从div标签中提取所有数字和罗马数字
我正在使用Java和Jsoup来提取div标记的内容。我只需要提取数字。
String html = "";
Document document = Jsoup.parse(html);
Elements divs = document.select("div");
for (Element div : divs) {
System.out.println(div.ownText());
}
,输出就像这样
Adidas, 45-46 Nike, 25 shoes, phone, keyboard, 1–2, 4–5, 7, 9, 12, 13, 32, 35,
我的问题是如何提取div代码的数字内容?每个号码在需要之前都有逗号。那么如何使用正则表达式呢?谢谢
更新:如何提取数字和罗马数字?
Adidas, 45-46 Nike, 25 shoes, phone, keyboard, 1–2, 4–5, 7, 9, 12, 13, 32, 35, V, VI, IX,
此帖与上述链接不同,因为我的问题需要提取罗马数字
2 个答案:
答案 0 :(得分:0)
您可以使用此正则表达式:
\b(\d+(-\d+)?|(M{1,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})|M{0,4}(CM|C?D|D?C{1,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})|M{0,4}(CM|CD|D?C{0,3})(XC|X?L|L?X{1,3})(IX|IV|V?I{0,3})|M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|I?V|V?I{1,3})))\b
演示: https://regex101.com/r/rW1mY1/3
说明:
-
\b用于字边界。 -
(M{1,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})|M{0,4}(CM|C?D|D?C{1,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})|M{0,4}(CM|CD|D?C{0,3})(XC|X?L|L?X{1,3})(IX|IV|V?I{0,3})|M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|I?V|V?I{1,3}))这是罗马数字验证器。我从这里得到它:How do you match only valid roman numerals with a regular expression? -
\d+(-\d+)?匹配数字和可选的数字范围
答案 1 :(得分:0)
描述
此正则表达式将执行以下操作:
- 匹配所有数字字符串,例如2,3977,432,5 ..
- 匹配所有数字字符串范围,例如2-4,553-999,1234-9876
- 匹配1-4000 范围内的所有有效罗马数字
- 返回仅包含这些值的数组,而不返回其他捕获组
正则表达式
\b(?:\d+(?:-\d+)?|(?=[MCDLXVI]+\b)M{0,4}(?:CM|CD|D?C{0,3})(?:XC|XL|L?X{0,3})(?:IX|IV|V?I{0,3}))\b
请注意,这只是一个原始正则表达式,对于像Java这样的许多语言,您需要将\替换为\\才能使其正常工作。
解释
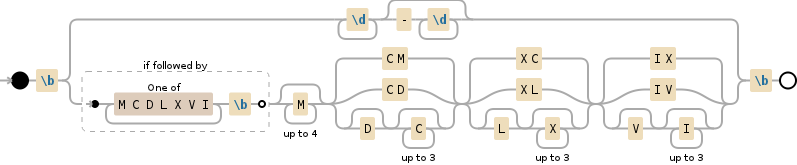
NODE EXPLANATION
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
\d+ digits (0-9) (1 or more times (matching
the most amount possible))
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
- '-'
----------------------------------------------------------------------
\d+ digits (0-9) (1 or more times
(matching the most amount possible))
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
[MCDLXVI]+ any character of: 'M', 'C', 'D', 'L',
'X', 'V', 'I' (1 or more times
(matching the most amount possible))
----------------------------------------------------------------------
\b the boundary between a word char (\w)
and something that is not a word char
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
M{0,4} 'M' (between 0 and 4 times (matching the
most amount possible))
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
CM 'CM'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
CD 'CD'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
D? 'D' (optional (matching the most
amount possible))
----------------------------------------------------------------------
C{0,3} 'C' (between 0 and 3 times (matching
the most amount possible))
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
XC 'XC'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
XL 'XL'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
L? 'L' (optional (matching the most
amount possible))
----------------------------------------------------------------------
X{0,3} 'X' (between 0 and 3 times (matching
the most amount possible))
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
IX 'IX'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
IV 'IV'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
V? 'V' (optional (matching the most
amount possible))
----------------------------------------------------------------------
I{0,3} 'I' (between 0 and 3 times (matching
the most amount possible))
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
实施例
现场演示
示例文字
Adidas, 45-46 Nike, 25 shoes, phone, keyboard, 1-2, 4-5, 7, 9, 12, 13, 32, 35, V, VI, IX
Java代码示例
import java.util.regex.Pattern;
import java.util.regex.Matcher;
class Module1{
public static void main(String[] asd){
String sourcestring = "Adidas, 45-46 Nike, 25 shoes, phone, keyboard, 1-2, 4-5, 7, 9, 12, 13, 32, 35, V, VI, IX";
Pattern re = Pattern.compile("\\b(?:\\d+(?:-\\d+)?|(?=[MCDLXVI]+\\b)M{0,4}(?:CM|CD|D?C{0,3})(?:XC|XL|L?X{0,3})(?:IX|IV|V?I{0,3}))\\b",Pattern.CASE_INSENSITIVE );
Matcher m = re.matcher(sourcestring);
int mIdx = 0;
while (m.find()){
for( int groupIdx = 0; groupIdx < m.groupCount()+1; groupIdx++ ){
System.out.println( "[" + mIdx + "][" + groupIdx + "] = " + m.group(groupIdx));
}
mIdx++;
}
}
}
匹配数组
$matches Array:
(
[0] => Array
(
[0] => 45-46
[1] => 25
[2] => 1-2
[3] => 4-5
[4] => 7
[5] => 9
[6] => 12
[7] => 13
[8] => 32
[9] => 35
[10] => V
[11] => VI
[12] => IX
)
)
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?