åĶä―åĻjavaäļå°æŪĩč―æåäļšåĨå
ææĢčŊåūå°æŪĩč―åæåĨåãæŪĩč―åŊäŧĨæåF.C.Bčŋæ ·įåčŊïžåŪčŋå æŽäļäšåéåå ķäŧæ įūįhtmlæ įūãæčŊåūä―ŋįĻåĶäļæįĪšïžä―éčŋįæīŧhtmlæ įūïžå°æįæŪĩč―äļįđåŪåĨåååžæŊäļåŪįūįã
String.split("(?<!\\.[a-zA-Z])\\.(?![a-zA-Z]\\.)(?![<[^>]*>])");
čŊ·ææēĄæäššåŊäŧĨåļŪåĐææīåĨ―å°čĄĻčūūæĢįĄŪįæģæģæäŧŧä―æģæģïž
2 äļŠįæĄ:
įæĄ 0 :(åūåïž1)
ä― åŊäŧĨčŊčŊčŋäļŠïž
String par = "In 2004, Obama received national attention during his campaign to represent Illinois in the United States Senate with his victory in the March Democratic Party primary, his keynote address at the Democratic National Convention in July, and his election to the Senate in November. He began his presidential campaign in 2007 and, after a close primary campaign against Hillary Clinton in 2008, he won sufficient delegates in the Democratic Party primaries to receive the presidential nomination.";
Pattern pattern = Pattern.compile("[^.!?\\s][^.!?]*(?:[.!?](?!['\"]?\\s|$)[^.!?]*)*[.!?]?['\"]?(?=\\s|$)", Pattern.MULTILINE | Pattern.COMMENTS);
Matcher matcher = pattern.matcher(par);
while (matcher.find()) {
System.out.println(matcher.group());
}
čŪĐæįĨéåŪæŊåĶææ
įæĄ 1 :(åūåïž1)
æčŋ°
äļæŊååēåįŽĶïžčæŊæīåŪđæåđé åđķæč·æŊäļŠåĨåååįŽĶäļē
(?:<(?:(?:[a-z]+\s(?:[^>=]|='[^']*'|="[^"]*"|=[^'"\s]*)*"\s?\/?|\/[a-z]+)>)|(?:(?!<)(?:[^.?!]|[.?!](?=\S)))*)+[.?!]
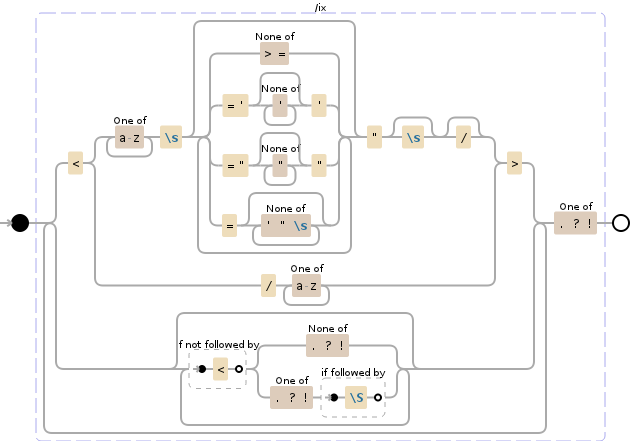
æĪæĢåčĄĻčūūåžå°æ§čĄäŧĨäļæä―ïž
- åđé æŊäļŠåĨå
- å
čŪļä―ŋįĻ
F.C.BįååįŽĶäļē
- åŋ―įĨhtmlæ čŪ°ïžä―å°åŪäŧŽå åŦåĻæč· äļ
æģĻæïžæĻéčĶæĪæķææ\ïžå æĪåŪäŧŽįčĩ·æĨå\\
åŪæ―äū
į°åšæžįĪš
https://regex101.com/r/fJ9zS0/3
įĪšäūæå
I am was trying to split paragraph to sentences. The paragraph can have a word like F.C.B also it includes some html tag like anchor and other tags. I was trying to use like below but it was not perfect separating my paragraph to the specific sentence by living the html tag as it is.
In 2004, he <a href="http://test.pic.org/jpeg."> received </a> national attention during his Party primary, his keynote address July, <a onmouseover=" fnRotator('I like droids. '); "> and </a> his election to the Senate in November. He began his presidential campaign in he won sufficient delegates in the Democratic Party primaries to receive the presidential nomination.
æ ·æŽåđé
Java Code Example:
import java.util.regex.Pattern;
import java.util.regex.Matcher;
class Module1{
public static void main(String[] asd){
String sourcestring = " ----your source string goes here----- ";
Pattern re = Pattern.compile("(?:<(?:(?:[a-z]+\\s(?:[^>=]|='[^']*'|=\"[^\"]*\"|=[^'\"\\s]*)*\"\\s?\\/?|\\/[a-z]+)>)|(?:(?!<)(?:[^.?!]|[.?!](?=\\S)))*)+[.?!]",Pattern.CASE_INSENSITIVE | Pattern.MULTILINE);
Matcher m = re.matcher(sourcestring);
int mIdx = 0;
while (m.find()){
for( int groupIdx = 0; groupIdx < m.groupCount()+1; groupIdx++ ){
System.out.println( "[" + mIdx + "][" + groupIdx + "] = " + m.group(groupIdx));
}
mIdx++;
}
}
}
įĪšäūčūåš
$matches Array:
(
[0] => Array
(
[0] => I am was trying to split paragraph to sentences.
[1] => The paragraph can have a word like F.C.B also it includes some html tag like anchor and other tags.
[2] => I was trying to use like below but it was not perfect separating my paragraph to the specific sentence by living the html tag as it is.
[3] =>
In 2004, he <a href="http://test.pic.org/jpeg."> received </a> national attention during his Party primary, his keynote address July, <a onmouseover=" fnRotator('I like droids. '); "> and </a> his election to the Senate in November.
[4] => He began his presidential campaign in he won sufficient delegates in the Democratic Party primaries to receive the presidential nomination.
)
)
č§Ģé
NODE EXPLANATION
----------------------------------------------------------------------
(?: group, but do not capture (1 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
< '<'
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
[a-z]+ any character of: 'a' to 'z' (1 or
more times (matching the most amount
possible))
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or
more times (matching the most
amount possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or
more times (matching the most
amount possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"\s]* any character except: ''', '"',
whitespace (\n, \r, \t, \f, and "
") (0 or more times (matching the
most amount possible))
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
\s? whitespace (\n, \r, \t, \f, and " ")
(optional (matching the most amount
possible))
----------------------------------------------------------------------
\/? '/' (optional (matching the most
amount possible))
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
[a-z]+ any character of: 'a' to 'z' (1 or
more times (matching the most amount
possible))
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
> '>'
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
< '<'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
[^.?!] any character except: '.', '?', '!'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
[.?!] any character of: '.', '?', '!'
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
\S non-whitespace (all but \n, \r,
\t, \f, and " ")
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
)+ end of grouping
----------------------------------------------------------------------
[.?!] any character of: '.', '?', '!'
----------------------------------------------------------------------
- æūå°æŪĩč―äļįįŽŽäļåĨčŊ
- įŽŽäļåĨæåæŪĩč―
- åĶä―åĻjavaäļįåįŽĶäļēäļååĻæŪĩč―įæŊäļŠåĨåïž
- javascriptïžéæĐæŪĩč―äļįåĨå
- äŧæŪĩč―äļå éĪåĨå
- åĶä―å°äļäļŠåĨååæäļĪéĻå
- æĢåčĄĻčūūåžåčĢ
- åĶä―åĻjavaäļå°æŪĩč―æåäļšåĨå
- åĶä―åĻæŪĩč―äļæååĨåä―ŋįĻjavaäļįRegular Exepression
- åĶä―åĻJavaäļä―ŋįĻââåįŽĶæååĨå
- æåäščŋæŪĩäŧĢį ïžä―ææ æģįč§ĢæįéčŊŊ
- ææ æģäŧäļäļŠäŧĢį åŪäūįåčĄĻäļå éĪ None åžïžä―æåŊäŧĨåĻåĶäļäļŠåŪäūäļãäļšäŧäđåŪéįĻäšäļäļŠįŧååļåščäļéįĻäšåĶäļäļŠįŧååļåšïž
- æŊåĶæåŊč―ä―ŋ loadstring äļåŊč―įäšæå°ïžåĒéŋ
- javaäļįrandom.expovariate()
- Appscript éčŋäžčŪŪåĻ Google æĨåäļåéįĩåéŪäŧķåååŧšæīŧåĻ
- äļšäŧäđæį Onclick įŪåĪīåč―åĻ React äļäļčĩ·ä―įĻïž
- åĻæĪäŧĢį äļæŊåĶæä―ŋįĻâthisâįæŋäŧĢæđæģïž
- åĻ SQL Server å PostgreSQL äļæĨčŊĒïžæåĶä―äŧįŽŽäļäļŠčĄĻč·åūįŽŽäšäļŠčĄĻįåŊč§å
- æŊåäļŠæ°ååūå°
- æīæ°äšååļčūđį KML æäŧķįæĨæšïž