дҪҝз”ЁR
еҰӮдҪ•дҪҝз”ЁдёӢйқўзҡ„еҸҘеӯҗдёӯзҡ„жӯЈеҲҷиЎЁиҫҫејҸзј–еҶҷRд»Јз Ғд»ҘжҸҗеҸ–дёҺйҮ‘й’ұжҲ–зҷҫеҲҶжҜ”зӣёе…ізҡ„жүҖжңүж•°еӯ—гҖӮ Rд»Јз Ғеә”иҜҘйҖүжӢ©д»ҘдёӢеҶ…е®№пјҡ39.7 percentе’ҢзҫҺе…ғеҖјпјҢдҫӢеҰӮ$873,599е’Ң$1 millionгҖӮ
жҲ‘зҡ„зӨәдҫӢж–Үеӯ—жҳҜпјҡ
В ВиҷҪ然жүҖжңүд»·ж јеҢәй—ҙзҡ„йҖүжӢ©йғҪеҫҲдҪҺпјҢдҪҶеҜ№й«ҳз«ҜдҪҸе®…зҡ„е…ҙи¶Јд»Қ然еҫҲй«ҳпјҢ355дёӘжҲҝдә§пјҢеҚ жүҖжңүжҲҝеұӢй”Җе”®зҡ„37.6пј…пјҢеҗёеј•дәҶи¶…иҝҮ873,599зҫҺе…ғе’Ң100дёҮзҫҺе…ғзҡ„д»·ж јгҖӮ
жҲ‘е°қиҜ•дәҶд»ҘдёӢ$?[0-9,.]+Percent?Million?пјҢдҪҶиҝҷжІЎжңүжҢүйў„жңҹе·ҘдҪңгҖӮ
1 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ3)
жҸҸиҝ°
[0-9]+(?:\.[0-9]+)?\s*(?:%|percent)|\$(?:[0-9]{3},)*[0-9]+(?:\s(?:thousand|million|billion|trillion))?
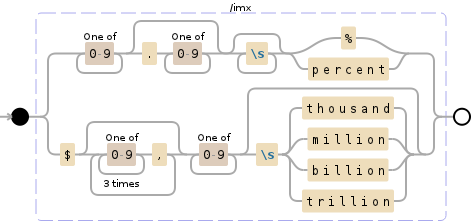
жӯӨжӯЈеҲҷиЎЁиҫҫејҸе°Ҷжү§иЎҢд»ҘдёӢж“ҚдҪңпјҡ
- жүҫеҲ°д»ЈиЎЁзҷҫеҲҶжҜ”зҡ„жүҖжңүж•°еӯ—пјҢеҢ…еҗ«жҲ–дёҚеҢ…еҗ«е°Ҹж•°зӮ№
- иҜҘж•°еӯ—еҗҺйқўеҸҜиғҪи·ҹдёҖдёӘ
%з¬ҰеҸ·жҲ–ж–Үеӯ—
- иҜҘж•°еӯ—еҗҺйқўеҸҜиғҪи·ҹдёҖдёӘ
- жүҫеҲ°жүҖжңүзҫҺе…ғйҮ‘йўқзҡ„ж•°еӯ—
- еёҰжңүйўҶе…Ҳзҡ„зҫҺе…ғз¬ҰеҸ·
- еҸҜиғҪеҢ…еҗ«йҖ—еҸ·еҲҶйҡ”з¬Ұ
- еҗҺйқўеҸҜиғҪи·ҹдёҖдёӘеҚғдёҮпјҢзҷҫдёҮпјҢеҚҒдәҝжҲ–дёҮдәҝ иҝҷж ·зҡ„иҜҚ
- йҒҝе…Қе…¶д»–йқһзҫҺе…ғжҲ–зҷҫеҲҶжҜ”ж•°еӯ—
е®һж–ҪдҫӢ
зҺ°еңәжј”зӨә
https://regex101.com/r/uG6mQ4/1
зӨәдҫӢж–Үеӯ—
В ВпјҶпјғ34;иҷҪ然100пј…д»·ж јеҢәй—ҙзҡ„йҖүжӢ©иҫғдҪҺпјҢдҪҶеҜ№й«ҳз«ҜдҪҸе®…зҡ„е…ҙи¶Јд»Қ然еҫҲй«ҳпјҢ355дёӘжҲҝдә§пјҢеҚ жүҖжңүжҲҝеұӢй”Җе”®зҡ„37.6пј…пјҢеҗёеј•дәҶи¶…иҝҮ873,599зҫҺе…ғе’Ң100дёҮзҫҺе…ғзҡ„д»·ж јгҖӮ
ж ·жң¬еҢ№й…Қ
[0][0] = 100%
[1][0] = 37.6 percent
[2][0] = $873,599
[3][0] = $1 million
и§ЈйҮҠ
NODE EXPLANATION
----------------------------------------------------------------------
[0-9]+ any character of: '0' to '9' (1 or more
times (matching the most amount possible))
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
\. '.'
----------------------------------------------------------------------
[0-9]+ any character of: '0' to '9' (1 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
\s* whitespace (\n, \r, \t, \f, and " ") (0 or
more times (matching the most amount
possible))
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
% '%'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
percent 'percent'
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\$ '$'
----------------------------------------------------------------------
(?: group, but do not capture (0 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
[0-9]{3} any character of: '0' to '9' (3 times)
----------------------------------------------------------------------
, ','
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
[0-9]+ any character of: '0' to '9' (1 or more
times (matching the most amount possible))
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
thousand 'thousand'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
million 'million'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
billion 'billion'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
trillion 'trillion'
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ