1)我有 5节点集群(172.30.56.60,172.30.56.61,172.30.56.62,172.30.56.63,172.30.56.129)
2)我创建了一个复制因子为3 的密钥空间 写一致性为3 ,我在一个表中插入了一行,其中分区为' 1'如下,
INSERT INTO user(user_id,user_name,user_phone)VALUES(1,' ram',9003934069);
3)我使用nodetool getendpoints实用程序验证了数据的位置,并观察到数据被复制到三个节点60,129和62中。
./nodetool getendpoints keyspacetest user 1
172.30.56.60
172.30.36.129
172.30.56.62
4)现在如果我关闭节点60,Cassandra需要将现有数据传输到'1,'ram', 9003934069'到剩余节点(到61或63)以将RF保持为' 3&#39 ;
但是Cassandra没有这样做,所以这意味着如果节点60,129和62关闭,我将无法在分区' 1'下读取/写入任何数据。在表格'用户' ?
问题1:所以即使我有5个节点集群,如果它所在的数据/分区发生故障,集群也没用?
问题2:如果两个节点关闭(例如:60和129关闭)仍然61,62和63启动并运行,但我无法在分区中写入任何数据' 1&#39 ;写一致性= 3,为什么会这样?在哪里,我能够写入写一致性= 1的数据,所以这再次表明分区的数据只能在集群中的预定义节点中使用,不可能重新分区?
如果我的问题的任何部分不清楚,请告诉我,我想澄清一下。
答案 0 :(得分:4)
4)现在如果我关闭节点60,Cassandra需要转移 现有数据到' 1,' ram',9003934069'到剩下的节点(到 61或63)将RF保持为' 3'?
这不是Cassandra的工作方式 - 复制因素只有'声明在不同节点上将Cassandra存储在磁盘上的数据副本数量。 Cassandra在数学上形成了一个环节点。每个节点负责一系列所谓的令牌(基本上是分区键组件的哈希)。您的复制因子为3表示数据将存储在节点上,负责处理数据令牌和环中的下两个节点。
更改环形拓扑非常复杂,根本不会自动完成。
1)我有5个节点集群(172.30.56.60,172.30.56.61,172.30.56.62,172.30.56.63,172.30.56.129)
2)我创建了一个复制因子为3的密钥空间 写一致性为3,我在一个表中插入一行,分区为' 1'如下,
INSERT INTO user(user_id,user_name,user_phone)VALUES(1,' ram',9003934069);
3)我使用nodetool getendpoints实用程序验证了数据的位置,并观察到数据被复制到三个节点60,129和62中。
./ nodetool getendpoints keyspacetest用户1 172.30.56.60 172.30.36.129 172.30.56.62 4)现在如果我关闭节点60,Cassandra需要将现有数据传输到' 1,' ram" 9003934069'到剩余的节点(到61或63)以保持RF为' 3'?
但是Cassandra没有这样做,所以这意味着如果节点60,129和62关闭,我将无法在分区' 1'下读取/写入任何数据。在表格'用户' ?
问题1:所以即使我有5个节点集群,如果是数据/分区 它所在的位置下降,群集是无用的?
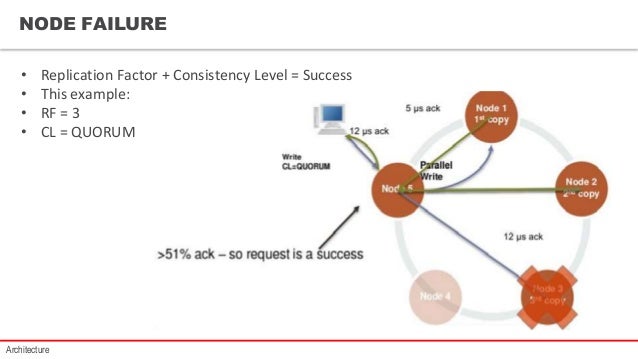
没有。另一方面,存在一致性级别 - 您可以在其中定义在认为成功之前必须确认您的写入和读取请求的节点数。上面你还拿了CL = 3和RF = 3 - 这意味着所有持有副本的节点必须响应并且需要在线。如果一个人关闭,你的请求将一直失败(如果你的群集更大,比如6个节点,那么在线的三个可能是某些写入的“正确”)。
但Cassandra具有可调整的一致性(请参阅http://docs.datastax.com/en/archived/cassandra/2.0/cassandra/dml/dml_config_consistency_c.html处的文档)。
例如,您可以选择QUORUM。然后(复制因子/ 2)+1节点需要查询。在你的情况下(3/2)+ 1 = 1 + 1 = 2个节点。如果您真的需要一致的数据,QUORUM是完美的,因为在任何情况下,参与您的请求的至少一个节点将在写入和读取之间重叠并具有最新数据。现在一个节点可以关闭,每个东西都可以工作。
但是:
问题2:如果两个节点关闭(示例:60和129已关闭)仍然存在 61,62和63已启动并运行,但我无法写入任何数据 在分区' 1'写一致性= 3,为什么会这样? 在哪里,我能够写入具有写一致性= 1的数据 这再次说明分区的数据只能在 集群中的预定义节点,没有重新分区的可能性?
请看上面 - 这是解释。写入一致性的CL = 1将成功,因为一个节点仍处于联机状态,并且您只请求一个节点确认您的写入。
当然复制因素根本没用。即使选择了较低的一致性级别,写入也将复制到所有可用节点,但您不必在客户端等待它。如果节点在短时间内(默认为3小时)停机,协调器将存储错过的写入并在节点再次出现并且您的数据再次完全复制时重播它们。
如果某个节点长时间处于关闭状态,则必须运行nodetool repair并让群集重建一致状态。这应该定期进行,作为维护任务,以保持您的集群健康 - 由于网络/负载问题可能会错过写入,并且有删除的墓碑可能会很痛苦。
您可以删除或添加节点到您的群集(如果这样做,一次只添加一个),Cassandra将为您重新分配您的戒指。
如果删除在线节点可以将其上的数据流式传输给其他节点,则可以删除脱机节点,但其上的数据将没有足够的副本,因此必须运行nodetool repair。
添加节点会将新令牌范围分配给新节点,并自动将数据流式传输到新节点。但是不会为您的源节点删除现有数据(保证您的安全),因此添加节点nodetool cleanup之后是您的朋友。
Cassandra从CAP定理中选择A(可用)和P(artition tolerant)。 (见https://en.wikipedia.org/wiki/CAP_theorem)。因此,您无法随时保持一致性 - 但QUORUM通常会绰绰有余。
保持对节点的监控并且不要太害怕节点故障 - 它只是在磁盘丢失或网络丢失的情况下发生,而是设计应用程序。
更新:在您丢失数据或查询之前,用户可以选择群集可能发生的情况。如果需要,你可以使用更高的复制因子(RF = 7和CL.QUROUM容忍丢失3)和/或甚至在不同位置使用多个数据中心,以防一个人丢失整个数据中心(这在现实生活中发生,想到网络丢失) )。
以下关于https://www.ecyrd.com/cassandracalculator/的评论:
群集大小3
复制因子2
写等级2
阅读1级
您的阅读是一致的:当然,您要求所有副本都需要写入。
您可以在不影响应用程序的情况下幸免于没有节点:参见上文,RF = 2和WC = 2请求在任何时候所有节点都需要响应写入。因此,对于写入,您的应用程序将受到影响,因为读取一个节点可能会关闭。
您可以在没有数据丢失的情况下丢失1个节点:因为数据被写入2个副本,而您只能从一个节点读取,如果一个节点关闭,您仍然可以从另一个节点读取数据。
你每次都是从1个节点读取:RC = 1请求你的阅读服务由一个副本服务 - 所以第一个读取的第一个节点会做,如果有的话节点已关闭,因为另一个节点可以解读您的节目。
您每次都在写入2个节点:WC = 2请求每次写入将由两个副本确认 - 这也是示例中的副本数量。因此,在写入数据时,所有节点都需要联机。
每个节点拥有67%的数据:只是一些数学;)
使用这些设置,您可以在写入群集时不受影响地在节点丢失中幸存。但是您的数据会在两个副本上写入磁盘 - 因此,如果您丢失了一个副本,您仍然可以将数据保存在另一个副本上并从死节点恢复。
{kind=link}