不匹配的正则表达式灾难性回溯
在进行任何编码之前,我正在https://regex101.com/中测试我的正则表达式。
正则表达式:
\[(.*?)\]((?:.\s*)*?)\[\/\1\]
示例字符串:
[tag1]测试文本测试文本测试文本测试文本。
测试文本测试文本测试"文本测试文本"测试文本测试文本。
测试文字?测试文本测试文本测试文本测试文本测试文本测试 文本。
测试文本,测试文本测试文本测试文本测试文本测试文本测试文本 测试文本。[/ tag1]
[tag2]测试文本测试文本测试文本测试文本。
测试文本测试文本测试"文本测试文本"测试文本测试文本。
测试文字?测试文本测试文本测试文本测试文本测试文本测试 文本。
测试文本,测试文本测试文本测试文本测试文本测试文本测试文本 测试文本。[/ tag2]
...
...
我试图在一些长字符串中捕获2个组。第一个是方括号内的文本,第二个是标记内的文本。
当正则表达式匹配时,上面的正则表达式和字符串没有任何问题。如果匹配,则每个匹配步数仅为1000+。但是如果开始和结束标记不匹配,则会发生灾难性的回溯,匹配以126.000+步完成,并停止查找其他匹配的字符串。
我知道,防止回溯问题是避免使用具有" +"的嵌套结构。或" *"但我似乎无法知道更好的方法。
也许有人可以提供或建议比我的更好的正则表达式?
3 个答案:
答案 0 :(得分:1)
我认为由于这种模式,灾难性的回溯出现了:
(?:.\s*)*?
在一个可以重复的组中嵌套重复总是会给正则表达式引擎带来痛苦。查看你的正则表达式图表,清楚你的模式正在创造一个丑陋的开销:
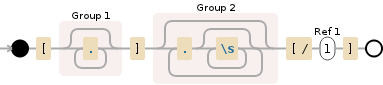
你可以改进你的正则表达式,使其具有这样的模式:
\[(.*?)\](.*?)\[\/\1\] // Using single line flag
(?s)\[(.*?)\](.*?)\[\/\1\] // Using inline single line flag
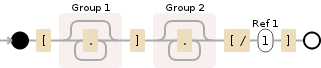
<强> Working demo
另外,如果你不想使用单行标志,你可以使用这样的小技巧:
\[(.*?)\]([\s\S]*?)\[\/\1\]
此外,使用+(1个或更多)运算符代替*(0或更多)运算符可能会很有用:
\[(.+?)\](.+?)\[\/\1\]

答案 1 :(得分:1)
显然,这个正则表达式:\[([^\]]+)\]([^\[]+)\[\/\1\]的步数要少得多。谢谢你的所有答案。
答案 2 :(得分:1)
前言
首先,使用适当的测试环境。如果在.NET中使用正则表达式,请不要在不支持.NET正则表达式的正则表达式测试程序中进行测试。
Regex101.com不支持.NET正则表达式!
你的正则表达式模式不会导致你在 RegexStorm.net 发布的字符串发生任何灾难性的回溯。
根本原因
好的,正则表达式模式非常糟糕且效率低下。为什么? (?:.\s*)*?(包含在一些更大的模式中,就像它本身一样,独立,它不会有问题),匹配任何跟随零或更多(因此,可选)空格的字符,所有这些重复0次或更多次,但尽量少。因此,.和\s*都可以匹配相同的字符串。当您将其包装在组中并添加量词时,正则表达式引擎尝试的可能匹配组合的总数会呈指数级增长。
增强模式
增强不是那么明显,但许多人会得到像Federico给出的解决方案:使用懒惰点匹配模式。因此,(?s)\[([^]]*)](.*?)\[/\1](demo)看起来是可行的解决方案。它在RegexHero.net处每秒产生7,843次迭代。
使用展开循环方法,我们可以根据输入提高正则表达式 n 次。在这里,我们可以将.*?子模式编写为任何字符,但[和任何[不跟/\1]一直到\[/\1]。这可以用否定的字符类和1个量化组内的前瞻编写(它甚至不需要任何修饰符或标志):
\[([^]]*)]([^[]*(?:\[(?!/\1])[^[]*)*)\[/\1]
见this RegexStorm demo。这种正则表达式模式每秒产生114,225次迭代。这是因为[和[tag1]之间根本没有[/tag1],如果字符串包含大量[或仅包含{{1},性能会变差(这不应该发生在现实生活中)。
测试
这是RegexHero测试:

您的原始正则表达式在该网站上仅产生了5,094 ips。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?