PHPжӯЈеҲҷиЎЁиҫҫејҸеҸӘжҸҗеҸ–дёҚеҗҢеӯ—з¬ҰдёІзҡ„йғЁеҲҶ
жҲ‘зҹҘйҒ“StackoverflowдёҠжңүеҫҲеӨҡжӯЈеҲҷиЎЁиҫҫејҸй—®йўҳпјҢжҲ‘дёҖж¬ЎеҸҲдёҖж¬Ўең°з ”究дәҶжҲ‘зҡ„д»Јз ҒпјҢдҪҶдҪңдёәжӯЈеҲҷиЎЁиҫҫејҸе’ҢPHPзҡ„ж–°жүӢпјҢжҲ‘еҸӘжҳҜдёҚжҳҺзҷҪгҖӮжҲ‘жңүдёҖдёӘж–Ү件еҗҚеҲ—иЎЁпјҢеҰӮ
В В1000032842_WMN_2150_cv.pdf
В В В В1000041148_BKO_111_SY_bj.pdf
В В В В000048316_ED_3100_AMW_2_a.pdf
В В В В1000041231_HF_210_WPO_cr.pdf
жҲ‘жӯЈеңЁе°қиҜ•д»…жҸҗеҸ–жңҖеҗҺдёҖдёӘе°ҸеҶҷеӯ—з¬Ұпјҡ cv пјҢ bj пјҢ a пјҢ cr
жҲ‘жӯЈеңЁдҪҝз”Ёд»ҘдёӢжӯЈеҲҷиЎЁиҫҫејҸе°қиҜ•жү§иЎҢжӯӨж“ҚдҪңпјҡ[a-z.]+$
1пјүжӯЈеҲҷиЎЁиҫҫејҸжҳҜеҗҰжӯЈзЎ®пјҹ
2пјүд»Җд№ҲжҳҜжӯЈзЎ®зҡ„PHPеҮҪж•°з”ЁдәҺйўқеӨ–зҡ„иҝҷдәӣеӯ—з¬ҰдёІзҡ„дёҖйғЁеҲҶпјҹ
жҲ‘дҪҝз”ЁдәҶpreg_matchпјҢpreg_splitпјҢдҪҶжҲ‘дёҚзЎ®е®ҡеә”иҜҘдҪҝз”Ёе“ӘдёҖдёӘгҖӮжҲ‘ THINK preg_splitжҳҜжӯЈзЎ®зҡ„еҠҹиғҪгҖӮ
$url = "1000036112_GKV_35_VM_32_a.pdf";
$url = preg_split('/[a-z.]+$/', $url);
print_r ($url);
дҪҶ [1] дёәз©әгҖӮ
Array ( [0] => 1000036112_GKV_35_VM_32_ [1] => )
жӣҙж–°зј–иҫ‘
д»ҘдёӢз»ҷеҮәдәҶint 0пјҢint 1зӯүзҡ„еҲ—иЎЁ
<?php
$filename = "urls.csv";
$handle = fopen($filename, "r");
if ($handle !== FALSE) {
while (($data=fgetcsv($handle,99999,',')) !== FALSE) {
$url = $data[1];
var_dump (preg_match_all('/_([a-z]{1,2})\./', $url));
}
}
?>
3 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ2)
иҜ•иҜ•иҝҷдёӘпјҡ
[a-z]+(?=\.pdf)
е…¶дёӯ(?=\.pdf)жҳҜпјҶпјғ34; lookaheadпјҶпјғ34;жӯЈеҲҷиЎЁиҫҫејҸпјҢеҹәжң¬дёҠйҖүжӢ©дёҖдёӘжҲ–еӨҡдёӘеӯ—жҜҚ[a-z]пјҢеҰӮжһң .pdf д№ӢеҗҺ
еҰӮжһңжӮЁеңЁ .pdf ж—Ғиҫ№жңүе…¶д»–жү©еұ•еҗҚпјҢйӮЈд№ҲиҜ·дҪҝз”ЁжӯӨжӯЈеҲҷиЎЁиҫҫејҸпјҢиҜҘжӯЈеҲҷиЎЁиҫҫејҸе°ҶдҪҝз”ЁеүҚзһ»е’ҢеҗҺеӨҮжқҘжҠ“еҸ–д»Ҙ _ејҖеӨҙзҡ„еӯ—з¬ҰдёІеҗҺи·ҹдёҖдёӘзӮ№ .
(?<=_)[a-z]+(?=\.)
дҪҝз”ЁPHPиҺ·еҸ–жүҖйңҖзҡ„еӯ—з¬ҰдёІпјҡ
PHP Fiddle - зӮ№еҮ»пјҶпјғ34;иҝҗиЎҢпјҶпјғ34; жҲ– F9 д»ҘжҹҘзңӢз»“жһң
$urls = array('1000032842_WMN_2150_cv.pdf', '1000041148_BKO_111_SY_bj.pdf', '000048316_ED_3100_AMW_2_a.pdf', '1000041231_HF_210_WPO_cr.pdf');
foreach($urls as $url) {
if (preg_match('/(?<=_)[a-z]+(?=\.)/i', $url, $match)) {
echo $match[0].'<br>';
}
}
иҫ“еҮәпјҡ
В ВCV
В В BJ
В В дёҖдёӘ
В В CR
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ1)
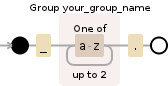
Regex
_(?<your_group_name>[a-z]{1,2})\.
PHP
<?php
$matches = array();
preg_match_all(
'/_([a-z]{1,2})\./',
"1000032842_WMN_2150_cv.pdf
1000041148_BKO_111_SY_bj.pdf
000048316_ED_3100_AMW_2_a.pdf
1000041231_HF_210_WPO_cr.pdf",
$matches
);
var_dump($matches);
?>
з»“жһң
array(2) {
[0]=>
array(4) {
[0]=>
string(4) "_cv."
[1]=>
string(4) "_bj."
[2]=>
string(3) "_a."
[3]=>
string(4) "_cr."
}
[1]=>
array(4) {
[0]=>
string(2) "cv"
[1]=>
string(2) "bj"
[2]=>
string(1) "a"
[3]=>
string(2) "cr"
}
}
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ1)
иҷҪ然дҪ е·Із»ҸжҺҘеҸ—дәҶзӯ”жЎҲпјҢдҪҶдёәд»Җд№ҲдёҚжҸҗеҮә......е°ұеғҸиҝҷж ·з®ҖеҚ•пјҡ
:еҜ№дәҺжӮЁзҡ„д»Јз ҒпјҢиҝҷе°ҶеҪ’з»“дёәпјҡ
Map/mapplyиҜ·еҸӮйҳ…a demo on regex101.comгҖӮ
- жҸҗеҸ–ж•°з»„йғЁеҲҶзҡ„еҝ«йҖҹж–№жі•пјҹ
- жӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–йғЁеҲҶж–Ү件еҗҚ
- еҰӮжһңеңЁPythonдёӯдҪҝз”ЁRegexпјҢеҲҷжҸҗеҸ–йғЁеҲҶж–Үжң¬
- д»…жҸҗеҸ–第дёҖж¬ЎеҮәзҺ°зҡ„еӯ—з¬ҰдёІ
- жӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–зү№е®ҡеӯ—з¬ҰдёІд№Ӣй—ҙзҡ„иЎҢ
- еҰӮдҪ•еңЁStataдёӯд»…жҸҗеҸ–еӯ—з¬ҰдёІзҡ„еӨ§еҶҷйғЁеҲҶпјҹ
- PHPжӯЈеҲҷиЎЁиҫҫејҸеҸӘжҸҗеҸ–дёҚеҗҢеӯ—з¬ҰдёІзҡ„йғЁеҲҶ
- PhpпјҡжӯЈеҲҷиЎЁиҫҫејҸ - еҰӮдҪ•жҸҗеҸ–еҢ№й…Қзҡ„еӨҡдёӘйғЁеҲҶ并е°Ҷе…¶еӯҳеӮЁеңЁж•°з»„дёӯпјҹ
- R - жҸҗеҸ–еҢ№й…Қе’ҢйқһеҢ№й…Қеӯ—з¬ҰдёІзҡ„йғЁеҲҶ
- д»ҺJavaScriptдёӯдёҚеҗҢж јејҸзҡ„еӯ—з¬ҰдёІдёӯд»…жҸҗеҸ–е№ҙд»Ҫ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ