在notepad ++中用正则表达式替换转换逗号分隔的空格
我用逗号分隔标记, 我需要将它们转换为以空格分隔的冒号中的标记。 我想在记事本++中使用正则表达式,但遇到了问题。
我的意见是:
aaaaa, bbb ,cccc, hhhh, fff,t
我想得到结果:
aaaaa bbb cccc hhhh fff t
每个令牌只有10个字符
我的问题是如何使输出正好10个字符?
3 个答案:
答案 0 :(得分:8)
描述
我认为这是一个两步过程。第一步用10个空格替换所有逗号。第二步捕获10个字符和所有尾随空格,并仅用10个捕获的字符替换。
第一步 - 用10个空格替换逗号
,\s*|\s*$
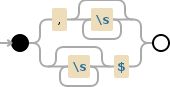
替换为: __________这些是unbars,但您应该使用十个或更多空格。
现场演示: https://regex101.com/r/mR1eS9/1
示例文字
aaaaa, bbb ,cccc, hhhh, fff,t
替换后
aaaaa bbb cccc hhhh fff t
123456789,123456789,123456789,123456789,123456789,123456789,123456789,123456789
注意:我在这里插入数字行以帮助说明字符的数量和位置
第二步 - 捕获10个字符和所有尾随空格
(.{10})[^\S\n\r]*
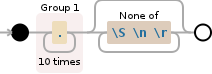
替换为: $1
现场演示: https://regex101.com/r/uL8oO7/2
示例文字
因为这是第二步,所以示例文本是上面第一步的输出
aaaaa bbb cccc hhhh fff t
替换后
aaaaa bbb cccc hhhh fff t
123456789,123456789,123456789,123456789,123456789,123456789,123456789,123456789
注意:我在这里插入数字行以帮助说明字符的数量和位置
答案 1 :(得分:6)
正则表达式计算模型非常简单,无法计算。但是,在您只有九个可能的非空匹配的情况下,您可以运行九个单独的全局替换以涵盖所有可能性(为了清楚起见,使用下划线_代替空格):
Search Replacement
------------- -----------
(?<=\b\S{9}),\s _
(?<=\b\S{8}),\s __
(?<=\b\S{7}),\s ___
(?<=\b\S{6}),\s ____
...
(?<=\b\S{1}),\s _________
每个替换操作都匹配x个非空格字符后面的逗号空格对,并用10-x个空格替换它们。
答案 2 :(得分:2)
使用编程语言的解决方案可能更适合阅读和理解
查找以下PHP和Python的代码示例(也可以轻松采用其他语言):
PHP
<?php
$string = "aaaaa, bbb ,cccc, hhhh, fff,t";
$regex = '~(\w+)(\s*,|$)~';
# look for word characters, followed by spaces (or not)
# and a comma or the end of the string
$string = preg_replace_callback(
$regex,
function($match) {
return str_pad($match[1], 10);
},
$string);
echo $string;
# aaaaa bbb cccc hhhh fff t
?>
<小时/>
的Python
import re
string = "aaaaa, bbb ,cccc, hhhh, fff,t";
def repl(match):
return match.group(1).ljust(10)
rx = r'(\w+)(\s*,|$)'
string = re.sub(rx, repl, string)
print string
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?