使用Javascript如何从带有多个标签的html的reg表达式中删除标记
我有一个html字符串,我希望在没有<img />的情况下进行部署。目前我所拥有的是:
var myHTML = "<p><img class="alignnone size-full wp-image-2857"
src="https://files.wordpress.com/2016/05/laptop.jpg?w=750&h=545"
alt="https://pixabay.com/en/laptop-printer-office-folder-graph-1016257/"
width="750" height="545" /></p> <p>STUFF</p> <p>MORE STUFF</p> <p>EVEN MORE
STUFF</p> <p><strong><span style="text-decoration:underline;">OTHER
STUFF</span></strong></p> <p><em>OTHER STUFF</em>: DEMO STUFF</p> <p>
<em>TEST STUFF</em>: WRAP UP STUFF</p> <p><strong><span style="text-
decoration:underline;">REST OF STUFF</span></strong></p> <p><em>Aloha
POS</em>: KEEP THIS STUFF TOO</p> <p><em>Revel</em>: WHAT STUFF</p> <p>
DONE</p> "
我认为应该是这样的:
var myHTML2 = "<p></p> <p>STUFF</p> <p>MORE STUFF</p> <p>EVEN MORE
STUFF</p> <p><strong><span style="text-decoration:underline;">OTHER
STUFF</span></strong></p> <p><em>OTHER STUFF</em>: DEMO STUFF</p> <p>
<em>TEST STUFF</em>: WRAP UP STUFF</p> <p><strong><span style="text-
decoration:underline;">REST OF STUFF</span></strong></p> <p><em>Aloha
POS</em>: KEEP THIS STUFF TOO</p> <p><em>Revel</em>: WHAT STUFF</p> <p>
DONE</p> "
我尝试了什么:
myHTML.replace(/<(?!\s*\/?\s*p\b)[^>]*>/gi,'')
但是这会删除字符串中的所有html,我只想删除<img />标记。
3 个答案:
答案 0 :(得分:1)
转发
由于可能出现的所有可能模糊的边缘情况,使用正则表达式解析HTML是不明智的,但似乎您可以控制HTML,因此您应该能够避免使用许多边缘案件正义报警呐喊。
描述
<img\s(?:[^>=]|='[^']*'|="[^"]*"|=[^'"][^\s>]*)*>
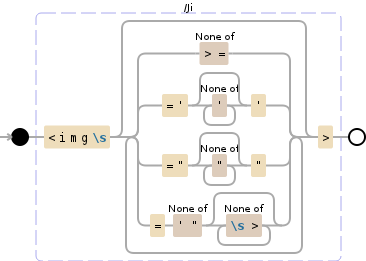
替换为: 没有
此正则表达式将执行以下操作:
- 匹配整个img标记以包含任何子属性
- 避免困难的边缘情况,使处理hmtl困难
实施例
直播演示 https://regex101.com/r/pG1oI7/1
示例字符串
<p><img class="alignnone size-full wp-image-2857"
src="https://files.wordpress.com/2016/05/laptop.jpg?w=750&h=545"
alt="https://pixabay.com/en/laptop-printer-office-folder-graph-1016257/"
width="750" height="545" /></p> <p>STUFF</p> <p>MORE STUFF</p> <p>EVEN MORE
STUFF</p> <p><strong><span style="text-decoration:underline;">OTHER
STUFF</span></strong></p> <p><em>OTHER STUFF</em>: DEMO STUFF</p> <p>
<em>TEST STUFF</em>: WRAP UP STUFF</p> <p><strong><span style="text-
decoration:underline;">REST OF STUFF</span></strong></p> <p><em>Aloha
POS</em>: KEEP THIS STUFF TOO</p> <p><em>Revel</em>: WHAT STUFF</p> <p>
DONE</p>
替换后
<p></p> <p>STUFF</p> <p>MORE STUFF</p> <p>EVEN MORE
STUFF</p> <p><strong><span style="text-decoration:underline;">OTHER
STUFF</span></strong></p> <p><em>OTHER STUFF</em>: DEMO STUFF</p> <p>
<em>TEST STUFF</em>: WRAP UP STUFF</p> <p><strong><span style="text-
decoration:underline;">REST OF STUFF</span></strong></p> <p><em>Aloha
POS</em>: KEEP THIS STUFF TOO</p> <p><em>Revel</em>: WHAT STUFF</p> <p>
DONE</p>
解释
NODE EXPLANATION
----------------------------------------------------------------------
<img '<img'
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
(?: group, but do not capture (0 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"] any character except: ''', '"'
----------------------------------------------------------------------
[^\s>]* any character except: whitespace (\n,
\r, \t, \f, and " "), '>' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
> '>'
答案 1 :(得分:1)
您可以使用此正则表达式删除img标记:
<img[^>]+>
老老实实,我不知道你要用正则表达式做什么。它并不需要复杂,唯一的正则表达式构造&#34;我必须使用的是[^>]+,它只匹配不是>的字符。
使用简单正则表达式的好处是可读性和速度。当然,如果你想考虑边缘情况(例如嵌入式JS中的误报),你应该使用HTML解析器。
答案 2 :(得分:1)
这不是正则表达式的答案,但如果您已经在使用javascript,则可以使用javascript的设计并直接操作DOM
require 'prawn'
Prawn::Document.generate("my_text.pdf") do
font('Helvetica', size: 50) do
formatted_text_box(
[{text: 'Whatever text you need to print'}],
at: [0, bounds.top],
width: 100,
height: 50,
overflow: :shrink_to_fit,
disable_wrap_by_char: true # <---- newly added in 1.2
)
end
end
如果要获得大量图像,则需要使用类或ID。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?