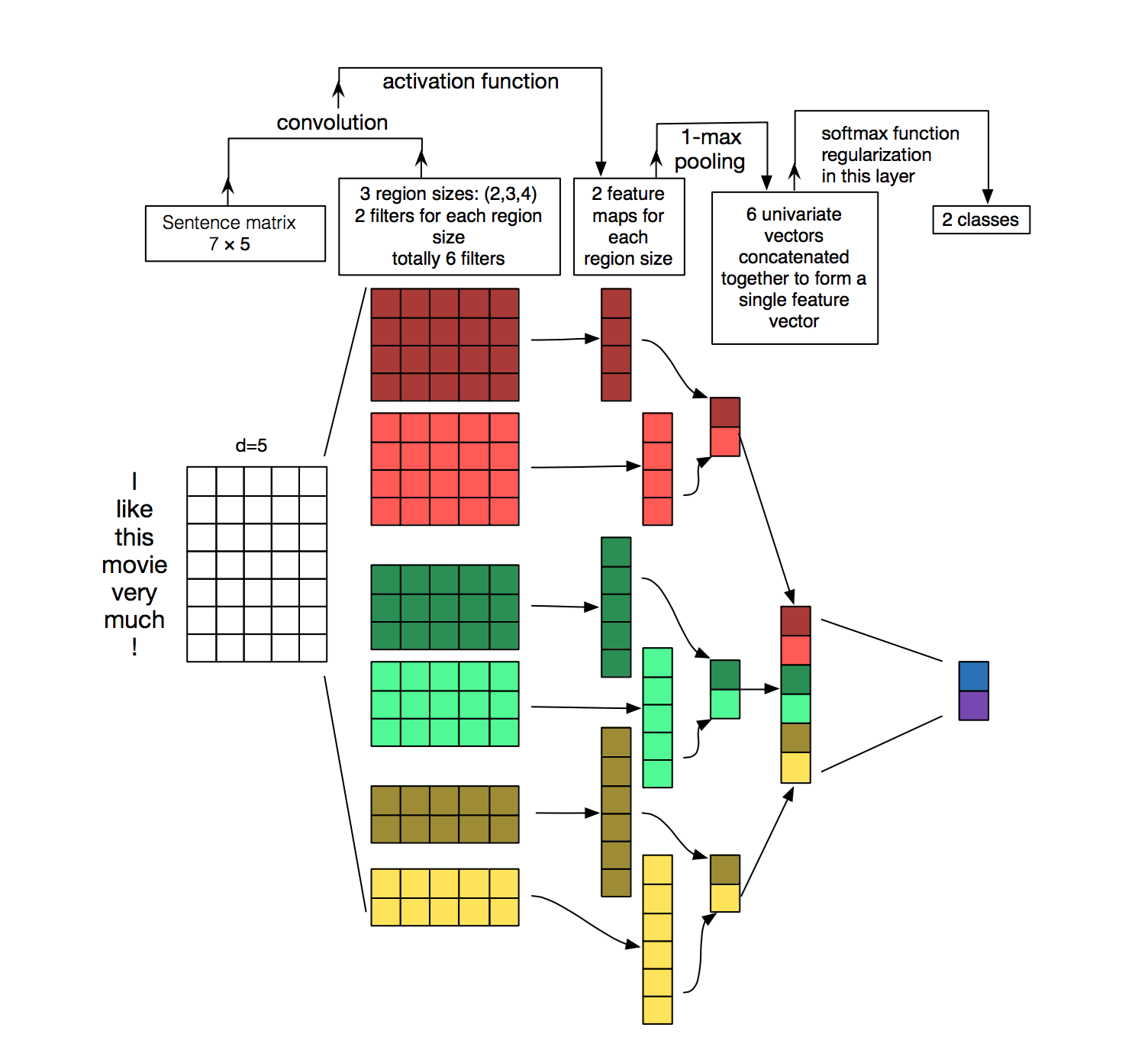
我正在尝试使用CNN实现text classification model。据我所知,对于文本数据,我们应该使用1d卷积。我在使用Conv2d的pytorch中看到了一个例子,但我想知道如何将Conv1d应用于文本?或者,它实际上是不可能的?
以下是我的模型场景:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\libnvvp
因此,我将提供形状的张量,< 16,1,28,300>其中28是句子的长度。我想使用Conv1d,它会给我128张长度为26的特征图(因为我正在考虑三卦)。
我不确定,如何为此设置定义nn.Conv1d()。我可以使用Conv2d,但想知道是否可以使用Conv1d实现相同的目标?
答案 0 :(得分:11)
此example个Conv1d和Pool1d图层已经解决了我的问题。
因此,我需要将嵌入维度视为使用nn.Conv1d时的通道内数量,如下所示。
m = nn.Conv1d(200, 10, 2) # in-channels = 200, out-channels = 10
input = Variable(torch.randn(10, 200, 5)) # 200 = embedding dim, 5 = seq length
feature_maps = m(input)
print(feature_maps.size()) # feature_maps size = 10,10,4
答案 1 :(得分:2)
虽然我不使用文本数据,但是当前形式的输入张量只能使用conv2d。使用conv1d的一种可能方式是将嵌入连接成一个形状的张量,例如: < 16,1,28 * 300取代。您可以使用view在pytorch中重新整形输入。
{kind=link}