更新多个数据的更好方法
我有这个MySQL表,其中 contact_id 行对每个 user_id 都是唯一的。
history:
- hist_id: int(11) auto_increment primary key
- user_id: int(11)
- contact_id: int(11)
- name: varchar(50)
- phone: varchar(30)
服务器有时会收到特定user_id的新联系人列表,需要更新此表,插入,删除或更新与以前信息不同的数据。
例如,当前数据是:

因此,服务器会收到以下数据:

新数据是:

如您所见,第一行(John)已更新,第二行(Mary)已删除,另一行(Jeniffer)已包含在内。
今天我正在做的是删除具有特定user_id的所有行,并插入新数据。但是自动增量字段(hist_id)越来越大......
Obs:Table有大约8万条记录,此更新将每天发生30次或更多次。
我有一些(相关的)问题:
1。在这种情况下,您认为从特定user_id删除所有记录并插入更新数据是一种好方法吗?
2. 。删除自动增量字段怎么样?我不需要它,但我认为拥有没有主键的表不是一个好主意。
3。或者更好的方法是循环新数据,选择每个user_id / contact_id来比较要更新的值?
PS。为了更好的方法,我的意思是最有效的方法
非常感谢您的帮助!
1 个答案:
答案 0 :(得分:1)
- 在这种情况下,您认为从特定user_id删除所有记录并插入更新数据是一种好方法吗?
简答 不。您应该利用' upsert '这是“插入重复密钥更新”的缩写。这意味着如果它们的密钥对已经存在,则使用指定的数据更新指定的列。然后缩短逻辑并减少增量。这是一个例子,使用应该起作用的表结构。这也假设您已将user_id和contact_id字段设置为唯一。
INSERT INTO history (user_id, contact_id, name, phone)
VALUES
(1, 23, 'James Jr.', '(619)-543-6222')
ON DUPLICATE KEY UPDATE
name=VALUES(name),
phone=VALUES(phone);
此查询应保留contact_id,但会使用新数据覆盖现有数据。
- 如何移除自动增量区域?我不需要它,但我认为拥有没有主键的表不是一个好主意。
主键不表示自动递增的值。我可以将varchar字段作为包含水果和蔬菜名称的主键。这是针对性能优化的吗?可能不是。有许多情况可能需要自动增量,并且有明确的理由可以避免它。这一切都取决于您希望如何访问数据以及这将如何影响未来的扩展。在您的情况下,我将重新开始表结构并重新考虑您希望如何存储和访问数据。您是否想要编写更多逻辑来控制数据 OR 您希望数据自然流动吗?你已经制作了一张历史表,乍一看它的功能更像是混合型的多对一人行横道。如果不看剩余的表结构,我不一定会突然说这不是一个好主意。我可以说的是,我会这样做有点不同。我将在下一个问题中更具体地回答这个问题。
- 或许更好的方法是循环新数据,选择每个user_id / contact_id来比较要更新的值?
我会避免循环数据以更新它。这是SQL的一项工作,它可以很好地完成这项工作。有时,我们可能会发现自己必须这样做,要么以特定格式提取数据,要么以某种方式修复数据,但要避免这样做以插入或更新数据。它会对性能产生负面影响,你可能会把自己描绘成一个角落。
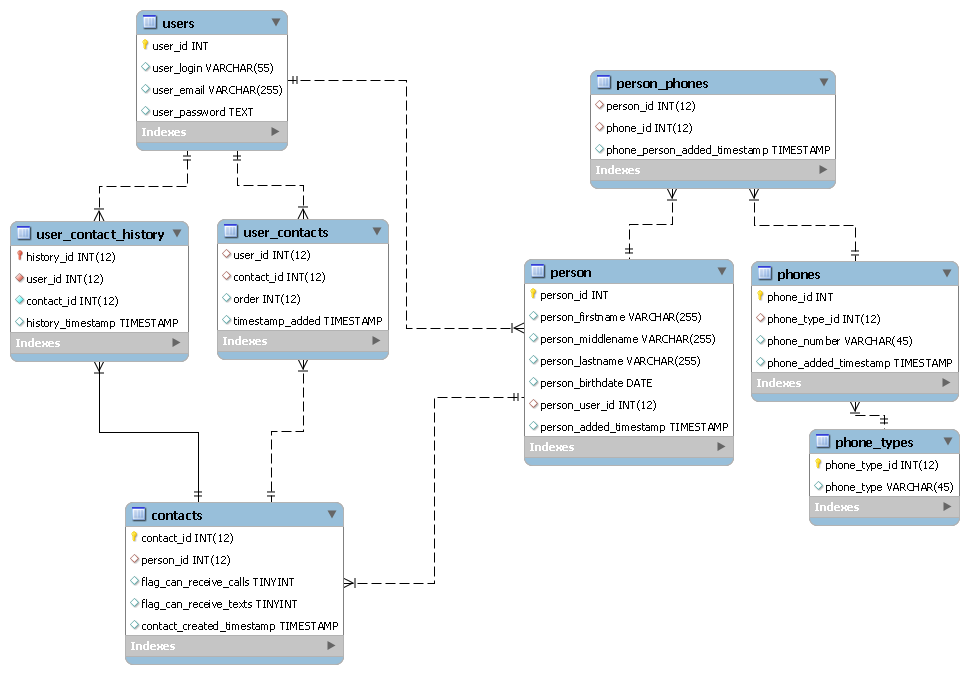
回到我在第二个问题的结尾处所说的内容,这将有助于您了解我在说什么。我将假设 user_id 是在用户表中自动递增的主键。我将在此处进行一些 guestimation ,并向您展示如何重新设计用户,联系人和电话号码结构。以下是我汇总的快速模型,显示了表之间的外键关系。
注意:列名和整体数据安排可以不同方式完成,但我很快就这样做了,为您提供了一个标准化数据库结构的体面示例。所有外键都具有结构布局,可以将数据分开,使您能够在进入和离开系统时控制数据流。这是我使用MySQL Workbench汇总的数据库模型的屏幕截图。
Normalized Contact History Database Example http://xonos.net/user_contact_history_diagram.png Here's the SQL以便您可以更仔细地查看它。
{kind=link}
您会注意到“person”表是从用户中提取的,但与联系人共享数据。这使您可以将所有“人”存储在一个地方,将所有“用户”存储在另一个地方,将所有“联系人”存储在另一个地方。现在,我们为什么要这样做?第一个原因可以在两种情况下解释。
1。)说我们有人,在这个例子中我称他为“Jim Bean”。 “Jim Bean”适用于公司,因此他是该系统的用户。但是,“Jim Bean”恰好拥有一家副业,同时也为公司联系工作。因此,他既是系统的联系人,也是系统的用户。在更“扁平的表”环境中,我们将有两条Jim Bean记录包含相同的数据,这些数据可能会很快过时或不正确。
2。)让我们说Jim做了一些不好的事情,公司不再想和他做任何关系了。他们不想要任何关于他的记录 - 好像他从未存在过。我们所要做的就是从Person表中删除Jim Bean。而已。由于外来关系在更新/删除时具有“CASCADE” - 这会自动传播并清除与他相关的其他表。
我强烈建议您对规范化数据结构进行一些阅读。一旦掌握了它,它就节省了我很多时间,我永远不会回去。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?