使用regsub捕获查询字符串左侧的值
以下是一个示例网址:
https://mydomainname.net/productimages/1679/T716AP1_lg.jpg?w=125&h=125&tstamp=05/19/2016%2015:08:30
我想要的只是:
/productimages/1679/T716AP1_lg
我目前的代码是:
regsub(req.url, "^/(.*)\.(.*)$", "\1")
在我上面的示例中有多个查询字符串参数链接之前哪个很有效,似乎&给我带来了麻烦。
2 个答案:
答案 0 :(得分:2)
尝试捕捉非点/问题:
regsub(req.url, "^http://.*?/([^?.]+).*$", "\1")
答案 1 :(得分:1)
描述
^https:\/\/[^\/]+\/([^.]*)\.jpg
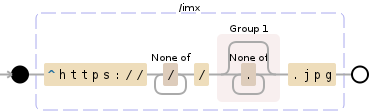
此表达式将执行以下操作:
- 从给定的链接中找到子页面和文件名,假设文件名为jpg
实施例
现场演示
https://regex101.com/r/nZ7eX7/1
示例文字
https://mydomainname.net/productimages/1679/T716AP1_lg.jpg?w=125&h=125&tstamp=05/19/2016%2015:08:30
样本匹配
productimages/1679/T716AP1_lg
解释
NODE EXPLANATION
----------------------------------------------------------------------
^ the beginning of the string
----------------------------------------------------------------------
https: 'https:'
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
[^\/]+ any character except: '\/' (1 or more
times (matching the most amount possible))
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[^.]* any character except: '.' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
\.jpg '.jpg'
----------------------------------------------------------------------
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?