MySQL匹配正则表达式
当涉及到匹配字符串中的空格时,我在Mysql中使用正则表达式语法时遇到问题。
我有一个Zipcodes数据库,格式为:
1111 AA CITYNAME或1111 CITYNAME。
由此,我想提取zipcode和cityname,我使用了以下代码:
DROP FUNCTION IF EXISTS GET_POSTALCODE;
CREATE FUNCTION GET_POSTALCODE(input VARCHAR(255))
RETURNS VARCHAR(255)
BEGIN
DECLARE output VARCHAR(255) DEFAULT '';
IF input LIKE '^[1-9][0-9]{3}[[:blank:]][A-Z]{2}[[:blank:]]%'
THEN
SET output = SUBSTRING(input, 1, 7);
ELSE
SET output = SUBSTRING(input, 1, 4);
END IF;
RETURN output;
END
我希望将9741 NE Groningen的输入字符串的结果拆分为9741 NE和Groningen。
但我得到9741和NE Groningen。
我已经尝试过各种各样的东西来匹配空白,我认为这是问题所在。我试过了:
-
[[:blank:]] -
[:blank:] -
[[:space:]] -
[:space:] - 和
\s方法
[:space:]应匹配所有空格,但同样的结果相同。
我尝试的任何东西似乎都没有用,你能指出我正确的方向吗?
谢谢!
1 个答案:
答案 0 :(得分:1)
Foreward
如果您使用this library
,则可以启用PCRE描述
^([0-9]{4}(?:[[:blank:]]+[a-z]{2}(?=[[:blank:]]))?)[[:blank:]](.*$)
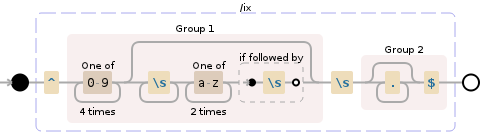
此正则表达式将执行以下操作:
- 找到4位数代码后跟可选的两个字符
- 匹配应该是城市名称 的字符串的其余部分
实施例
现场演示
https://regex101.com/r/sE3xN7/4
示例文字
请注意,您的示例只有4位数代码,因此我冒昧地添加了一个额外的数字
1111 AA CITYNAME1
2222 CITYNAME2
3333 Las Vegas
4444 BB Las Vegas
9741 NE Groningen
样本匹配
MATCH 1
1. [0-7] `1111 AA`
2. [8-17] `CITYNAME1`
MATCH 2
1. [18-22] `2222`
2. [23-32] `CITYNAME2`
MATCH 3
1. [33-37] `3333`
2. [38-47] `Las Vegas`
MATCH 4
1. [48-55] `4444 BB`
2. [56-65] `Las Vegas`
MATCH 5
1. [66-73] `9741 NE`
2. [74-83] `Groningen`
解释
NODE EXPLANATION
----------------------------------------------------------------------
^ the beginning of a "line"
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[0-9]{4} any character of: '0' to '9' (4 times)
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
[[:blank:]]+ whitespace (\n, \r, \t, \f, and " ")
(1 or more times (matching the most
amount possible))
----------------------------------------------------------------------
[a-z]{2} any character of: 'a' to 'z' (2 times)
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
[[:blank:]] whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
[[:blank:]] whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
( group and capture to \2:
----------------------------------------------------------------------
.* any character except \n (0 or more times
(matching the most amount possible))
----------------------------------------------------------------------
$ before an optional \n, and the end of a
"line"
----------------------------------------------------------------------
) end of \2
----------------------------------------------------------------------
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?