找到不被alpha char包围的单词
经过一些搜索后,这似乎比我想象的要困难:我正在尝试用Python编写一个正则表达式来查找一个没有被其他字母或破折号包围的单词。
在以下示例中,我尝试匹配ios:
- 好像是carpedios
- 我喜欢“ios”,因为他们有蓝色产品
- 我喜欢carpedios和ios
- 我喜欢carpedios和ios。
- 我喜欢carped-ios
- 1:不匹配,因为
ios位于d之后。 - 2:匹配,因为
ios未被字母包围。 - 3:匹配,因为
ios中的一个未被字母包围。 - 4:匹配,因为
ios中的一个未被字母包围。 - 5:不匹配,因为
ios后跟-。
比赛应如下:
如何使用正则表达式?
3 个答案:
答案 0 :(得分:5)
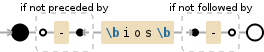
答案 1 :(得分:1)
您可以使用\b匹配单词开头或结尾的空字符串。
但是,要禁止-,我们必须使用包含的字符类
两者,然后反转它。这看起来像这样:
[^\b-]
让我们挑选一下。 []是字符类本身。 ^一开始
说要反转匹配,所以只有不在字符类中的字符
比赛。请注意-必须在字符类中持续(或者可能是第一个),
否则会被误认为是一个范围。 (这允许你说[0-9a-fA-F]为
所有十六进制的简写。)
我们来试试吧!这是您的测试文件:
$ cat t.txt
It seems carpedios
I like "ios" because they have blue products
I like carpedios and ios
I like carpedios and ios.
i like carped-ios
让我们使用上面的字符类组合我们的模式:
$ grep '[^\b-]ios[^\b-]' t.txt
I like "ios" because they have blue products
I like carpedios and ios
I like carpedios and ios.
希望这有帮助!
更新:我注意到有一个很好的替代答案,但我希望这会增加一些额外的解释。
答案 2 :(得分:-1)
类似于:[^a-zA-Z\-](ios)[^a-zA-Z\-]
然而,在行的开头或结尾可能会出现问题
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?