在记事本++中使用正则表达式查找十位数
我正在尝试从数据转储中替换所有内容,并使用notepad ++ regex仅保留该转储中的十位数字。
尝试做这样的事情(?<!\d)0\d{7}(?!\d),但没有运气。
3 个答案:
答案 0 :(得分:1)
试试这个:
Find: .*(\d{10}).*
Replace: \1
这已在Notepad ++中测试过。
答案 1 :(得分:1)
转发
旧版本的Notepad ++存在哪些问题无法处理PCRE表达式。这个提出的解决方案在NotePad ++ v6.8.8中进行了测试,但应该在v6.2之后的任何版本中运行。
描述
([0-9]{10})|.
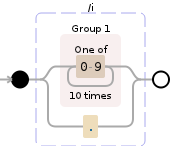
替换为:$1
此表达式将执行以下操作:
- 捕获10位数字并将它们放入捕获组1,然后将其重新插入输出字符串
- 匹配所有内容并删除它。
如何在Notepad ++中
来自Notepad ++
-
按 ctrl h 进入查找和替换 模式
-
选择正则表达式选项
-
在&#34;找到什么&#34;字段放置正则表达式
-
在&#34;替换为&#34;字段输入
$1 -
点击全部替换
实施例
现场演示
https://regex101.com/r/fZ9vH7/1
来源文字
fdsafasfa1234567890zzzzzzz12345
替换后
1234567890
解释
NODE EXPLANATION
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[0-9]{10} any character of: '0' to '9' (10 times)
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
. any character except \n
----------------------------------------------------------------------
额外信用
对于如何处理超过10个字符的数字子串,OP并不清楚。如果长度超过10位的数字字符串是不合需要的并且需要在其完整性中删除,请使用此
([0-9]{10})(?![0-9])|[0-9]+|.
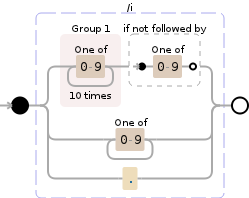
替换为:$1
答案 2 :(得分:0)
如何获取您的Facebook群组的ID列表,以避免删除活跃用户,它还用于将群组从10.000减少到5000,以及删除非活跃成员:
以及如何从HTML解析文本和代码的另一个示例。还有一个数字范围,如果是两位数,最多30位。
您可以尝试使用此方法清除member_id =的列表,并将它们与2到最多30位数字的数字一起清除。确保仅将数字和整个“ member_id = 12456”或“ member_id = 12”写入文件。以后,您可以将member_id =替换为空白。然后将整个列表复制到重复的扫描仪或删除重复的文档。并具有所有唯一的ID。然后在下面的Java代码中使用它。
“这用于在保存下来并向下滚动该组后,从单个HTML文件中清除该组中所有Facebook用户ID”
Find: (member_id=\d{2,30})|.
Replace: $1
您应该在上面的代码中使用“正则表达式”和“。匹配换行符”。
在此模式下第二次使用扩展模式:
Find: member_id=
Replace: \n
这将创建新行,并提供一种轻松的方法来删除所有行中的所有Fx0,以手动删除越野车Notepad ++中附带的所有多余字符
然后,您也可以轻松地删除所有重复项。 将所有线路连接到之间的一个空格中。 选项是使用此工具,该工具将整个文本与每个ID之间的一个空格对齐: https://www.tracemyip.org/tools/remove-duplicate-words-in-text/
然后再次“在Notepad ++中使用Normal选项”:
Find: "ONE SPACE"
Replace ','
请记住在开头和结尾添加'
然后,您可以将整行复制到Java编辑中,然后删除所有不活动的成员。如果您使用整个页面的向下滚动HTML。 ['21','234','124234'] <-从一开始就记住正确的字符。 更加安全的做法是将您的ID添加到开头。
facebook组删除Java代码在这里: https://gist.github.com/michaelv/11145168
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?