正则表达式从一长串字符中抓取电子邮件
我有一个大文本文件,这是一个非常长的字符串。我的目标是提取“personEmail”和“created”之间的所有电子邮件地址,文件中还有其他电子邮件,但我想要那些特定的电子邮件。我还想计算文本文件中每个电子邮件地址的出现次数,下面是一个摘录:
GFyazovL3VzL1BFT1BMRS9mNWQzMGMyYi1mZDMyLTRhYTYtYjZhYS1iYTdkYWNjZWZiN2M“,”personEmail“:”user1@provider.com“,”created“:”2016-07-13T19:19:14.934Z“,”html“:”blah-forth data-object-type = \ “person \”data-objectid = \“Y2lzY29zcGFyazovL3VzL1user2@provider.comBFT1BMRS81MjhlZDZiMi1jODM4LTQzNDAtOWE2ZC0xMmRmYzI5YWU5
我希望能够使用grep,sed或awk来实现它,如果可能的话可能会使用uniq -c,我知道如何使用{{1如果有多个字符串,但如果文件只是一个非常长的字符串本身就没有。对此有快速解决方案吗?
1 个答案:
答案 0 :(得分:1)
描述
make; make check; make install 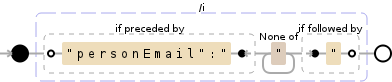
**要更好地查看图像,只需右键单击图像并在新窗口中选择视图
此正则表达式将执行以下操作:
- 找到与
(?<="personEmail":")[^"]+(?=")字段 相关联的值
实施例
现场演示
https://regex101.com/r/aH1nO9/2
示例文字
GFyazovL3VzL1BFT1BMRS9mNWQzMGMyYi1mZDMyLTRhYTYtYjZhYS1iYTdkYWNjZWZiN2M“,”personEmail“:”user1@provider.com“,”created“:”2016-07-13T19:19:14.934Z“,”html“:”blah-forth data-object-type = \ “person \”data-objectid = \“Y2lzY29zcGFyazovL3VzL1user2@provider.comBFT1BMRS81MjhlZDZiMi1jODM4LTQzNDAtOWE2ZC0xMmRmYzI5YWU5
样本匹配
personEmail解释
MATCH 1
0. [87-105] `user1@provider.com`
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?