如果正则表达式不在标记
我正在尝试匹配'<TAG2>',只要它不在<TAG>内。
例如:
This is a WORD --- Match
<TAG><TAG2>xxx</TAG2></TAG> --- Not a match
<TAG>xxxxxxx<TAG2>yyyy</TAG2>xxxxxxx</TAG> --- Not a match
我正在使用PHP,所以我不能做一个可变长度负面的后视。
我尝试在Match text not inside span tags中使用正则表达式,但如果有多个标记,这在我的情况下不起作用。
<TAG><TAG2>xxx</TAG2></TAG>
<TAG><TAG2>xxx</TAG2></TAG> - This will match from the first <TAG2> to the end of the second </TAG2>. I'm assuming this is because my regex includes <TAG2>[\s\S]*</TAG2>
1 个答案:
答案 0 :(得分:1)
Foreward
我建议使用解析引擎,但听起来您可以对HTML的复杂性进行创造性控制。因此,只要您没有复杂的嵌套情况或其他奇怪的边缘情况,那么这应该可行。
描述
(<tag2>.*?</tag2>)|<tag>(?:(?!<tag\s?>).)*
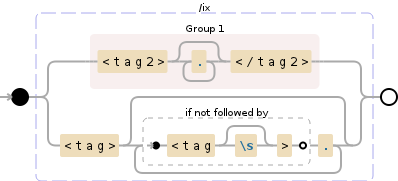
此正则表达式将执行以下操作:
- 使用
<tag2>...</tag2填充捕获组1,前提是此标记尚未包含在<tag>...</tag>内,如<tag>.<tag2>..</tag2>.</tag> - 这也将匹配所有
<tag>...<tag>,但是在匹配发生的地方,捕获组1将没有值。
实施例
现场演示
https://regex101.com/r/uQ7xR5/1
示例文字
This <tag2>is a WORD</tag2> --- Match
<TAG><TAG2>xxx</TAG2></TAG> --- Not a match
<TAG>xxxxxxx<TAG2>yyyy</TAG2>xxxxxxx</TAG> --- Not a match
样本匹配
请注意,捕获组1仅由<tag2>...</tag2表示,而<tag>..</tag>
[0][0] = <tag2>is a WORD</tag2>
[0][1] = <tag2>is a WORD</tag2>
[1][0] = <TAG><TAG2>xxx</TAG2></TAG> --- Not a match
[1][1] =
[2][0] = <TAG>xxxxxxx<TAG2>yyyy</TAG2>xxxxxxx</TAG> --- Not a match
[2][1] =
解释
NODE EXPLANATION
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
<tag2> '<tag2>'
----------------------------------------------------------------------
.*? any character except \n (0 or more times
(matching the least amount possible))
----------------------------------------------------------------------
</tag2> '</tag2>'
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
<tag> '<tag>'
----------------------------------------------------------------------
(?: group, but do not capture (0 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
<tag '<tag'
----------------------------------------------------------------------
\s? whitespace (\n, \r, \t, \f, and " ")
(optional (matching the most amount
possible))
----------------------------------------------------------------------
> '>'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
. any character except \n
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?