SparkSQLпјҡзӣҙжҺҘиҜ»еҸ–JSONжҲ–еҜ№ж–Ү件жү§иЎҢжҹҘиҜўпјҹ
жҲ‘жңүи®ёеӨҡеӨ§еһӢJSONж–Ү件пјҢжҲ‘жғіеҜ№е…¶иҝӣиЎҢдёҖдәӣеҲҶжһҗгҖӮжҲ‘еҲҡеҲҡејҖе§ӢдҪҝз”ЁSparkSQLпјҢ并且жҲ‘жӯЈеңЁеҠӘеҠӣзЎ®дҝқзҗҶи§Јд»Һж–Ү件дёӯиҺ·еҸ–SparkSQL read the JSON records into an RDD/DataFrameпјҲ并жҺЁж–ӯжЁЎејҸпјүжҲ–run a SparkSQL query on the files directlyд№Ӣй—ҙзҡ„еҘҪеӨ„гҖӮеҰӮжһңжӮЁжңүд»»дҪ•дҪҝз”ЁSParkSQLзҡ„з»ҸйӘҢпјҢжҲ‘дјҡжңүе…ҙи¶Јеҗ¬еҗ¬е“Әз§Қж–№жі•жӣҙеҸ—ж¬ўиҝҺд»ҘеҸҠдёәд»Җд№ҲгҖӮ
жҸҗеүҚж„ҹи°ўжӮЁзҡ„ж—¶й—ҙе’Ңеё®еҠ©пјҒ
1 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ2)
жӮЁеҸҜд»ҘеңЁж•°жҚ®йӣҶдёҠе°Ҷexplain()з§°дёәж“ҚдҪңпјҢиҖҢдёҚжҳҜshow()жҲ–count()гҖӮ然еҗҺSparkдјҡеҗ‘жӮЁжҳҫзӨәжүҖйҖүзҡ„зү©зҗҶи®ЎеҲ’гҖӮ

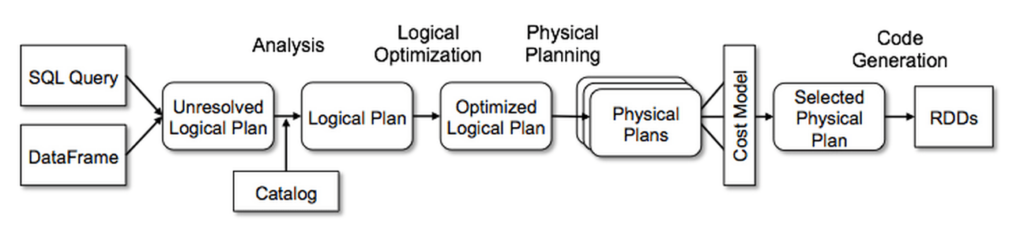
жӮЁеҸҜд»ҘжүҫеҲ°дёҠйқўзҡ„еӣҫзүҮhereгҖӮжҚ®жҲ‘жүҖзҹҘпјҢеә”иҜҘжІЎжңүеҢәеҲ«гҖӮдҪҶжҲ‘жӣҙе–ңж¬ўдҪҝз”Ёread()ж–№жі•гҖӮеҪ“жҲ‘дҪҝз”ЁIDEж—¶пјҢжҲ‘еҸҜд»ҘзңӢеҲ°жүҖжңүеҸҜз”Ёзҡ„ж–№жі•гҖӮеҪ“жӮЁдҪҝз”ЁSQLжү§иЎҢжӯӨж“ҚдҪңж—¶пјҢеҸҜиғҪдјҡеҮәзҺ°й”ҷиҜҜпјҢдҫӢеҰӮslectиҖҢдёҚжҳҜselectпјҢдҪҶеңЁиҝҗиЎҢд»Јз Ғж—¶пјҢжӮЁе°ҶйҰ–е…Ҳ收еҲ°й”ҷиҜҜгҖӮ
{kind=link}
- д»»дҪ•Angularеә“зӣҙжҺҘеңЁjsonдёҠжҹҘиҜўпјҹ
- SparkSQLж—¶й—ҙжҲіжҹҘиҜўеӨұиҙҘ
- SparkSQL - е…ідәҺCollectionпјҲSetпјүзҡ„CassandraSqlContextжҹҘиҜў
- еҰӮдҪ•зӣҙжҺҘйҳ…иҜ»й•¶жңЁең°жқҝж–Ү件иҖҢж— йңҖеңЁSparkSQL
- ж— жі•еңЁjava
- SparkSQLпјҡзӣҙжҺҘиҜ»еҸ–JSONжҲ–еҜ№ж–Ү件жү§иЎҢжҹҘиҜўпјҹ
- SparkSQL - зӣҙжҺҘиҜ»еҸ–镶жңЁең°жқҝж–Ү件
- дҪҝз”Ёsparksqlжү§иЎҢload
- PHPUnitе°Ҷж— жі•жүҫеҲ°жҲ‘зҡ„жөӢиҜ•ж–Ү件жҲ–зӣҙжҺҘжү§иЎҢе®ғ们
- жөӢиҜ•sparksqlжҹҘиҜў
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ