance(arg, dict)]
self.update(kwargs)
def __getattr__(self, attr):
if attr not in DICT_RESERVED_KEYS:
if self['__keyerror']:
return self[attr]
else:
return self.get(attr)
return getattr(self, attr)
def __setattr__(self, key, value):
if key in DICT_RESERVED_KEYS:
raise AttributeError("You cannot set a reserved name as attribute")
self.__setitem__(key, value)
def __copy__(self):
return self.__class__(self)
def copy(self):
return self.__copy__()
答案 22 :(得分:1)
你可以使用我刚刚制作的这个课程。使用此类,您可以使用Map对象,如另一个字典(包括json序列化)或点符号。我希望能帮到你:
class Map(dict):
"""
Example:
m = Map({'first_name': 'Eduardo'}, last_name='Pool', age=24, sports=['Soccer'])
"""
def __init__(self, *args, **kwargs):
super(Map, self).__init__(*args, **kwargs)
for arg in args:
if isinstance(arg, dict):
for k, v in arg.iteritems():
self[k] = v
if kwargs:
for k, v in kwargs.iteritems():
self[k] = v
def __getattr__(self, attr):
return self.get(attr)
def __setattr__(self, key, value):
self.__setitem__(key, value)
def __setitem__(self, key, value):
super(Map, self).__setitem__(key, value)
self.__dict__.update({key: value})
def __delattr__(self, item):
self.__delitem__(item)
def __delitem__(self, key):
super(Map, self).__delitem__(key)
del self.__dict__[key]
用法示例:
m = Map({'first_name': 'Eduardo'}, last_name='Pool', age=24, sports=['Soccer'])
# Add new key
m.new_key = 'Hello world!'
print m.new_key
print m['new_key']
# Update values
m.new_key = 'Yay!'
# Or
m['new_key'] = 'Yay!'
# Delete key
del m.new_key
# Or
del m['new_key']
答案 23 :(得分:0)
以这种方式访问字典键会带来哪些警告和陷阱?
正如@Henry所建议的那样,在字典中可能不使用点分访问的一个原因是它将字典键名限制为python有效变量,从而限制了所有可能的名称。
以下是一些示例,说明了在给出d的情况下,点访问通常不会有帮助的情况:
有效期
以下属性在Python中无效:
d.1_foo # enumerated names
d./bar # path names
d.21.7, d.12:30 # decimals, time
d."" # empty strings
d.john doe, d.denny's # spaces, misc punctuation
d.3 * x # expressions
样式
PEP8约定会对属性命名施加软约束:
A。保留的keyword(或内置函数)名称:
d.in
d.False, d.True
d.max, d.min
d.sum
d.id
如果函数参数的名称与保留关键字冲突,通常最好在其后附加一个下划线...
B。 methods和variable names的大小写规则:
变量名称与函数名称遵循相同的约定。
d.Firstname
d.Country
使用函数命名规则:小写字母,必要时用下划线分隔单词,以提高可读性。
有时,这些问题在libraries like pandas中引起了注意,它允许按名称对DataFrame列进行点访问。解决命名限制的默认机制也是数组符号-括号中的字符串。
如果这些约束不适用于您的用例,则dotted-access data structures上有多个选项。
答案 24 :(得分:0)
您可以使用dict_to_obj https://pypi.org/project/dict-to-obj/ 它完全符合您的要求
From dict_to_obj import DictToObj
a = {
'foo': True
}
b = DictToObj(a)
b.foo
True
答案 25 :(得分:0)
这不是一个“好”的答案,但我认为这很漂亮(它不处理当前形式的嵌套dicts)。只需将dict包装在一个函数中:
def make_funcdict(d={}, **kwargs)
def funcdict(d={}, **kwargs):
funcdict.__dict__.update(d)
funcdict.__dict__.update(kwargs)
return funcdict.__dict__
funcdict(d, **kwargs)
return funcdict
现在你的语法略有不同。要将dict项作为属性访问f.key。要以通常的方式访问dict项(和其他dict方法),请f()['key']我们可以通过使用关键字参数和/或字典调用f来方便地更新dict
实施例
d = {'name':'Henry', 'age':31}
d = make_funcdict(d)
>>> for key in d():
... print key
...
age
name
>>> print d.name
... Henry
>>> print d.age
... 31
>>> d({'Height':'5-11'}, Job='Carpenter')
... {'age': 31, 'name': 'Henry', 'Job': 'Carpenter', 'Height': '5-11'}
就是这样。如果有人提出这种方法的好处和缺点,我会很高兴。
答案 26 :(得分:0)
最简单的方法是定义一个类,我们将其称为命名空间。在字典上使用对象 dict .update()。然后,该字典将被视为对象。
class Namespace(object):
'''
helps referencing object in a dictionary as dict.key instead of dict['key']
'''
def __init__(self, adict):
self.__dict__.update(adict)
Person = Namespace({'name': 'ahmed',
'age': 30}) #--> added for edge_cls
print(Person.name)
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?