捕获所有l个字母并排除单词
我正在努力让我的正则表达式工作2个小时...但只是头疼。
我想要的是:序列中的所有“c”(不是“查询:”而不是“Sbjct:”)
Query: 1 atttatccttttggtcagaattttatatataagtattttttatttttctttggaccaaaa 60
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sbjct: 1 atttatccttttggtcagaattttatatataagtattttttatttttctttggaccaaaa 60
Query: 61 ttttatgcatcacattgtagcttttctgcaccacgccacatcacactacattttttctgt 120
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sbjct: 61 ttttatgcatcacattgtagcttttctgcaccacgccacatcacactacattttttctgt 120
我得到/\b(?:(?!Sbjct)(?!Query)\w)+(c)/g但它只捕获每一行的最后一个“c”(我想要所有“c”)。
感谢您的帮助。
3 个答案:
答案 0 :(得分:1)
我认为你的意思是你想要任何一封信' c'在行标题中发现忽略 - 即:如果' c'在结肠左侧,它被忽略但是结肠后的所有c都要被捕获。你不能准确地说出捕获的内容 - 所以这就是我所提出的;
use v5.12;
while (<>) {
say "Examining line $." ;
next unless /:/g ;
while (/ (c+) /gx) {
say " Found \"$1\" at position ", pos ;
}
}
# when fed the 8 lines above ...
Examining line 1
Found "cc" at position 19
Found "c" at position 27
Found "c" at position 59
Found "cc" at position 67
Examining line 2
Examining line 3
Found "cc" at position 19
Found "c" at position 27
Found "c" at position 59
Found "cc" at position 67
Examining line 4
Examining line 5
Examining line 6
Found "c" at position 19
Found "c" at position 22
Found "c" at position 24
Found "c" at position 32
Found "c" at position 37
Found "c" at position 40
Found "cc" at position 43
Found "c" at position 45
Found "cc" at position 48
Found "c" at position 50
Found "c" at position 53
Found "c" at position 55
Found "c" at position 57
Found "c" at position 60
Found "c" at position 68
Examining line 7
Examining line 8
Found "c" at position 19
Found "c" at position 22
Found "c" at position 24
Found "c" at position 32
Found "c" at position 37
Found "c" at position 40
Found "cc" at position 43
Found "c" at position 45
Found "cc" at position 48
Found "c" at position 50
Found "c" at position 53
Found "c" at position 55
Found "c" at position 57
Found "c" at position 60
Found "c" at position 68
请注意,对于数据行3,&#39; c&#39;未捕获位置4。
这是由于next unless /:/g行坚持&#39;:&#39;在任何“c”被采取之前。 /x打开&#34;扩展模式&#34;在正则表达式中使用空格的正则表达式更加清晰。当使用/g - 全局匹配选项时 - 可以将正则表达式置于while循环中,它将从上次成功搜索的位置开始重复搜索目标。
答案 1 :(得分:0)
描述
如果你是regex replace命令的全局选项,那么这个正则表达式将执行以下操作:
- 找到第一个
c后面的字符串中的每个:(分号后面跟一个空格) - 假设字符串 中只有一个分号和空格组合
- 捕获每个
c,以便可以替换 - 允许字符串包含多行
- 如果第一行以
expect:开头,则忽略整行上的所有c - 因为这是Javascript,所以不能使用负面的lookbehind
<强>正则表达式
匹配:((?:(?:expect:(?:(?!\r|\n).)*))?(?:(?:\r|\n|\A)+[^:]+:.*?)?)(c)
替换为:$1<span class="cystein">$2</span>
解释
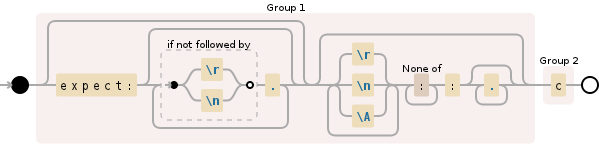
NODE EXPLANATION
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
expect: 'expect:'
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
\r '\r' (carriage return)
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\n '\n' (newline)
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
. any character
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
(?: group, but do not capture (1 or more
times (matching the most amount
possible)):
----------------------------------------------------------------------
\r '\r' (carriage return)
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\n '\n' (newline)
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\A the beginning of the string
----------------------------------------------------------------------
)+ end of grouping
----------------------------------------------------------------------
[^:]+ any character except: ':' (1 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
: ':'
----------------------------------------------------------------------
.*? any character (0 or more times
(matching the least amount possible))
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
( group and capture to \2:
----------------------------------------------------------------------
c 'c'
----------------------------------------------------------------------
) end of \2
----------------------------------------------------------------------
粗略的Javascript示例
请注意,为了便于阅读此示例,我使用$1_$2_作为替换字符串而不是$1<span class="cystein">$2</span>
<script type="text/javascript">
var re = /((?:(?:expect:(?:(?!\r|\n).)*))?(?:(?:\r|\n|\A)+[^:]+:.*?)?)(c)
/;
var sourcestring = "source string to match with pattern";
var replacementpattern = "$1_$2_";
var result = sourcestring.replace(re, replacementpattern);
alert("result = " + result);
</script>
结果字符串
请注意,为了便于阅读此示例,我使用$1_$2_作为替换字符串而不是$1<span class="cystein">$2</span>
Expect: 61 ttttatgcatcacattgtagcttttctgcaccacgccacatcacactacattttttctgt 120
Query: 61 ttttatg_c_at_c_a_c_attgtag_c_tttt_c_tg_c_a_c__c_a_c_g_c__c_a_c_at_c_a_c_a_c_ta_c_atttttt_c_tgt 120
Sbjct: 61 ttttatg_c_at_c_a_c_attgtag_c_tttt_c_tg_c_a_c__c_a_c_g_c__c_a_c_at_c_a_c_a_c_ta_c_atttttt_c_tgt 120
现场演示
答案 2 :(得分:0)
所以只是为了尝试简化一些事情而不是疯狂地向前看/在正则表达式之后,最好只用空格分割线,抓住包含DNA字符串的第n个元素然后简单
dna.replace('c', 'spanny goodness')
(抱歉。电话接听......)
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?