我的问题有点复杂。很难用文字来解释,所以我在每一步都把它分解为图片。
答案 0 :(得分:1)
需要知道您正在查看/查看网页来源的网址。如果日期作为请求的任何部分提供,并且响应中包含您要查找的数据,那么从python脚本中存储和分析该数据应该很简单。
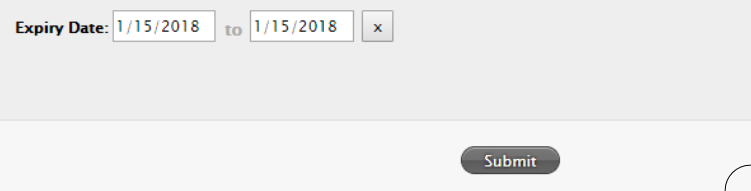
使用浏览器的开发者工具的网络标签浏览您的点击次数,当您点击提交时,您会看到请求消失。 Expedia只使用查询参数,因此在点击提交后,您需要在浏览器的网址栏中弹出整个网址...
工具:
如果基于请求: 蟒蛇 请求模块
如果某些内容缓存/更复杂,有一些工具可以自动执行点击并保存结果......我猜想这不会是必要的......
更新
AJAX调用是HTTP请求和响应,因此您应该能够在我们的Web浏览器开发人员工具的网络选项卡中观察它们,然后从脚本而不是从您的浏览器模仿该请求。
请求/响应的可读性和/或组织为使浏览器无法获得相同响应之外的任何应用而实施的任何措施都是潜在的障碍,但即使这些也应该是可模仿的。如果您的浏览器正在发出请求,那么您的python脚本就没有理由不能这样做。
你似乎感兴趣的方法虽然对我来说听起来更复杂,但可以使用像Selenium这样的自动化工具,正如另一张海报回答的那样。祝你好运。
答案 1 :(得分:0)
有可能:
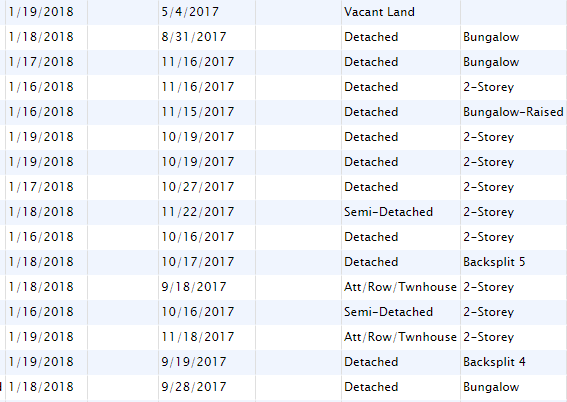
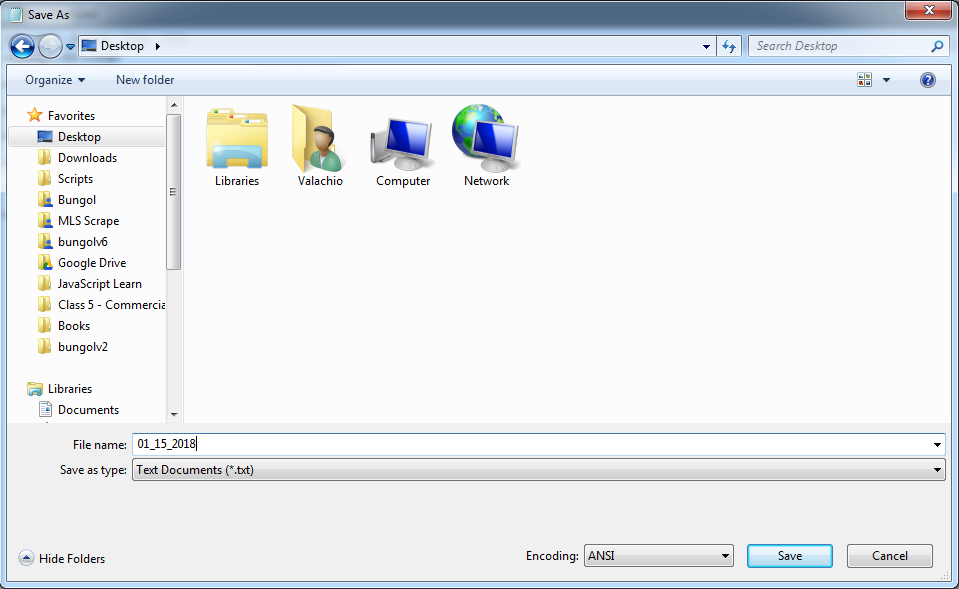
查看python的selenium库(它常用于自动化测试)。它应该能够选择单个日期,点击提交按钮,然后浏览HTML代码并获取标签中的数据。之后,您可以单独使用python将此数据存储在一个文本文件中,该文件文件的名称可以选择在您选择的位置。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}