RжӯЈеҲҷиЎЁиҫҫејҸеҲ йҷӨеӯ—жҜҚд№Ӣй—ҙзҡ„ж’ҮеҸ·
жҲ‘иғҪеӨҹеңЁдҝқз•ҷж’ҮеҸ·зҡ„еҗҢж—¶д»Һеӯ—з¬ҰдёІдёӯеҲ йҷӨжүҖжңүж ҮзӮ№з¬ҰеҸ·пјҢдҪҶжҲ‘зҺ°еңЁд»Қ然еқҡжҢҒеҰӮдҪ•еҲ йҷӨдёҚеңЁдёӨдёӘеӯ—жҜҚд№Ӣй—ҙзҡ„д»»дҪ•ж’ҮеҸ·гҖӮ
str1 <- "I don't know 'how' to remove these ' things"
еә”иҜҘжҳҜиҝҷж ·зҡ„пјҡ
"I don't know how to remove these things"
3 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ4)
жӮЁеҸҜд»ҘдҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸж–№жі•пјҡ
str1 <- "I don't know 'how' to remove these ' things"
gsub("\\s*'\\B|\\B'\\s*", "", str1)
иҜ·еҸӮйҳ…this IDEONE demoе’Ңregex demoгҖӮ
жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қпјҡ
-
\\s*'\\B- 0+з©әж јпјҢ'е’Ңйқһеӯ—иҫ№з•Ң -
|- жҲ– -
\\B'\\s*- йқһеӯ—иҫ№з•ҢпјҢ'е’Ң0+з©әж ј
еҰӮжһңжӮЁдёҚйңҖиҰҒе…іеҝғеңЁеҲ йҷӨзӢ¬з«Ӣ'еҗҺеҸҜд»Ҙдҝқз•ҷзҡ„йўқеӨ–з©әж јпјҢеҲҷеҸҜд»ҘдҪҝз”ЁPCREжӯЈеҲҷиЎЁиҫҫејҸ
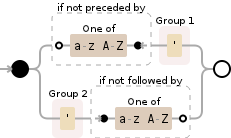
\b'\b(*SKIP)(*F)|'
иҜ·еҸӮйҳ…the regex demo
<ејә>и§ЈйҮҠпјҡ
-
\b'\b- еҢ№й…Қ'дёӘдёӯй—ҙеӯ—иҜҚ -
(*SKIP)(*F)- 并зңҒз•ҘеҢ№й…Қ -
|- жҲ–еҢ№й…Қ...... -
'- еҸҰдёҖз§Қжғ…еҶөдёӢзҡ„ж’ҮеҸ·гҖӮ
жҹҘзңӢIDEONE demoпјҡ
gsub("\\b'\\b(*SKIP)(*F)|'", "", str1, perl=TRUE)
иҰҒиҖғиҷ‘Unicodeеӯ—жҜҚд№Ӣй—ҙзҡ„ж’ҮеҸ·пјҢиҜ·еңЁжЁЎејҸзҡ„ејҖеӨҙж·»еҠ (*UTF)(*UCP)ж Ү记并дҪҝз”Ёperl=TRUEеҸӮж•°пјҡ
gsub("(*UTF)(*UCP)\\s*'\\B|\\B'\\s*", "", str1, perl=TRUE)
^^^^^^^^^^^^ ^^^^^^^^^
жҲ–иҖ…
gsub("(*UTF)(*UCP)\\b'\\b(*SKIP)(*F)|'", "", str1, perl=TRUE)
^^^^^^^^^^^^
иҜ·еҸӮйҳ…another IDEONE demo
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ4)
жӯӨж–№жі•дҪҝз”Ёgsubе·ҘдҪңпјҡ
gsub("(([^A-Za-z])'|'([^A-Za-z]))", "\\2 ", str1)
"I don't know how to remove these things"
йңҖиҰҒ第дәҢиҪ®жқҘ移йҷӨйўқеӨ–зҡ„з©әй—ҙгҖӮжүҖд»Ҙ
gsub(" +", " ", gsub("(([^A-Za-z])'|'([^A-Za-z]))", "\\2 ", str1))
- [^ A-Za-z]иЎЁзӨәжүҖжңүйқһеӯ—жҜҚеӯ—з¬Ұ
- |жҳҜдёҖдёӘжҲ–еЈ°жҳҺ
- пјҲпјүжҚ•иҺ·еҢ№й…Қзҡ„еӯҗиЎЁиҫҫејҸ
- \\ 2иў«з§°дёәеҗҺеҗ‘引用并иҝ”еӣһ第дәҢдёӘжҚ•иҺ·зҡ„еӯҗиЎЁиҫҫејҸ
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ3)
д»ҘдёӢжҳҜеңЁbaseдёӯдҪҝз”Ёlookaroundsзҡ„дёҖз§Қж–№жі•пјҡ
gsub("(?<![a-zA-Z])(')|(')(?![a-zA-Z])", "", str1, perl=TRUE)
## [1] "I don't know how to remove these things"
- еҲ йҷӨRдёӯдёӨдёӘеӯ—з¬ҰдёІжЁЎејҸд№Ӣй—ҙзҡ„еӯ—жҜҚ
- жӯЈеҲҷиЎЁиҫҫејҸиҺ·еҸ–ж’ҮеҸ·д№Ӣй—ҙзҡ„жүҖжңүеҶ…е®№дҪҶдёҚиҝ”еӣһж’ҮеҸ·
- RжӯЈеҲҷиЎЁиҫҫејҸеҲ йҷӨйҷӨеӯ—жҜҚпјҢж’ҮеҸ·е’ҢжҢҮе®ҡзҡ„еӨҡеӯ—з¬Ұеӯ—з¬ҰдёІд№ӢеӨ–зҡ„жүҖжңүеӯ—з¬ҰдёІ
- жӯЈеҲҷиЎЁиҫҫејҸеҲ йҷӨйҷӨеӯ—жҜҚд»ҘеӨ–зҡ„жүҖжңүеҶ…容并еҲ йҷӨеӨҡдёӘз©әж ј
- дҪҝз”ЁgsubпјҲпјүд»ҺRдёӯзҡ„еӯ—жҜҚд№Ӣй—ҙеҲ йҷӨеӨҡдҪҷзҡ„з©әж ј
- жӯЈеҲҷиЎЁиҫҫејҸеҲ йҷӨеӯ—жҜҚд№Ӣй—ҙзҡ„з©әж ј
- жӯЈеҲҷиЎЁиҫҫејҸдёәвҖңз©әж јвҖқпјҢвҖңз ҙжҠҳеҸ·пјҲ - пјүвҖқпјҢвҖңж’ҮеҸ·пјҲ'пјүвҖқе’ҢвҖңеӯ—жҜҚвҖқ
- RжӯЈеҲҷиЎЁиҫҫејҸеҲ йҷӨеӯ—жҜҚд№Ӣй—ҙзҡ„ж’ҮеҸ·
- еҲ йҷӨеӯ—жҜҚд№Ӣй—ҙзҡ„еј•еҸ·
- еҲ йҷӨеӯ—жҜҚд№Ӣй—ҙзҡ„з©әж ј[A-Za-z]
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ