PHP通过regex自动检测translatables / detect代码片段
我有一个多语言网站,它在default.php中存储translatables,其中包含一个包含所有键的数组。
我更愿意让它自动化。 我已经有一个(单例)类,它能够根据类型检测我的所有文件。 (控制器,动作,视图,模型等......)
我想检测格式如下的任何代码:
$this->translate('[a-zA-Z]');
$view->translate('[a-zA-Z]');
getView()->translate('[a-zA-Z]');
throw new Exception('[a-zA-Z]');
addMessage(array('message' => '[a-zA-Z]');
但是当它以/ contains:
开头时必须进行过滤$this->translate('((0-9)+_)[a-zA-Z]');
$this->translate('[a-zA-Z]' . $* . '[a-zA-Z]'); // Only a variable in the middle must filtered, begin or end is still allowed
ofcourse [a-zA-Z]是一个正则表达式的例子。
就像我说,我已经有一个检测某些文件的类。这个类也使用了Reflection(或者在这种情况下使用Zend Reflection,因为我正在使用Zend)但是我看不到使用正则表达式反映函数的方法。
该动作将放在一个cronjob和手动调用动作中,因此当使用的内存有点“太大”时,这不是一个大问题。
1 个答案:
答案 0 :(得分:2)
描述
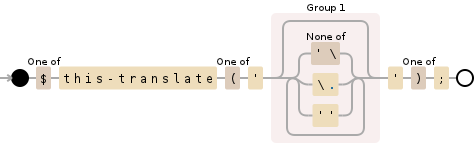
[$]this->translate[(]'((?:[^'\\]|\\.|'')*)'[)];
**要更好地查看图像,只需右键单击图像并在新窗口中选择视图
此正则表达式将执行以下操作:
- 代码块从
$this-translate('开始,直至关闭'); - 将值放在
'引号内的捕获组1 中
- 避免了凌乱的边缘情况,其中子字符串中可能包含看起来像结束
');字符串的字符串,而实际上字符可以被转义。
实施例
现场演示
https://regex101.com/r/eC5xQ6/
示例文字
$This->Translate('(?:Droids\');{2}');
$NotTranalate('fdasad');
$this->translate('[a-zA-Z]');
样本匹配
MATCH 1
1. [17-33] `(?:Droids\');{2}`
MATCH 2
1. [79-87] `[a-zA-Z]`
解释
NODE EXPLANATION
----------------------------------------------------------------------
(?-imsx: group, but do not capture (case-sensitive)
(with ^ and $ matching normally) (with . not
matching \n) (matching whitespace and #
normally):
----------------------------------------------------------------------
[$] any character of: '$'
----------------------------------------------------------------------
this->translate 'this->translate'
----------------------------------------------------------------------
[(] any character of: '('
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
----------------------------------------------------------------------
[^'\\] any character except: ''', '\\'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\\ '\'
----------------------------------------------------------------------
. any character except \n
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
'' '\'\''
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
[)] any character of: ')'
----------------------------------------------------------------------
; ';'
----------------------------------------------------------------------
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?