我被困在如何解决问题。我有一个矩阵,格式如下:
Sequence Position Raw Binding (log ratio)
UC001AOZ.3 146 -0.746
UC001AOZ.3 147 -1.27
UC001AOZ.3 148 -1.66
UC001AOZ.3 149 -2.16
UC001AOZ.3 150 -2.08
... ... ...
UC222AOF.2 5000 1.22
UC222AOF.2 146 -1.12
UC222AOF.2 147 -1.41
... ... ...
UC222AOF.2 5000 5.13
... ... ...
第一列(序列)通过这些神秘的名称描述基因。第二列是人类基因组内的位置,第三列是指事件的值。
位置上升至5000,然后在146再次开始下一个基因(参见格式,第二个基因名称" UC222AOF.2")。总共有250个基因,4854个位置和各自的Raw Biding值。
我想获得146到5000之间所有Raw Binding(对数比)值的平均值。
一种可能性如下(值可能与上述不同):
146 147 148 149 ... 5000
UC001AOZ.3 -0.746 -1.27 -1.66 -2.16 ... 1.22
UC222AOF.2 -1.12 -1.41 -1.31 -1.81 ... 5.13
UC002BW1.1 -0.112 -0.31 -0.51 -1.01 ... 1.01
我不是R常规但知道一些基础知识。提前谢谢!
答案 0 :(得分:1)
reshape2包的dcast()函数可能有用。
library(reshape2)
df
# Sequence Position Binding
# 1 UC001AOZ.3 146 -0.746
# 2 UC001AOZ.3 147 -1.270
# 3 UC001AOZ.3 148 -1.660
# 4 UC001AOZ.3 149 -2.160
# 5 UC001AOZ.3 150 -2.080
# 6 UC222AOF.2 5000 1.220
# 7 UC222AOF.2 146 -1.120
# 8 UC222AOF.2 147 -1.410
dcast(df, Sequence ~ Position, value.var = "Binding")
# Sequence 146 147 148 149 150 5000
# 1 UC001AOZ.3 -0.746 -1.27 -1.66 -2.16 -2.08 NA
# 2 UC222AOF.2 -1.120 -1.41 NA NA NA 1.22
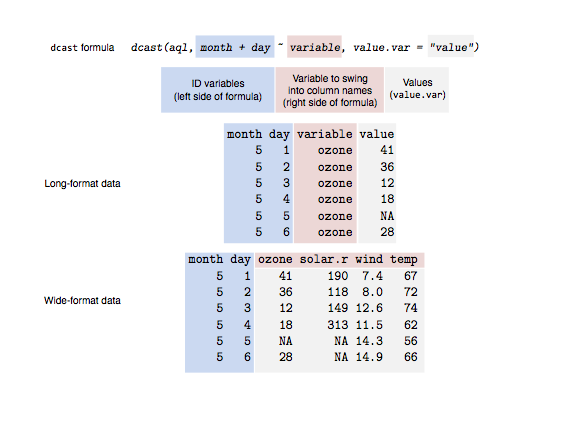
基本上,您将“位置”列“向上”调整为一组行,并告诉R使用“绑定”列中的值来填充新建的行。
来自http://seananderson.ca/images/dcast-illustration.png的http://seananderson.ca/2013/10/19/reshape.html是dcast()函数的绝佳直观表示。
{kind=link}