迭代Rust正则表达式
我正在使用http:// frowns.sourceforge.net提供的frowns解析器,这是一个解析器,用于标记SMILES标准化学公式字符串。具体来说,我正试图将它移植到Rust。
解析器中“atom”标记的原始正则表达式如下所示(Python):
element_symbols_pattern = \
r"C[laroudsemf]?|Os?|N[eaibdpos]?|S[icernbmg]?|P[drmtboau]?|" \
r"H[eofgas]?|c|n|o|s|p|A[lrsgutcm]|B[eraik]?|Dy|E[urs]|F[erm]?|" \
r"G[aed]|I[nr]?|Kr?|L[iaur]|M[gnodt]|R[buhenaf]|T[icebmalh]|" \
r"U|V|W|Xe|Yb?|Z[nr]|\*"
atom_fields = [
"raw_atom",
"open_bracket",
"weight",
"element",
"chiral_count",
"chiral_named",
"chiral_symbols",
"hcount",
"positive_count",
"positive_symbols",
"negative_count",
"negative_symbols",
"error_1",
"error_2",
"close_bracket",
"error_3",
]
atom = re.compile(r"""
(?P<raw_atom>Cl|Br|[cnospBCNOFPSI]) | # "raw" means outside of brackets
(
(?P<open_bracket>\[) # Start bracket
(?P<weight>\d+)? # Atomic weight (optional)
( # valid term or error
( # valid term
(?P<element>""" + element_symbols_pattern + r""") # element or aromatic
( # Chirality can be
(?P<chiral_count>@\d+) | # @1 @2 @3 ...
(?P<chiral_named> # or
@TH[12] | # @TA1 @TA2
@AL[12] | # @AL1 @AL2
@SP[123] | # @SP1 @SP2 @SP3
@TB(1[0-9]?|20?|[3-9]) | # @TB{1-20}
@OH(1[0-9]?|2[0-9]?|30?|[4-9])) | # @OH{1-30}
(?P<chiral_symbols>@+) # or @@@@@@@...
)? # and chirality is optional
(?P<hcount>H\d*)? # Optional hydrogen count
( # Charges can be
(?P<positive_count>\+\d+) | # +<number>
(?P<positive_symbols>\++) | # +++... This includes the single '+'
(?P<negative_count>-\d+) | # -<number>
(?P<negative_symbols>-+) # ---... including a single '-'
)? # and are optional
(?P<error_1>[^\]]+)? # If there's anything left, it's an error
) | ( # End of parsing stuff in []s, except
(?P<error_2>[^\]]*) # If there was an error, we get here
))
((?P<close_bracket>\])| # End bracket
(?P<error_3>$)) # unexpectedly reached end of string
)
""", re.X)
字段列表用于提高正则表达式解析器的可报告性,以及跟踪解析错误。
我写了something that compiles并正确解析了没有括号的标记,但是包含括号(例如[S]而不是S)的内容会破坏它。所以我用评论缩小了它:
extern crate regex;
use regex::Regex;
fn main() {
let atom_fields: Vec<&'static str> = vec![
"raw_atom",
"open_bracket",
"weight",
"element",
"chiral_count",
"chiral_named",
"chiral_symbols",
"hcount",
"positive_count",
"positive_symbols",
"negative_count",
"negative_symbols",
"error_1",
"error_2",
"close_bracket",
"error_3"
];
const EL_SYMBOLS: &'static str = r#"(?P<element>S?|\*")"#;
let atom_re_str: &String = &String::from(vec![
// r"(?P<raw_atom>Cl|Br|[cnospBCNOFPSI])|", // "raw" means outside of brackets
r"(",
r"(?P<open_bracket>\[)", // Start bracket
// r"(?P<weight>\d+)?", // Atomic weight (optional)
r"(", // valid term or error
r"(", // valid term
&EL_SYMBOLS, // element or aromatic
// r"(", // Chirality can be
// r"(?P<chiral_count>@\d+)|", // @1 @2 @3 ...
// r"(?P<chiral_named>", // or
// r"@TH[12]|", // @TA1 @TA2
// r"@AL[12]|", // @AL1 @AL2
// r"@SP[123]|", // @SP1 @SP2 @SP3
// r"@TB(1[0-9]?|20?|[3-9])|", // @TB{1-20}
// r"@OH(1[0-9]?|2[0-9]?|30?|[4-9]))|", // @OH{1-30}
// r"(?P<chiral_symbols>@+)", // or @@@@....,
// r")?", // and chirality is optional
// r"(?P<hcount>H\d*)?", // Optional hydrogen count
// r"(", // Charges can be
// r"(?P<positive_count>\+\d+)|", // +<number>
// r"(?P<positive_symbols>\++)|", // +++...including a single '+'
// r"(?P<negative_count>-\d+)|", // -<number>
// r"(?P<negative_symbols>-+)", // ---... including a single '-'
// r")?", // and are optional
// r"(?P<error_1>[^\]]+)?", // anything left is an error
r")", // End of stuff in []s, except
r"|((?P<error_2>[^\]]*)", // If other error, we get here
r"))",
r"((?P<close_bracket>\])|", // End bracket
r"(?P<error_3>$)))"].join("")); // unexpected end of string
println!("generated regex: {}", &atom_re_str);
let atom_re = Regex::new(&atom_re_str).unwrap();
for cur_char in "[S]".chars() {
let cur_string = cur_char.to_string();
println!("cur string: {}", &cur_string);
let captures = atom_re.captures(&cur_string.as_str()).unwrap();
// if captures.name("atom").is_some() {
// for cur_field in &atom_fields {
// let field_capture = captures.name(cur_field);
// if cur_field.contains("error") {
// if *cur_field == "error_3" {
// // TODO replace me with a real error
// println!("current char: {:?}", &cur_char);
// panic!("Missing a close bracket (]). Looks like: {}.",
// field_capture.unwrap());
// } else {
// panic!("I don't recognize the character. Looks like: {}.",
// field_capture.unwrap());
// }
// } else {
// println!("ok! matched {:?}", &cur_char);
// }
// }
// }
}
}
-
您可以看到生成的Rust正则表达式在Debuggex中起作用:
((?P<open_bracket>\[)(((?P<element>S?|\*"))|((?P<error_2>[^\]]*)))((?P<close_bracket>\])|(?P<error_3>$)))
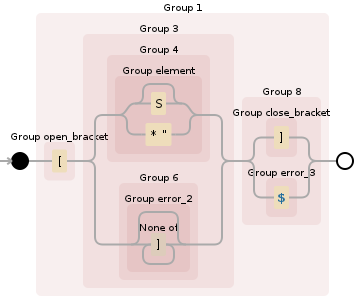
(http://debuggex.com/r/7j75Y2F1ph1v9jfL)
如果您运行示例(https://gitlab.com/araster/frowns_regex),您将看到open括号正确分析,但.captures().unwrap()在下一个字符'S'上死亡。如果我使用完整的表达式,我可以解析frowns测试文件中的所有类型的东西,只要它们没有括号。
我做错了什么?
1 个答案:
答案 0 :(得分:5)
您正在迭代输入字符串的每个字符,并尝试在由单个字符组成的字符串上匹配正则表达式。但是,此正则表达式并非旨在匹配单个字符。实际上,正则表达式将整体匹配[S]。
如果您希望能够在单个字符串中找到多个匹配项,请使用captures_iter代替captures来迭代所有匹配项及其各自的匹配项(每个匹配项将是公式,正则表达式将跳过与公式不匹配的文本。
for captures in atom_re.captures_iter("[S]") {
// check the captures of each match
}
如果您只想在字符串中找到第一个匹配项,则在整个字符串上使用captures,而不是在每个字符上使用。{/ p>
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?