根据文件中的单词和特殊字符将文本文件拆分为单词
import os
import re
import shutil
import tempfile
import csv
from StringIO import StringIO
import sqlite3
### SQL lite
file="H:/query.txt"
file = open(file, 'r')
text = file.read().lower()
file.close()
text = re.split('\W+',text)
print text
我使用上面的脚本将文件拆分为包含所有单词的列表。 但我希望特殊字符(。,#,_)包含在列表中。
我的意思是如果这个词是p.player我想确保这个词被分割为p.player而不是p和player.same为#和_
我应该在此脚本中做出哪些更改。
提前致谢
2 个答案:
答案 0 :(得分:1)
re.split('[\x7b-\x7f \x20-\x22 \x24-\x40]',<string_here>)
基本上,我采用了大/小写字符范围之外的所有范围,也排除了&#39;#&#39;范围。 \x允许您使用相应的十六进制数
编辑:我刚刚意识到不仅仅是#34;#&#34;在您的范围内。如果你想要包含太多特殊字符,你也可以反过来使用排除范围。它看起来像这样:
re.split('[^\w,_#]',<string_here>)
在这种情况下,事实证明更加清洁
答案 1 :(得分:0)
只需创建一个与您正在寻找的完全匹配的正则表达式,并使用findall命令。
此表达式将匹配单词中可能包含.,#或_的所有1个字符或更长的字词。
[a-z](?:[a-z.#_]*[a-z])?
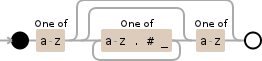
示例Python脚本
import re
regex = ur"[a-z](?:[a-z.#_]*[a-z])?"
line = "word is p.player I want to make sure the word is split as p.player not as p and player."
words = re.findall(regex, line, re.IGNORECASE)
print(words)
示例输出
['word', 'is', 'p.player', 'I', 'want', 'to', 'make', 'sure', 'the', 'word', 'is', 'split', 'as', 'p.player', 'not', 'as', 'p', 'and', 'player']
直播演示
- 正则表达式:https://regex101.com/r/vO8aE8/1
- Python:https://repl.it/C74X/12
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?