我正在研究简单的机器学习算法,从简单的梯度下降开始,但是我在尝试在python中实现它时遇到了一些麻烦。
以下是我正在尝试重现的示例,我已经获得了有关房屋的数据(居住面积(以英尺2为单位)和卧室数量),并且得到了价格:
居住面积(英尺2):2104
#bedrooms:3
价格(1000 $ s):400
我正在尝试使用渐变下降法进行简单回归,但我的算法不起作用...... 算法的形式不是故意使用向量(我试图逐步理解它)。
i = 1
import sys
derror=sys.maxint
error = 0
step = 0.0001
dthresh = 0.1
import random
theta1 = random.random()
theta2 = random.random()
theta0 = random.random()
while derror>dthresh:
diff = 400 - theta0 - 2104 * theta1 - 3 * theta2
theta0 = theta0 + step * diff * 1
theta1 = theta1 + step * diff * 2104
theta2 = theta2 + step * diff * 3
hserror = diff**2/2
derror = abs(error - hserror)
error = hserror
print 'iteration : %d, error : %s' % (i, error)
i+=1
我理解数学,我正在构建一个预测函数 $$h_{\theta}(x) = \theta_0 + \theta_1 x_1 + \theta_2 x_2$$ http://mathurl.com/hoy7ege.png $x_1$ http://mathurl.com/2ga69bb.png和$x_2$ http://mathurl.com/2cbdldp.png是变量(居住面积,卧室数量)和$h_{\theta}(x)$ http://mathurl.com/jckw8ke.png估算价格。
我正在使用费用函数($hserror$ http://mathurl.com/guuqjv5.png)(一分): $$hserror = \frac{1}{2} (h_{\theta}(x) - y)^2$$ http://mathurl.com/hnrqtkf.png 这是一个常见的问题,但我更像是一名软件工程师而且我一步一步学习,你能告诉我什么是错的吗?
我使用了这段代码:
data = {(2104, 3) : 400, (1600,3) : 330, (2400, 3) : 369, (1416, 2) : 232, (3000, 4) : 540}
for x in range(10):
i = 1
import sys
derror=sys.maxint
error = 0
step = 0.00000001
dthresh = 0.0000000001
import random
theta1 = random.random()*100
theta2 = random.random()*100
theta0 = random.random()*100
while derror>dthresh:
diff = 400 - (theta0 + 2104 * theta1 + 3 * theta2)
theta0 = theta0 + step * diff * 1
theta1 = theta1 + step * diff * 2104
theta2 = theta2 + step * diff * 3
hserror = diff**2/2
derror = abs(error - hserror)
error = hserror
#print 'iteration : %d, error : %s, derror : %s' % (i, error, derror)
i+=1
print ' theta0 : %f, theta1 : %f, theta2 : %f' % (theta0, theta1, theta2)
print ' done : %f' %(theta0 + 2104 * theta1 + 3*theta2)
最终会得到这样的答案:
theta0 : 48.412337, theta1 : 0.094492, theta2 : 50.925579
done : 400.000043
theta0 : 0.574007, theta1 : 0.185363, theta2 : 3.140553
done : 400.000042
theta0 : 28.588457, theta1 : 0.041746, theta2 : 94.525769
done : 400.000043
theta0 : 42.240593, theta1 : 0.096398, theta2 : 51.645989
done : 400.000043
theta0 : 98.452431, theta1 : 0.136432, theta2 : 4.831866
done : 400.000043
theta0 : 18.022160, theta1 : 0.148059, theta2 : 23.487524
done : 400.000043
theta0 : 39.461977, theta1 : 0.097899, theta2 : 51.519412
done : 400.000042
theta0 : 40.979868, theta1 : 0.040312, theta2 : 91.401406
done : 400.000043
theta0 : 15.466259, theta1 : 0.111276, theta2 : 50.136221
done : 400.000043
theta0 : 72.380926, theta1 : 0.013814, theta2 : 99.517853
done : 400.000043
答案 0 :(得分:8)
第一个问题是,只运行一个数据就可以得到一个欠定系统...这意味着它可能有无数个解决方案。有三个变量,您希望至少有3个数据点,最好是更高。
其次使用梯度下降,其中步长是梯度的缩放版本,除了在解的一个小邻域之外,不保证收敛。你可以通过切换到负梯度(慢)方向的固定大小步骤或负梯度方向的linesearch(更快,但稍微复杂)来解决这个问题。
因此对于固定步长而不是
theta0 = theta0 - step * dEdtheta0
theta1 = theta1 - step * dEdtheta1
theta2 = theta2 - step * dEdtheta2
你这样做
n = max( [ dEdtheta1, dEdtheta1, dEdtheta2 ] )
theta0 = theta0 - step * dEdtheta0 / n
theta1 = theta1 - step * dEdtheta1 / n
theta2 = theta2 - step * dEdtheta2 / n
您的步骤中也可能出现符号错误。
我也不确定恐怖是一个很好的停止标准。 (但是停止标准是非常难以“正确”)
我的最后一点是,参数拟合的梯度下降速度非常慢。您可能希望使用共轭梯度或Levenberg-Marquadt方法。我怀疑这两种方法在numpy或scipy包中已经存在python(默认情况下它们不是python的一部分,但很容易安装)
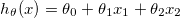{kind=link}
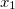{kind=link}
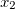{kind=link}
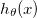{kind=link}
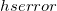{kind=link}
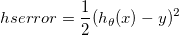{kind=link}