通过正则表达式匹配一个不是8个字符(数字/ a-z / A-Z)长字
这是我发布的第一个问题,对于我可能搞砸的任何事情感到抱歉。
我花了一个小时的时间进行实验,并在Notepad ++中通过常规搜索一种用空格替换“不是8个字符(数字/ az / AZ)长字”的方法(换句话说,删除除了那些字之外的任何字)表达式。
我设法将包含它们的行添加为书签,但是我坚持使用包含该词的整行,我只想要那些特定的单词。非常感谢任何帮助,非常感谢!
Edit2:更好的说法是:
删除任何不是:8字符长,以S开头,只包含数字和字母。换句话说,删除任何不是S *******的东西,其中* =数字,字母
编辑:我意识到这还不足以理解这种情况所以这是一个例子。我想处理这个:
Here's your first code: S284JF2B
Here's your second code: SKE093JF
Here's your third code: S28fka30
获得此输出:
S284JF2B
SD34EQ5M
SASFKA30
实际文件有很多其他字符,不仅仅是数字/字母,输出中我想要的代码总是8个字符长(数字/大写字母),总是以S开头。
5 个答案:
答案 0 :(得分:1)
要匹配除示例中的所有内容之外的所有内容:
COPY
要进行现场演示,请参阅https://regex101.com/r/rW8mF0/4
匹配任何非8个字符的字词:
S3

匹配长度为1 - 7 OR 长度为9及以上的单词。
要进行现场演示,请参阅https://regex101.com/r/fX2sE5/1
答案 1 :(得分:1)
描述
缺少任何正确的示例,这将找到长度为8个字符且不包含任何字母的子字符串。子字符串必须由空格或字符串的开头或结尾括起来
MaxLength 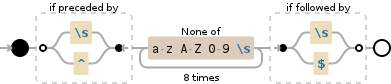
实施例
现场演示
https://regex101.com/r/gS9uN7/1
示例文字
我花了过去一小时的时间进行实验并寻找一种方法来替换“不是8个字符(数字/ az / AZ) $#@!#$>< fd long word”通过正则表达式在Notepad ++中使用空格(或者换句话说删除除了那些单词之外的任何内容)。
样本匹配
(?<=\s|^)[^a-zA-Z0-9\s]{8}(?=\s|$)
替换后
我花了过去一小时的时间进行实验,并在Notepad ++中搜索用空格替换“不是8个字符(数字/ az / AZ)fd长字”的方法(换句话说,删除除了那些字之外的任何字)正则表达式。
解释
$#@!#$><
答案 2 :(得分:1)
我有两种可能的解决方案。两种解决方案都要求字符串长度为8个字符,并以S开头。
鉴于此示例文本:
the problem is it's not the words that do not contain any words that I don't want
but actually any string that isn't a string that starts with an S and is 8 character long.
Example: S294KS12 this is the type of string I want on the document. Contains 8 characters
that are either digits or letters and starts with an S
SOMETIME
S294KS12
S1234567
S123456A
选项1
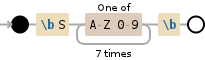
此解决方案仅查找长度为8个字符且以S开头的字符串。
\bS[A-Z0-9]{7}\b
现场演示
https://regex101.com/r/lK0aO9/1
来自示例的匹配
S294KS12
SOMETIME
S294KS12
S1234567
S123456A
<强>解释
NODE EXPLANATION
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
S 'S'
----------------------------------------------------------------------
[A-Z0-9]{7} any character of: 'A' to 'Z', '0' to '9'
(7 times)
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
选项2
此解决方案会进行额外检查,以确保至少有一个附加字母和一个数字。
\bS(?=[A-Z]*[0-9])(?=[0-9]*[A-Z])[A-Z0-9]{7}\b

现场演示
https://regex101.com/r/vH4lX2/3
来自示例的匹配
S294KS12
S294KS12
S123456A
<强>解释
NODE EXPLANATION
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
S 'S'
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
[A-Z]* any character of: 'A' to 'Z' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
[0-9] any character of: '0' to '9'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
[0-9]* any character of: '0' to '9' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
[A-Z] any character of: 'A' to 'Z'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
[A-Z0-9]{7} any character of: 'A' to 'Z', '0' to '9'
(7 times)
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
全部放在一起
要替换其他所有内容,我会将正则表达式编入( ... )\s?|.,这将匹配所有内容,包括所需的字符串。
如果您在Notepad ++的“替换为”选项中使用$1,那么您将只剩下所需的字符串。
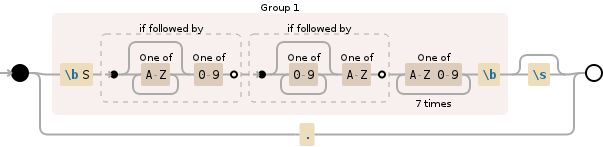
我建议使用上面的选项2,然后将其插入到表达式中,使其如下所示:
(\bS(?=[A-Z]*[0-9])(?=[0-9]*[A-Z])[A-Z0-9]{7}\b)\s?|.
替换为: $1
现场演示
答案 3 :(得分:0)
我尝试使用以下文字将您的问题与其他非字母数字字符相匹配。
<protocol="toto" john="doe" Here's your first code: S284JF2B sign="+" />
<protocol="toto" john="doe" Here's your second code: SKE093JF sign="+" />
<protocol="toto" john="doe" 8char="s2345678" Here's your third code: S28fka30 sign="+" />
我使用了以下正则表达式
\b(\w{1,7}|(?=[^S])\w{8}|S(?![A-Za-z0-9]{8})\w{8}|\w{9,})\b|[^\w\r\n]
我在替换任何内容时只获取了代码,并在替换窗口中选择了“匹配大小写”选项。
在这里进行现场演示:https://regex101.com/r/wW3eB1
<强>说明:
-
\b(...)\b:边界之间的字 -
\w{1,7}:1至7个字母的字数 -
(?=[^S])\w{8}:8个字母的单词,不以'S'开头 -
S(?![A-Za-z0-9]{8})\w{8}:以'S'开头的单词,包含8个字符但包含除字母数字以外的其他内容(即下划线) -
|\w{9,}:9个字母以上的字数 -
[^\w\r\n]:既不是单词也不是EOL字符的字符
答案 4 :(得分:0)
我使用以下正则表达式^.*(S[A-Z0-9]{7})(?!=[A-Z0-9]).*$:
- 控制 + ħ
- 找到:
$1 - 替换为:
. matches newline - 请勿查看
^ : begining of line .* : any character 0 or more times ( : start group 1 S[A-Z0-9]{7}: S followed by 7 alphanumeric characters ) : end group (?!=[A-Z0-9]) : negative lookahead to make sure there are no alphanum after .* : any character 0 or more times $ : end of line - 全部替换
<强>解释
<html>
<head>
<title></title>
<style type="text/css">
svg {
width: 30%;
margin: 0 auto;
;
}
#hex {
stroke-width: 1;
stroke: #2f1522;
}
.rotate {}
</style>
</head>
<body>
<svg viewbox="0 0 200 200" version="1.1" xmlns="http://www.w3.org/2000/svg">
<defs>
<pattern id="img" patternUnits="userSpaceOnUse" width="100" height="100">
<image xlink:href="https://farm4.staticflickr.com/3165/5733278274_2626612c70.jpg" x="-40" transform="rotate(-90 50 50)" width="150" height="100" />
</pattern>
</defs>
<polygon id="hex" points="50 1 95 25 95 75 50 99 5 75 5 25" fill="url(#img)" transform="rotate(90 50 50)"/>
</svg>
</body>
</html>
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?