我试图用一个显示带有频率的单词的段落来制作一个对象。
var pattern = /\w+/g,
//the farsi paragraph
string = "من امروز در مورد مهر خروج مشمولین اطلاعات جدیدی از سفارت ایران در مالزی گرفتم",
matchedWords = string.match( pattern );
/* The Array.prototype.reduce method assists us in producing a single value from an
array. In this case, we're going to use it to output an object with results. */
var counts = matchedWords.reduce(function ( stats, word ) {
/* `stats` is the object that we'll be building up over time.
`word` is each individual entry in the `matchedWords` array */
if ( stats.hasOwnProperty( word ) ) {
/* `stats` already has an entry for the current `word`.
As a result, let's increment the count for that `word`. */
stats[ word ] = stats[ word ] + 1;
} else {
/* `stats` does not yet have an entry for the current `word`.
As a result, let's add a new entry, and set count to 1. */
stats[ word ] = 1;
}
/* Because we are building up `stats` over numerous iterations,
we need to return it for the next pass to modify it. */
return stats;
}, {})
var dict = []; // create an empty array
// this for loop makes a dictionary for you
for (i in counts){
dict.push({'text':i, "size": counts[i]});
};
/* lets print and see if you can solve your problem */
console.log( dict);
最初为英文段落编写的代码。但是我需要将它用于波斯语。 我知道它应该是别的而不是" / \ w + / g"在:
var pattern = /\w+/g,
但我不知道是什么。
答案 0 :(得分:1)
在你的正则表达式中使用变量为\S的“任何字符但空白”。
编辑:空格被视为换行符,选项卡和空格)
var pattern = /\S+/g,
//the farsi paragraph
string = "من امروز در مورد مهر خروج مشمولین اطلاعات جدیدی از سفارت ایران در مالزی گرفتم",
matchedWords = string.match( pattern );
/* The Array.prototype.reduce method assists us in producing a single value from an
array. In this case, we're going to use it to output an object with results. */
var counts = matchedWords.reduce(function ( stats, word ) {
/* `stats` is the object that we'll be building up over time.
`word` is each individual entry in the `matchedWords` array */
if ( stats.hasOwnProperty( word ) ) {
/* `stats` already has an entry for the current `word`.
As a result, let's increment the count for that `word`. */
stats[ word ] = stats[ word ] + 1;
} else {
/* `stats` does not yet have an entry for the current `word`.
As a result, let's add a new entry, and set count to 1. */
stats[ word ] = 1;
}
/* Because we are building up `stats` over numerous iterations,
we need to return it for the next pass to modify it. */
return stats;
}, {})
var dict = []; // create an empty array
// this for loop makes a dictionary for you
for (i in counts){
dict.push({'text':i, "size": counts[i]});
};
/* lets print and see if you can solve your problem */
console.log( dict);
答案 1 :(得分:1)
要匹配任何字母,您需要使用XRegExp包和\pL Unicode属性类:
var pattern = new XRegExp("[_\\pL\\pN]+", "g");
var s = "من امروز در مورد مهر خروج مشمولین اطلاعات جدیدی از سفارت ایران در مالزی گرفتم";
var matchedWords = s.match( pattern );
var counts = matchedWords.reduce(function ( stats, word ) {
if ( stats.hasOwnProperty( word ) ) {
stats[ word ] = stats[ word ] + 1;
} else {
stats[ word ] = 1;
}
return stats;
}, {})
var dict = [];
for (i in counts){
dict.push({'text':i, "size": counts[i]});
}
console.log(dict);<script src="https://cdnjs.cloudflare.com/ajax/libs/xregexp/3.2.0/xregexp-all.min.js"></script>
[_\\pL\\pN]+模式匹配一个或多个下划线(_,我将其包括在内,因为原始正则表达式中的\w也匹配_),Unicode字母({{1} }}和数字(\pL)。
要仅计算由字母组成的单词,请使用
\pN答案 2 :(得分:1)
为什么不在你的情况下使用split与reduce结合使用?例如:
const p = 'من امروز در مورد مهر خروج مشمولین اطلاعات جدیدی از سفارت ایران در مالزی گرفتم';
const counted = p.split( ' ' ).reduce( ( collected, item ) => {
collected[ item ] = ( collected[ item ] || 0 ) + 1;
return collected;
}, { /* initial empty object */ } );
const dict = Object.keys( counted ).map( key => {
return {
text: key,
size: counted[ key ],
};
} );
console.log( 'در:', counted[ 'در' ] );
console.log( dict );
它更简单,表现更好。你甚至可以省略const dict...部分。
答案 3 :(得分:0)
您可以使用JS等效词和量词"This is articles ViewModel:
public ArticlesViewModel()
{
public string ArticleName { get; set; }
}"
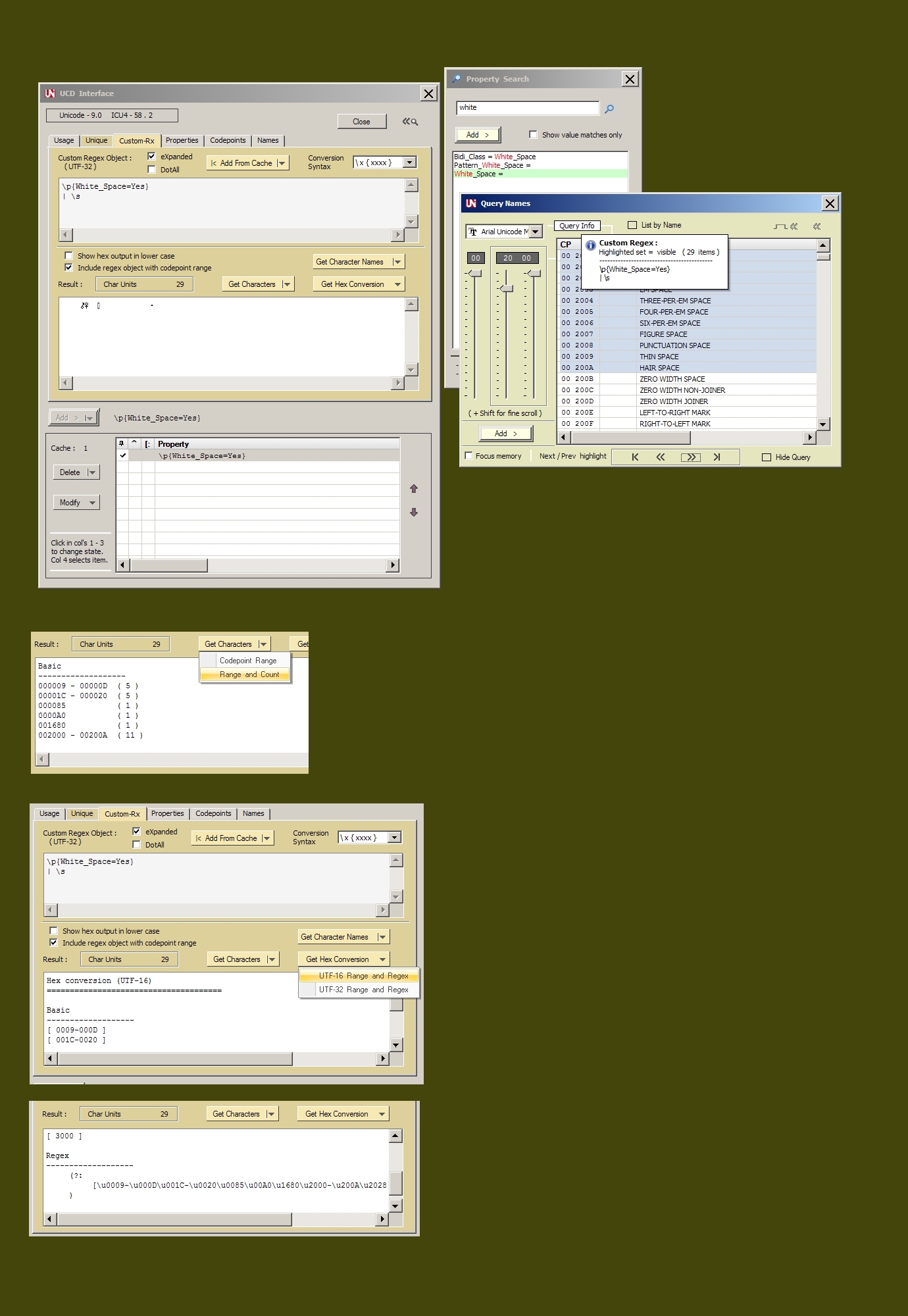
这将匹配大约119,000 Unicode 9 字符
这包括所有非字母,非数字,其他字符
像下划线一样,其中大约有1,100个。
注意 - 它运行得非常快,但我会使这个正则表达式全局和
编译一次以供以后使用。
此外,这是从ICU数据库生成的,它提供了完整的数据
在U + 000000到U + 10FFFF之间的单词\w+的样本,从这个正则表达式中
是使用UCD Interface应用中的RegexFormat生成的。
这是 XRegExp 无法做到的事情。
演示:
https://regex101.com/r/sjLmMC/1
\w
{kind=link}