иҝҷйҮҢжҲ‘иҜ•еӣҫзј–еҶҷд»Һ.csvж–Ү件дёӯжҸҗеҸ–ж•°жҚ®зҡ„дёңиҘҝпјҢеңЁpythonдёӯеҲӣе»әдёҖдёӘеҲ—иЎЁеҜ№иұЎжқҘж“ҚдҪңпјҢе№¶ж №жҚ®з”ЁжҲ·иҫ“е…Ҙзҡ„еҶ…е®№пјҢд»ҘдёҚеҗҢзҡ„ж–№ејҸеҜ№е…¶иҝӣиЎҢжҺ’еәҸгҖӮзӣ®еүҚжҲ‘е·ІжҲҗеҠҹи®ҫжі•жҢүеӯ—жҜҚйЎәеәҸеҜ№еҲ—иЎЁиҝӣиЎҢжҺ’еәҸпјҢ并жҢүеҲҶж•°жҺ’еәҸпјҢдҪҶеҪ“жҲ‘е°қиҜ•жҢүе№іеқҮеҲҶж•°иҝӣиЎҢжҺ’еәҸж—¶пјҢе®ғиҝ”еӣһзҡ„з»“жһңдёҚжӯЈзЎ®гҖӮж•°жҚ®еә“csvгҖӮе®ғжң¬иә«зҡ„ж јејҸжІЎжңүвҖң姓еҗҚпјҢзұ»пјҢеҲҶж•°пјҢеҲҶж•°пјҢеҲҶж•°вҖқеҪўејҸзҡ„еҲ—ж ҮйўҳпјҢжҜҸдёӘжқЎзӣ®д№Ӣй—ҙйғҪжңүдёҖдёӘж–°иЎҢгҖӮиҝҷжҳҜжҲ‘зӣ®еүҚзҡ„д»Јз Ғпјҡ
from operator import itemgetter
import csv
with open("Scoredatabase.csv","r") as f: #opens the file in read mode so it can be read
formattedf=csv.reader(f) #creates the object from the csv. file that can be manipulated by python
NameClassScoreList = []
for line in formattedf: #Iterates through each entry in the .csv file
NameClassScoreList.append(line[0:5]) # Creates a list of all of the entries in the .csv file (List of lists) in the order Name,Class,Score,Score,Score
print("If you would like to output a sorted list..")
print("Enter 'alpha' for an alphabetical score and the student's highest score")
print("Enter 'highscore' to sort by highest score to lowest")
print("Enter 'avgscore' to sort by average score")
while True:
sortby=input()
if sortby == "alpha" or sortby == "highscore" or sortby == "avgscore":
break
else:
print("invalid input, please enter a specified sort method")
if sortby == "alpha":
NameClassScoreList = sorted(NameClassScoreList, key=itemgetter(1,0))#sorts by class, then name alphabetically
for entry in NameClassScoreList:
print("Name: " + entry[0] + " Class: " + entry[1] + " Max score: " + str(max(entry[2:5])))
if sortby == "highscore":
for entry in NameClassScoreList:
entry.append(max(entry[2:5]))
NameClassScoreList = sorted(NameClassScoreList, key = itemgetter(5))
for entry in NameClassScoreList:
print("Maximum Score: " + str(entry[5]) + " Name: " + entry[0] + " Class: " + entry[1])
if sortby == "avgscore":
for entry in NameClassScoreList:
entry.append((1/3)*int(((entry[2])+(entry[3])+(entry[4]))))
NameClassScoreList = sorted(NameClassScoreList, key = itemgetter(5))
for entry in NameClassScoreList:
print("Average score: " + str(entry[5]) + " Name: " + entry[0] + " Class: " + entry[1])
еҪ“жҲ‘жғід»ҺжңҖй«ҳеҲ°жңҖдҪҺжҳҫзӨәж—¶пјҢжӯӨд»Јз Ғдјҡд»ҺжңҖдҪҺеҲ°жңҖй«ҳиҝ”еӣһйқһеёёеҘҮжҖӘзҡ„жһҒеӨ§з»“жһңгҖӮ
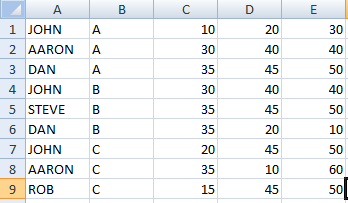
зј–иҫ‘^и®ўиҙӯй—®йўҳе·Ідҝ®еӨҚпјҢдҪҶзЁӢеәҸд»Қ然иҝ”еӣһиҚ’и°¬зҡ„еӨ§е№іеқҮз»“жһңгҖӮеҲ—иЎЁдёӯзҡ„жқЎзӣ®пјҲ.csvж–Ү件дёӯзҡ„дёҖиЎҢпјүзңӢиө·жқҘеғҸ......пјҢ[JOHNпјҢAпјҢ20,30,40]пјҢ[еҗҚз§°пјҢзұ»еҲ«пјҢеҲҶж•°1пјҢеҲҶж•°2пјҢеҲҶж•°3]
йқһеёёж„ҹи°ўжңүе…іеҰӮдҪ•дҝ®еӨҚе№іеқҮеҲҶж•°и®Ўз®—зҡ„д»»дҪ•е»әи®®пјҢи°ўи°ўгҖӮ
зј–иҫ‘пјҡзӨәдҫӢпјҡ
еңЁд»ҘдёӢcsvж–Ү件дёӯпјҡhttps://i.gyazo.com/0615f6c4ec669d5c052ed061e5e871c9.png
Pythonиҫ“еҮәиҝҷдёӘиҜ·жұӮavgscoreжҺ’еәҸпјҡ
е№іеқҮеҫ—еҲҶпјҡ118183.33333333333姓еҗҚпјҡDANзұ»еҲ«пјҡA е№іеқҮеҫ—еҲҶпјҡ118183.33333333333姓еҗҚпјҡSTEVEиҒҢдёҡпјҡB е№іеқҮеҫ—еҲҶпјҡ117336.66666666666姓еҗҚпјҡDANеҲҶзұ»пјҡB е№іеқҮеҫ—еҲҶпјҡ117020.0姓еҗҚпјҡAARONзӯүзә§пјҡC е№іеқҮеҫ—еҲҶпјҡ101346.66666666666еҗҚз§°пјҡAARONзұ»еҲ«пјҡA е№іеқҮеҫ—еҲҶпјҡ101346.66666666666姓еҗҚпјҡJOHNзҸӯзә§пјҡB е№іеқҮеҫ—еҲҶпјҡ68183.33333333333姓еҗҚпјҡJOHNзұ»еҲ«пјҡC е№іеқҮеҫ—еҲҶпјҡ51516.666666666664еҗҚз§°пјҡROBзұ»еҲ«пјҡC е№іеқҮеҫ—еҲҶпјҡ34010.0姓еҗҚпјҡJOHNзҸӯзә§пјҡA
......иҝҷжңүзӮ№еҘҮжҖӘ
зј–иҫ‘пјҡ
жҲ‘и®ҫжі•йҖҡиҝҮжӣҙж”№иЎҢ
жқҘдҝ®еӨҚд»Јз Ғ entry.append((1/3)*int(((entry[2])+(entry[3])+(entry[4]))))
еҲ°
entry.append(int((int(entry[2])+int(entry[3])+int(entry[4])) / 3))
жҲ‘жғізҹҘйҒ“дёәд»Җд№Ҳдҝ®еӨҚе®ғпјҢеӣ дёәе®ғеҜ№жҲ‘жқҘиҜҙдјјд№ҺдёҚжҳҜеҫҲжҳҺжҳҫ......
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ2)
еңЁsortedпјҡ
дёӯдҪҝз”ЁreverseйҖүйЎ№if sortby == "alpha":
NameClassScoreList = sorted(NameClassScoreList, key=itemgetter(1,0), reverse=True)
...
if sortby == "highscore":
...
NameClassScoreList = sorted(NameClassScoreList, key = itemgetter(5), reverse=True)
...
еә”иҜҘеҒҡзҡ„е·ҘдҪң
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ0)
з»ҸиҝҮеҮ еӨ©зҡ„жҖқиҖғеҗҺпјҢжҲ‘жҹҘзңӢдәҶе®ғдә§з”ҹзҡ„ж•°еӯ—пјҢжҲ‘зӣёдҝЎе®ғзӯүдәҺжүҖжңүеҲҶж•°зҡ„дёүеҲҶд№ӢдёҖпјҢиҝһеңЁдёҖиө·иҖҢдёҚжҳҜеҠ еңЁдёҖиө·гҖӮе®һйҷ…дёҠпјҢе°ҶжҜҸдёӘжқЎзӣ®иҪ¬жҚўдёәж•ҙж•°еҸҜд»Ҙи§ЈеҶій—®йўҳпјҢжҲ‘жғіиҝҷжҳҜвҖңжңҖеӨ§жҜ”еҲҶвҖқгҖӮжҺ’еәҸж–№жі•жңүж•ҲпјҢеӣ дёәпјҶпјғ39; maxпјҶпјғ39;еҮҪж•°еҝ…йЎ»еңЁжҲ‘дёҚзҹҘжғ…зҡ„жғ…еҶөдёӢе°Ҷеӯ—з¬ҰдёІйҡҗејҸиҪ¬жҚўдёәж•°еӯ—гҖӮ
{kind=link}