正则表达式在较大的匹配中重复捕获组?
上下文,gedit中的语法高亮。
问题:我想捕获特定区域内的所有事件。玩具示例:
other text here $5
keyword1 -> (( ran$3dom$6t:,ext$9 ))
keyword1 -> (( ran$2dom$4t:,ext$6 ))
other text here $7
我想在(( text ))的{{1}}内捕获(突出显示)$ 0-9(单个数字)次数。 (此处keyword1,$3,$6,$9,$2,$4,但不 {{1}和$6)。这归结为:如何在较大的匹配中重复捕获一个组?
我可以抓取组中可能出现的所有文本:$5(gedit默认使用\ g)
$7我找到了这个相关的问题:How can I write a regex to repeatedly capture group within a larger match?但是这个答案在后视中使用无限重复,遗憾的是,gedit不支持(据我所知)。有什么建议吗?
1 个答案:
答案 0 :(得分:0)
描述
为了确保您只处理以关键字开头的行,我将其视为两步操作。
- 收集您感兴趣的每一行
- 提取
$[0-9]子字符串 - 找到
((...))中存在的所有美元符号后跟一位数字
第1步
此正则表达式捕获类似keyword1 -> ((...))
keyword1\s*->\s*\(\(.*\)\)

第2步
\$[0-9](?![0-9])(?=(?:(?!\(\().)*\)\))
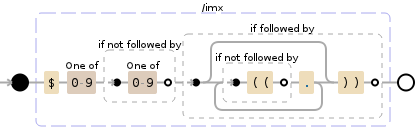
此正则表达式将执行以下操作:
实施例
现场演示
https://regex101.com/r/wY3jM6/1
示例文字
other text here $5
keyword1 -> (( ran$3dom$6t:,ext$9 ))
keyword1 -> (( ran$2dom$4t:,ext$6 ))
other text here $7
样本匹配
$3
$6
$9
$2
$4
$6
解释
NODE EXPLANATION
----------------------------------------------------------------------
\$ '$'
----------------------------------------------------------------------
[0-9] any character of: '0' to '9'
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
[0-9] any character of: '0' to '9'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
\( '('
----------------------------------------------------------------------
\( '('
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
. any character
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
\) ')'
----------------------------------------------------------------------
\) ')'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?