匹配正则表达式后选择下一行
我目前正在使用扫描软件" Drivve Image"从每篇论文中提取某些信息。该软件可以根据需要运行某些正则表达式代码。它似乎与UltraEdit正则表达式引擎一起运行。
我得到以下扫描结果:
1. 21Sid1
2. Ordernr
3. E17222
4. By
5. Seller
我需要在字符串中搜索文本Ordernr,然后选择以下行E17222,最后一行将是扫描文档的文件名。我永远不会知道这两个值在字符串中的确切位置。这就是我需要关注Ordernr的原因,因为我需要的文本将始终作为下一行。
我的要求是,我需要E17222才能成为匹配结果中的唯一内容。我只能输入普通正则表达式。
已经有一个很棒的主题:Regex to get the words after matching string
我已经测试过" \ bOrdernr \ s + \ K \ S + "效果很好..
不是软件不允许/ K使用。有没有其他方法可以实现\ K?
续
虽然示例文本涉及" Ordernr"目前的答案并没有达到我需要的程度。像这样的样本:
21Sid1
Ordernr 1
E17222
通过
卖方
当前的解决方案选择" 1"而不是" 下一行"这将是" E17222 "。在匹配组中。需要指出进一步参与该问题。
2 个答案:
答案 0 :(得分:19)
描述
ordernr[\r\n]+([^\r\n]+)
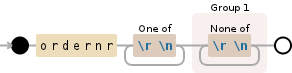
此正则表达式将执行以下操作:
- 找到
ordernr子字符串 - 将该行放在
ordernr捕获组1 之后
实施例
现场演示
https://regex101.com/r/dQ0gR6/1
示例文字
1. 21Sid1
2. Ordernr
3. E17222
4. By
5. Seller
样本匹配
[0][0] = Ordernr
3. E17222
[0][1] = 3. E17222
解释
NODE EXPLANATION
----------------------------------------------------------------------
ordernr 'ordernr'
----------------------------------------------------------------------
[\r\n]+ any character of: '\r' (carriage return),
'\n' (newline) (1 or more times (matching
the most amount possible))
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[^\r\n]+ any character except: '\r' (carriage
return), '\n' (newline) (1 or more times
(matching the most amount possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
Alternativly
要仅使用环视捕捉线条,以便ordernr不包含在捕获组0中,并适应\r和\n的所有变体
(?<=ordernr\r|ordernr\n|ordernr\r\n)[^\r\n]+
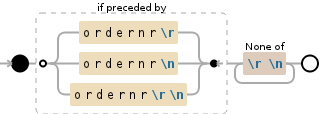
现场演示
答案 1 :(得分:3)
进行了一些谷歌搜索,从我能掌握的内容来看,REGEXP.MATCH的最后一个参数是要使用的捕获组。这意味着您可以在没有\K的情况下使用自己的正则表达式,只需将捕获组添加到要提取的数字中。
\bOrdernr\s+(\S+)
这意味着该数字最终会出现在捕获组1中(整个匹配位于0,我假设您已使用过)。
文档不是很清楚,但我猜语法是
REGEXP.MATCH(<ZoneName>, "REGEX", CaptureGroup)
意思是你应该使用
REGEXP.MATCH(<ZoneName>, "\bOrdernr\s+(\S+)", 1)
虽然这里有相当多的猜测......;)
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?