import numpy as np
def nonlin(x, deriv=False):
if (deriv == True):
return (x * (1 - x))
return 1 / (1 + np.exp(-x))
X = np.array([[1,1,1],
[3,3,3],
[2,2,2]
[2,2,2]])
y = np.array([[1],
[1],
[0],
[1]])
np.random.seed(1)
syn0 = 2 * np.random.random((3, 4)) - 1
syn1 = 2 * np.random.random((4, 1)) - 1
for j in xrange(100000):
l0 = X
l1 = nonlin(np.dot(l0, syn0))
l2 = nonlin(np.dot(l1, syn1))
l2_error = y - l2
if (j % 10000) == 0:
print "Error: " + str(np.mean(np.abs(l2_error)))
l2_delta = l2_error * nonlin(l2, deriv=True)
l1_error = l2_delta.dot(syn1.T)
l1_delta = l1_error * nonlin(l1, deriv=True)
syn1 += l1.T.dot(l2_delta)
syn0 += l0.T.dot(l1_delta)
print "Output after training"
print l2
有人可以解释它的印刷内容及其重要性。这段代码对我来说似乎毫无意义。 for循环应该针对给定数据集优化网络中的神经元。但它是如何做到的呢?什么是nonlin功能?这是做什么的?:
syn0 = 2 * np.random.random((3, 4)) - 1
syn1 = 2 * np.random.random((4, 1)) - 1
答案 0 :(得分:2)
这是一个训练神经网络的简单代码:
这是神经元的激活,该函数返回激活函数或其衍生物(它是一个sigmoid函数)。
def nonlin(x, deriv=False):
if (deriv == True):
return (x * (1 - x))
return 1 / (1 + np.exp(-x))
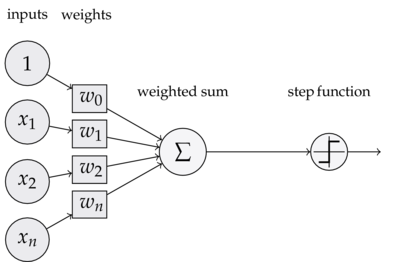
在这张图片中你可以看到一个神经元,这个功能在图片中显示为步进功能:
https://blog.dbrgn.ch/images/2013/3/26/perceptron.png
这些是下雨数据,四个数据有3个功能
X = np.array([[1,1,1],
[3,3,3],
[2,2,2]
[2,2,2]])
每个数据的标签(二进制分类任务)
y = np.array([[1],
[1],
[0],
[1]])
此代码初始化神经网络的权重(它是具有两层权重的神经网络):
np.random.seed(1)
syn0 = 2 * np.random.random((3, 4)) - 1
syn1 = 2 * np.random.random((4, 1)) - 1
在这张图片中,权重是vnm和wkn,是矩阵(每个链接的值)。
在你的情况下,你有3个输入神经元,4个隐藏神经元和1个输出神经元。每个链接的值都存储在syn0和syn1中。
此代码训练神经网络,它传递每个数据,评估错误并使用反向传播更新权重:
for j in xrange(100000):
l0 = X
l1 = nonlin(np.dot(l0, syn0))
l2 = nonlin(np.dot(l1, syn1))
l2_error = y - l2
if (j % 10000) == 0:
print "Error: " + str(np.mean(np.abs(l2_error)))
l2_delta = l2_error * nonlin(l2, deriv=True)
l1_error = l2_delta.dot(syn1.T)
l1_delta = l1_error * nonlin(l1, deriv=True)
syn1 += l1.T.dot(l2_delta)
syn0 += l0.T.dot(l1_delta)
{kind=link}