еҰӮдҪ•дҪҝз”ЁRegxиҺ·еҸ–SubsiteжҲ–QueryString
жҲ‘жңүдёҖдёӘе…ідәҺжӯЈеҲҷиЎЁиҫҫејҸзҡ„й—®йўҳпјҢд»Ҙдҫҝд»ҺзҪ‘еқҖиҺ·еҸ–дҝЎжҒҜгҖӮ
еҸҜиғҪдјҡеңЁеүҚйқўи®Ёи®әпјҢдҪҶжҲ‘жӯЈеңЁеҜ»жүҫж··еҗҲж–№жі•гҖӮ
еҰӮжһңз”ЁжҲ·иҰҒд№ҲжҸҗдҫӣеӯҗзҪ‘з«ҷпјҢиҰҒд№Ҳз”ЁжҲ·жҸҗдҫӣжҹҘиҜўеӯ—з¬ҰдёІпјҢе№¶дё”ж №жҚ®жқЎд»¶жҲ‘жғіеңЁURLиҜ·жұӮдёӯж·»еҠ 规еҲҷгҖӮ
жӯЈеҲҷиЎЁиҫҫејҸпјҡ/([^,]*)
иҫ“е…Ҙпјҡyoutube.com/data/beta
жҲ‘жӯЈеңЁиҺ·еҸ–ж•°жҚ®/жөӢиҜ•зүҲпјҢиҝҷжӯЈжҳҜжҲ‘иҰҒжүҫзҡ„гҖӮ
дҪҶжҳҜеҪ“жҲ‘е°Ҷиҫ“е…ҘдҪңдёәhttp://youtube.com/data/betaдј йҖ’ж—¶пјҢе®ғдјҡз»ҷжҲ‘/youtube..../пјҢиҝҷжҳҜжӯЈзЎ®зҡ„пјҢдҪҶжҲ‘жғіе…ҲжҺ’йҷӨ//[DomainName]гҖӮ
жіЁж„ҸпјҡжҲ‘ж— жі•еңЁyoutube.comдёҠжҺ’йҷӨпјҢеӣ дёәжҲ‘е°ҶеңЁжҹҗдәӣ规еҲҷдёӯдҪҝз”ЁжӯӨжӯЈеҲҷиЎЁиҫҫејҸпјҢеӣ жӯӨиҜ·е°ҶеӣһеӨҚжҲ–иҜ„и®әеҸ‘йҖҒз»ҷд»»дҪ•зұ»еһӢзҡ„зҪ‘еқҖгҖӮ
1 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ0)
жҸҸиҝ°
^(?:https?:\/\/)?[^\/]+\/|([^?\n]+)
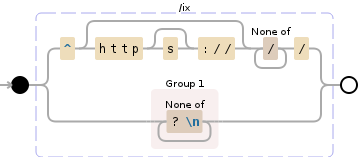
жӯӨжӯЈеҲҷиЎЁиҫҫејҸе°Ҷжү§иЎҢд»ҘдёӢж“ҚдҪңпјҡ
- еҢ№й…Қд»Ҙ
http://жҲ–https://ејҖеӨҙзҡ„еӯ—з¬ҰдёІ
- и·іиҝҮеҹҹеҗҚ
- жҚ•иҺ·еҹҹеҗҚеҗҺйқўе’ҢжҹҘиҜўеӯ—з¬ҰдёІ д№ӢеүҚзҡ„еӯҗеӯ—з¬ҰдёІ
е®һж–ҪдҫӢ
зҺ°еңәжј”зӨә
https://regex101.com/r/zC4gZ6/1
зӨәдҫӢж–Үеӯ—
youtube.com/data/beta
http://youtube.com/data/beta?Droid=This_is_not_the_droid_you_are_looking_for
ж ·жң¬еҢ№й…Қ
[1][0] = youtube.com/data/beta
[1][1] = data/beta
[2][0] = http://youtube.com/data/beta
[2][1] = data/beta
и§ЈйҮҠ
NODE EXPLANATION
----------------------------------------------------------------------
^ the beginning of a "line"
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
http 'http'
----------------------------------------------------------------------
s? 's' (optional (matching the most amount
possible))
----------------------------------------------------------------------
: ':'
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
[^\/]+ any character except: '\/' (1 or more
times (matching the most amount possible))
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[^?\n]+ any character except: '?', '\n'
(newline) (1 or more times (matching the
most amount possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
йўқеӨ–дҝЎз”Ё
иҰҒеҢ…еҗ«жҹҘиҜўеӯ—з¬ҰдёІпјҲеҰӮжһңеӯҳеңЁпјүпјҢиҜ·ж·»еҠ (?:\?(.*?))?$
еҲ°дёҠйқўзҡ„иЎЁиҫҫејҸзҡ„жң«е°ҫжүҖд»Ҙе®ғзңӢиө·жқҘеғҸиҝҷж ·гҖӮ
^(?:https?:\/\/)?[^\/]+\/([^?\n]+)(?:\?(.*?))?$

- еҰӮдҪ•иҺ·еҫ—е®Ңж•ҙзҡ„жҹҘиҜўеӯ—з¬ҰдёІжҲ–е…¶д»–йҖүйЎ№пјҹ
- еңЁasp.netдёӯиҺ·еҸ–еҹҹеҗҚе’Ң/жҲ–еӯҗз«ҷзӮ№еҗҚз§°cпјғ
- еҰӮдҪ•еңЁajaxйЎөйқўдёӯиҺ·еҸ–жҹҘиҜўеӯ—з¬ҰдёІжҲ–URLпјҹ
- еҰӮдҪ•дҪҝз”ЁRegxиҺ·еҸ–SubsiteжҲ–QueryString
- SilverstripeеӯҗзҪ‘з«ҷжЁЎеқ—пјҢеҰӮдҪ•дҪҝеӯҗзҪ‘з«ҷзү№е®ҡжҲҗе‘ҳпјҹ
- SharepointеҰӮдҪ•иҜҶеҲ«еҪ“еүҚз«ҷзӮ№жҳҜrootsiteиҝҳжҳҜеӯҗз«ҷзӮ№пјҲеӯҗз«ҷзӮ№зә§еҲ«пјүпјҹ
- е°ҶеӯҗзҪ‘з«ҷйҮҚе®ҡеҗ‘еҲ°еҸҰдёҖдёӘеӯҗзҪ‘з«ҷURL
- еҰӮдҪ•дҪҝз”ЁUmbracoд»ҺеӯҗзҪ‘з«ҷиҺ·еҸ–зҲ¶зҪ‘з«ҷеҗҚз§°
- еҰӮдҪ•дҪҝз”Ёregxд»Һеӯ—з¬ҰдёІиҺ·еҸ–ж—Ҙжңҹе’Ңж—¶й—ҙпјҹ
- дҪҝз”ЁRegxжҸҗеҸ–дҝЎжҒҜ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ