我假设在基于列的数据库中,每列都存储为单个文件,或者连续存储在文件中。如果输入数据仍然是传统的基于行的数据库之类的一行数据,那么我们如何才能有效地创建基于列的数据库呢?
将每个列存储在一个文件中可能只是“问题”...... 如果有N列,则有N个文件。当新的数据行到达时,数据库需要将新数据附加到每个文件中。但是,由于在不同文件之间切换,将数据写入不同的文件会有开销吗?也许最后一次写入附近的块仍然在缓存中。但是如果有很多列(> 1M),我不确定缓存是否可以容纳所有这些列。另外我猜磁盘头也需要在不同的文件中寻找......
如果我们在同一个文件中保存多个列,我们可以减少文件句柄的数量,但在文件中插入新的列数据是很昂贵的。也许可以为文件中的每一列保留一个保留空间。但最终这个空间都被使用了。那时,我们是否要创建一个具有更大保留空间的新文件,将数据复制到其中,......?
是否有任何文件或项目可以解释如何有效地从数据行创建基于列的数据库。
答案 0 :(得分:1)
这是每个人都面临的情况。
您在某些领域深入挖掘并了解您想要解决的一些问题。即使您对每个问题都有直观的解决方案,也无法解决所有这些问题。没有银弹,而且一如既往,你在某些领域取胜而在其他领域失败。
您已经提到了数据库创建方面。但是没有数据提取,这是没有价值的。例如,您可以创建高效且快速的数据库创建方法,但是如果数据选择非常慢则无关紧要。或者......不是,如果你最常见的情况是写数据。
还有更多的注意事项,如事务,查询等。所有这些都需要在数据库架构阶段加以考虑。
总而言之,总会有一些权衡,你作为架构师应该定义所需功能的目标和指标来选择实现。
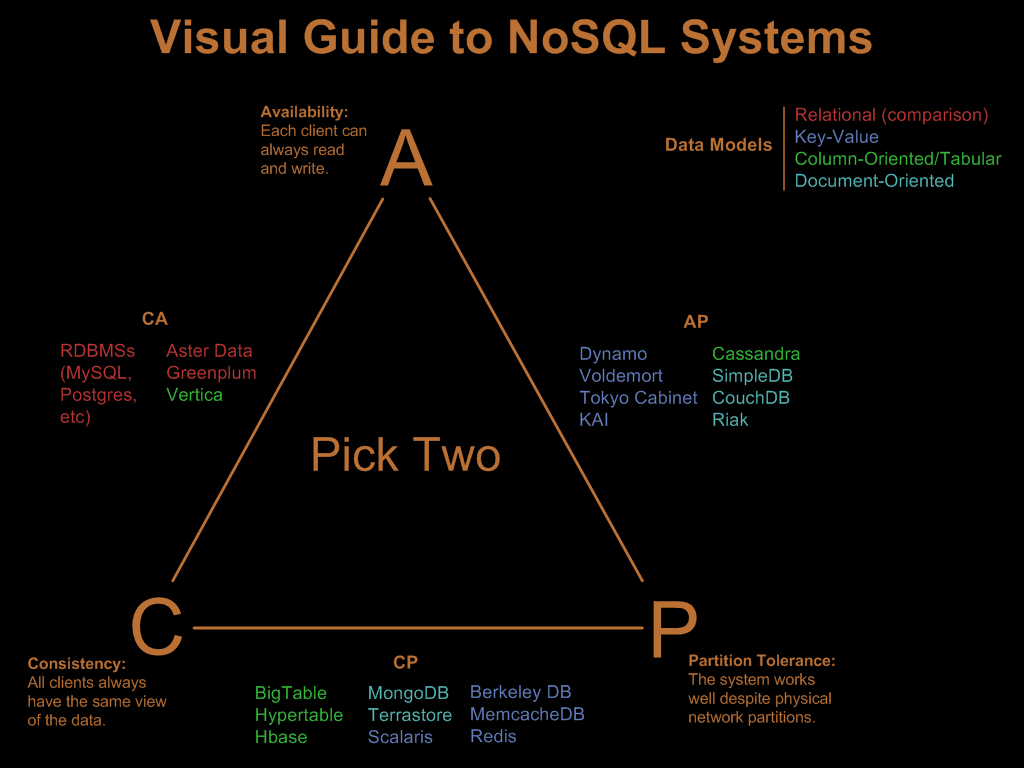
您可以在分布式系统领域找到类似的技巧。例如,CAP theorem表示您不能拥有具有所有三种保证的系统(一致性,可用性,分区容差)。所以有些人说:“我们想要C和A,而不关心P”。其他状态:“哦,我们肯定需要C和P,并且不要太在意A”。所以有database systems meeting different kinds of wants。
您可以找到一些关于面向列的数据库的论文,例如this one,this和this presentation。
{kind=link}